Running PyTorch on GPUs
This summary of steps to run the PyTorch framework or any AI workload on GPUs highlights the importance of the hardware, driver, software, and frameworks.
Join the DZone community and get the full member experience.
Join For FreeRunning an AI workload on a GPU machine requires the installation of kernel drivers and user space libraries from GPU vendors such as AMD and NVIDIA. Once the driver and software are installed, to use AI frameworks such as PyTorch and TensorFlow, one needs to use the proper framework built against the GPU target. Usually, the AI applications run on top of popular AI frameworks and as such hide the tedious installation steps. This article highlights the importance of the hardware, driver, software, and frameworks for running AI applications or workloads.
This article deals with the Linux operating system, ROCm software stack for AMD GPU, CUDA software stack for NVIDIA GPU, and PyTorch for AI frameworks. Docker plays a critical part in bringing up the entire stack allowing the launch of various workloads in parallel.
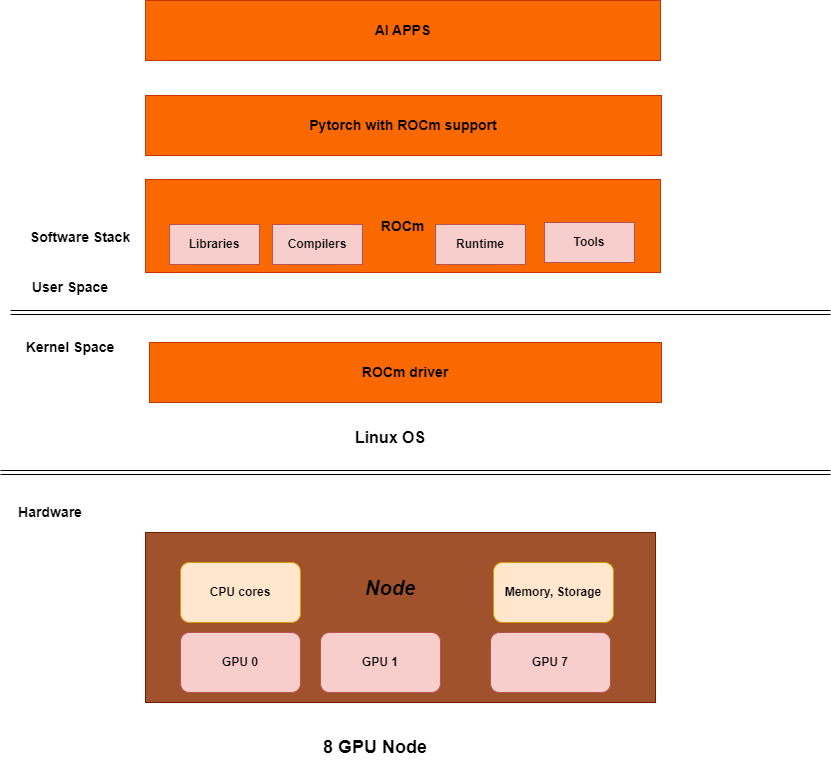
The above diagram represents the AI software stack on an 8*AMD GPU node.
The hardware layer consists of a node with the usual CPU, memory, etc. + the GPU devices. A node can have a single GPU device. Bigger AI models require a lot of GPU memory to load, and hence, it is common to use more than one GPU in a node. The GPUs are interconnected through XGMI and NVLink. A cluster will have multiple such nodes and GPUs on one node can interact with GPUs on another node. This interconnect is typically through InfiniBand, Ethernet/ROCe. The GPU interconnect to be used depends upon the underlying GPU hardware.
Installation of Kernel Driver
On the software layer, the AMD GPU driver or NVIDIA GPU driver needs to be installed. It is not uncommon to install the entire ROCm or CUDA software package on the native host OS which includes the kernel driver. Since we are going to use a Docker container to launch the AI workload, the user space ROCm or CUDA software is redundant on the native host OS; but this allows us to test if the underlying kernel driver works well or not through the user space tools.
- To install ROCm, see "ROCm installation for Linux."
- To install only the kernel driver and skip the ROCm userspace bits, see "Installation via AMDGPU installer" - refer to
dkms(to only install the kernel mode driver). - To install the NVIDIA driver, see "CUDA Toolkit 12.6 Downloads."
- To verify if the driver installation is correct, use
rocm-smiornvidia-smi(if user space bits are also installed).
Launching ROCm or CUDA-Based Docker Container
Once the GPU drivers are installed, ROCm or CUDA-based Docker images can be used respectively for AMD and NVIDIA GPU nodes.
Various Linux-flavor Docker images are released periodically by AMD and NVIDIA. This is one of the advantages of Dockerized applications instead of running applications on a native OS. We can have Ubuntu 22.04 host OS with GPU drivers installed and then launch Centos, Ubuntu 20.04-based Docker containers with different ROCm versions in parallel.
Launching ROCm-Based Docker Container
ROCm Docker images are available here. Check for dev-ubuntu-22.04 here.
docker run -it --rm --device /dev/kfd --device /dev/dri --security-opt seccomp=unconfined rocm/dev-ubuntu-22.04The above command maps all the GPU devices to the container. You can also access specific GPUs (more info at "Running ROCm Docker containers").
Once the container is running, check if GPUs are listed.
root@node:/# rocm-smiYou can download the PyTorch code and build it for AMD GPU. More instructions on GitHub or you can run any workload that has ROCm support.
Launching ROCm-Based PyTorch Docker Container
If PyTorch is not required to be built from the source (in most cases, it's not required to build the PyTorch from the source), one can directly download the ROCm based PyTorch Docker image. Just make sure the ROcm kernel drivers are installed and then launch the PyTorch-based containers.
PyTorch with ROCm support Docker images can be found here.
docker run -it --rm --device /dev/kfd --device /dev/dri --security-opt seccomp=unconfined rocm/pytorchOnce the container is running, check if GPUs are listed as described earlier.
Let's try a few code snippets from the PyTorch framework to check GPUs, ROCm/hip version, etc.
root@node:/var/lib/jenkins# python3
Python 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.__version__
'2.1.2+git70dfd51'
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
8
>>> torch.version.hip
'6.1.40091-a8dbc0c19'Conclusion
In conclusion, this article highlights the importance of software stack compatibility with the underlying GPU hardware. A wrong selection of software stack on a particular GPU type might lead to the usage of the default device (i.e., CPU), thereby underutilizing compute power of the GPU.
Happy GPU programming!
Opinions expressed by DZone contributors are their own.
Comments