Running AWS Lambda Functions in AWS CodePipeline Using CloudFormation
Recently, AWS announced that they’ve added support for triggering AWS Lambda functions into AWS CodePipeline–AWS’ Continuous Delivery service. In this article, I’ll describe how I codified the provisioning of all of the AWS resources in the documentation using CloudFormation.
Join the DZone community and get the full member experience.
Join For Freerecently, aws announced that they’ve added support for triggering aws lambda functions into aws codepipeline –aws’ continuous delivery service. they also provided some great step-by-step documentation to describe the process for configuring a new stage in codepipeline to run a lambda function. in this article, i’ll describe how i codified the provisioning of all of the aws resources in the documentation using cloudformation .
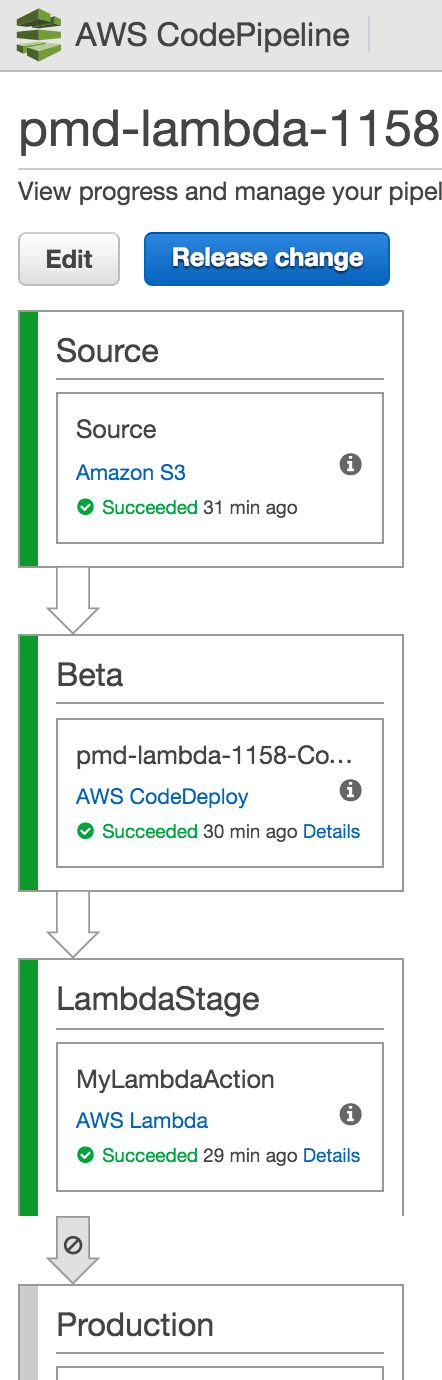
this announcement is really big news as it opens up a whole realm of possibilities about what can be run from codepipeline. now, you can run event-driven functions any time you want from your pipelines. with this addition, codepipeline added a new invoke action category that adds to the list of other actions such as build, deploy, test and source.
note: all of the cloudformation examples in this article are defined in the codepipeline-lambda.json file.
tl;dr
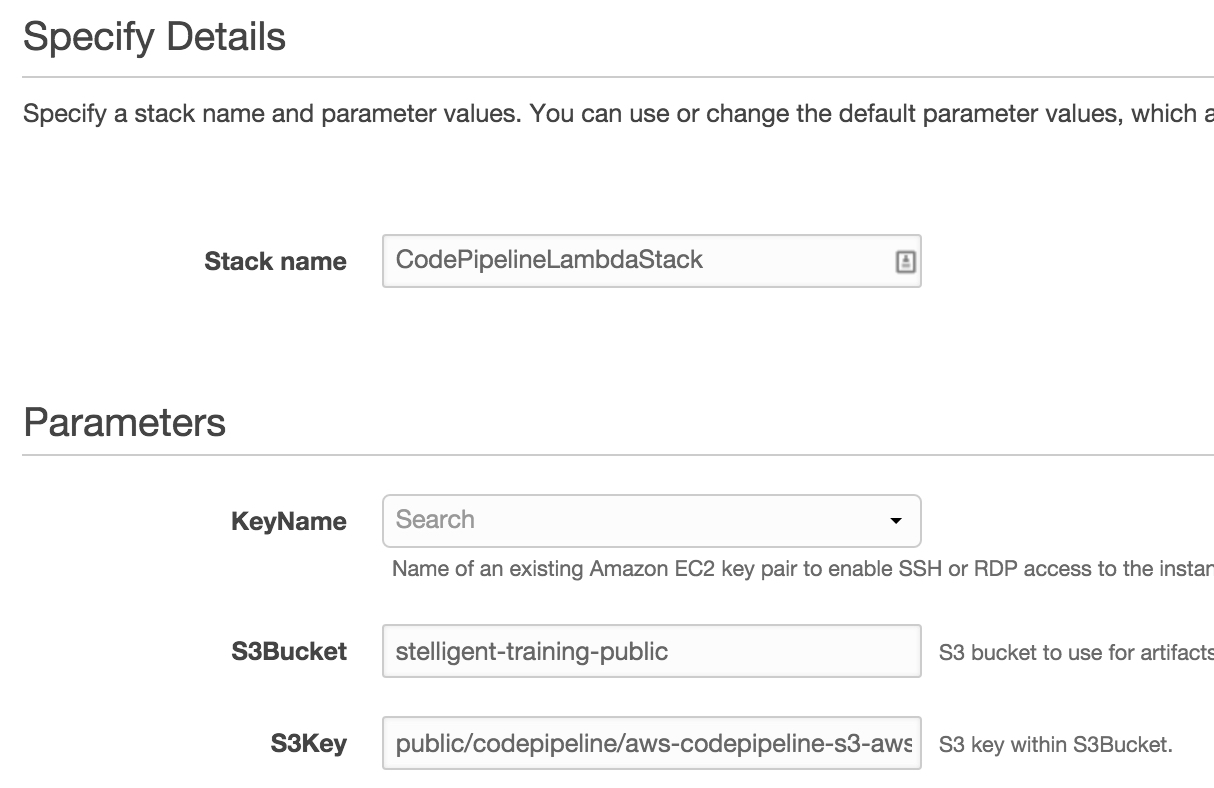 if you’d rather not read the detailed explanation of the resources and code snippets of this solution, just click on the cloudformation launch stack button below to automatically provision the aws resources described herein. you will be charged for your aws usage.
if you’d rather not read the detailed explanation of the resources and code snippets of this solution, just click on the cloudformation launch stack button below to automatically provision the aws resources described herein. you will be charged for your aws usage.

cloudformation
i went through the 20+ pages of instructions which were easy to follow but, as i often do when going through this kind of documentation, i thought about how i’d make it easier for me and others to run it again without copying/pasting, clicking multiple buttons, and so on. in other words, i’m lazy and don’t enjoy repeatedly going over the same thing again and again and i figured this would be something i’d (and others) like to use often in the future. of course, this leads me to write a template in cloudformation since i can define everything in code and type a single command or click a button to reliably and repeatedly provision all the necessary resources to run invoke actions within a lambda stage in codepipeline.
there are six core services that compose this infrastructure architecture. they are cloudformation, codepipeline, lambda, iam, ec2, and codedeploy.
to launch the infrastructure stacks that make up this solution, type the following from the command line. the command will only work if you’ve installed the aws cli .
command for launching codepipeline lambda stacks:
aws cloudformation create-stack \
--stack-name codepipelinelambdastack \
--template-body https://raw.githubusercontent.com/stelligent/stelligent_commons/master/cloudformation/codepipeline-lambda.json \
--region us-east-1 \
--disable-rollback --capabilities="capability_iam" \
--parameters parameterkey=keyname,parametervalue=yourec2keypairnameec2
from my cloudformation template, i launched a single ec2 instance that installed a codedeploy agent onto it. i used the sample provided by aws at
http://s3.amazonaws.com/aws-codedeploy-us-east-1/templates/latest/codedeploy_samplecf_template.json
and added one small modification to return the
publicip
of the ec2 instance after it’s launched as a cloudformation output. because of this modification, i created a new template based on aws’ sample.
cloudformation json to define ec2 instance used by codedeploy :
"codedeployec2instancesstack":{
"type":"aws::cloudformation::stack",
"properties":{
"templateurl":"https://s3.amazonaws.com/stelligent-training-public/public/codedeploy/codedeploy-ec2.json",
"timeoutinminutes":"60",
"parameters":{
"tagvalue":{
"ref":"aws::stackname"
},
"keypairname":{
"ref":"ec2keypairname"
}
}
}
},
when the stack is complete, you’ll see that one ec2 instance has been launched and automatically tagged with the name you entered when naming your cloudformation stack. this name is used to run codedeploy operations on instance(s) with this tag.

codedeploy
aws codedeploy automates code deployments to any instance. previously, i had automated the steps of the
simple pipeline walkthrough
which included the provisioning of aws codedeploy resources as well, so i used this cloudformation template as a starting point. i uploaded the sample linux app provided by codepipeline in the walkthrough to amazon s3 and used s3 as the source action in the source stage in my pipeline in codepipeline. below, you see a snippet of defining the codedeploy stack from the
codepipeline-lambda.json
. the nested stack defined in the
templateurl
property defines the codedeploy application and the deployment group.
cloudformation json to define ec2 instance used by codedeploy :
"codedeploysimplestack":{
"type":"aws::cloudformation::stack",
"dependson":"codedeployec2instancesstack",
"properties":{
"templateurl":"https://s3.amazonaws.com/stelligent-training-public/public/codedeploy/codedeploy-deployment.json",
"timeoutinminutes":"60",
"parameters":{
"tagvalue":{
"ref":"aws::stackname"
},
"rolearn":{
"fn::getatt":[
"codedeployec2instancesstack",
"outputs.codedeploytrustrolearn"
]
},
"bucket":{
"ref":"s3bucket"
},
"key":{
"ref":"s3key"
}
}
}
},
the screenshot below is that of a codedeploy deployment that was generated from the cloudformation stack launch.
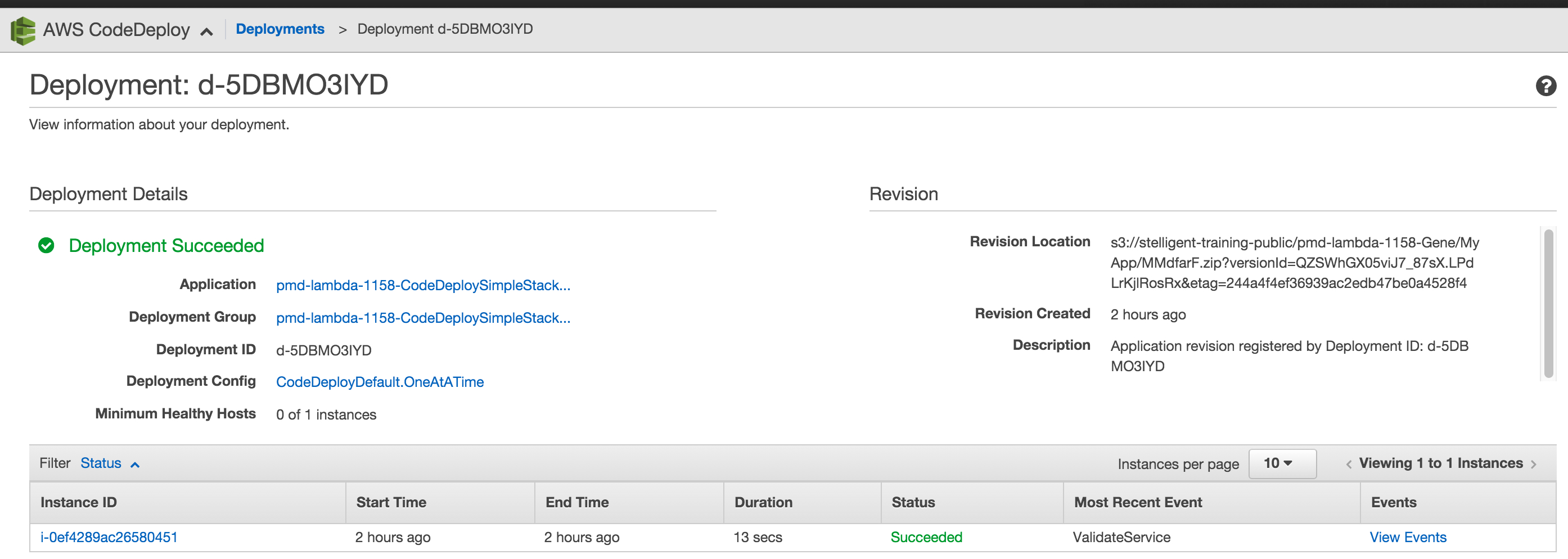
the codedeploy provisioning of this is described in more detail in my article on this topic: automating aws codedeploy provisioning in cloudformation .
codepipeline
i took a codepipeline example that i’d written in cloudformation that defines a simple three-stage pipeline (based on the simple pipeline walkthrough ) and added a new stage in the cloudformation resource block to invoke the lambda function. if i were manually adding this stage, i’d go to my specific pipeline in aws codepipeline, click add stage, and then add an action to the stage. below, you see of a screenshot of what you’d do if you were manually defining this configuration within an aws codepipeline action. this is also what got generated from the cloudformation stack.
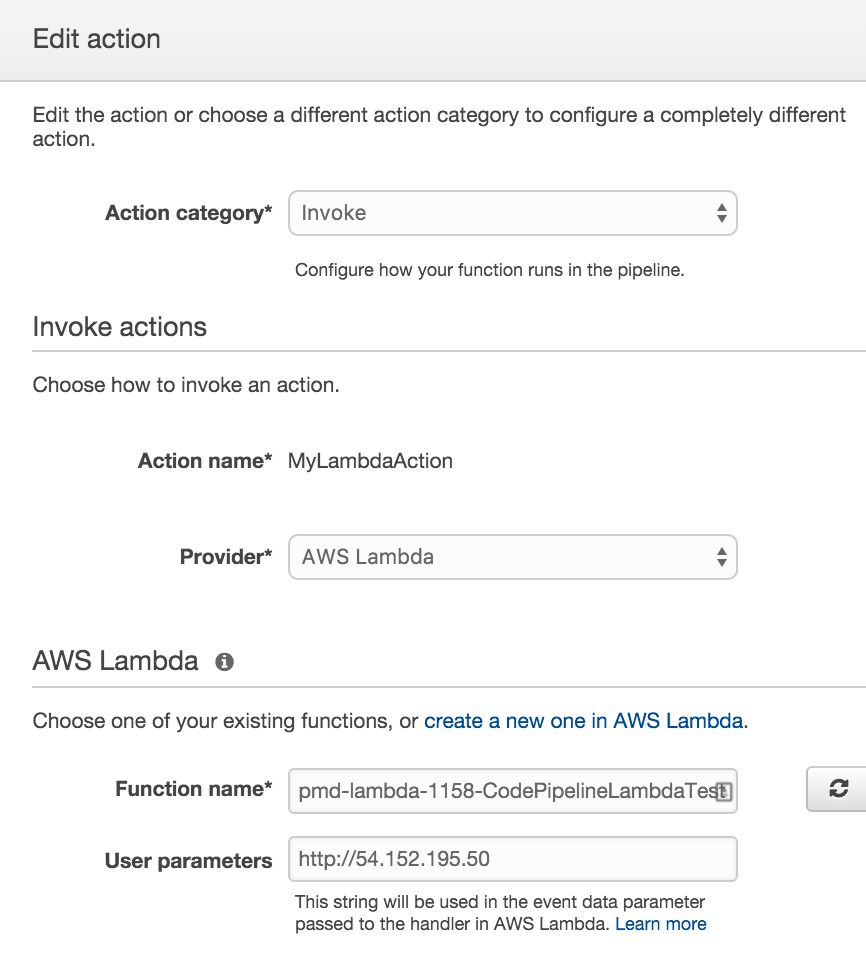
aws::codepipeline::pipeline
at the beginning of the snippet below, you see the use of the aws::codepipeline::pipeline cloudformation resource type. it has dependencies on the codedeploysimplestack and codepipelinelambdatest. one of the reasons for this is that there needs to be an ec2 instance type defined already so that i can get access to the
publicip
that i use to run a lambda function later when verifying the application is up and running. the other is that we need to set the
functionname
property of the configuration of the lambda stage in codepipeline. this function name is generated by the
aws::lambda::function
resource type that i’ll describe later. by using this approach, you don’t need to know the name of the lambda function when defining the cloudformation template.
cloudformation json to define iam role for lambda function execution :
"genericpipeline":{
"type":"aws::codepipeline::pipeline",
"dependson":[
"codedeploysimplestack",
"codepipelinelambdatest"
],
"properties":{
"disableinboundstagetransitions":[
{
"reason":"demonstration",
"stagename":"production"
}
],
"rolearn":{
"fn::join":[
"",
[
"arn:aws:iam::",
{
"ref":"aws::accountid"
},
":role/aws-codepipeline-service"
]
]
},
"stages":[
...
{
"name":"lambdastage",
"actions":[
{
"inputartifacts":[
],
"name":"mylambdaaction",
"actiontypeid":{
"category":"invoke",
"owner":"aws",
"version":"1",
"provider":"lambda"
},
"outputartifacts":[
],
"configuration":{
"functionname":{
"ref":"codepipelinelambdatest"
},
"userparameters":{
"fn::join":[
"",
[
"http://",
{
"fn::getatt":[
"codedeployec2instancesstack",
"outputs.publicip"
]
}
]
]
}
},
"runorder":1
}
]
},...lambda
aws lambda lets you run event-based functions without provisioning or managing servers. that said, there’s still a decent amount of configuration you’ll need to define in running your lambda functions. in the example provided by aws, the lambda function tests whether it can access a website without receiving an error. if it succeeds, the codepipeline action and stage succeed, turn to green, and it automatically transitions to the next stage or completes the pipeline. if it fails, that pipeline instance fails, turns red, and ceases any further actions from occurring. it’s a very typical test you’d run to be sure your application was successfully deployed. in the example, aws has you manually enter the url for the application. since this requires manual intervention, i needed to figure out a way to get this url dynamically. i did this by setting the
publicip
of the ec2 instance that was launched earlier in the stack as an output of the nested stack. then i used this
publicip
as an input to the
userparameters
property of the invoke action within the lambda stage that i defined in cloudformation for my codepipeline pipeline.
once the function has been generated by the stack, you’ll be able to go to a list of lambda functions in your aws console and see the function that was created from the stack.

aws::iam::role
in the cloudformation code snippet you see below, i’m defining an iam role that’s capable of calling lambda functions.
cloudformation json to define iam role for lambda function execution :
"codepipelinelambdarole":{
"type":"aws::iam::role",
"properties":{
"assumerolepolicydocument":{
"version":"2012-10-17",
"statement":[
{
"effect":"allow",
"principal":{
"service":[
"lambda.amazonaws.com"
]
},
"action":[
"sts:assumerole"
]
}
]
},
"path":"/"
}
},aws::iam::policy
the code snippet below depends on the creation of the iam role i showed in the example above. the iam policy that’s attached to the iam role provides access to the aws logs and the codepipeline results so that it can signal success or failure to the codepipeline action that i defined earlier.
cloudformation json to define iam policy for iam role for lambda function execution :
"lambdacodepipelineexecutionpolicy":{
"dependson":[
"codepipelinelambdarole"
],
"type":"aws::iam::policy",
"properties":{
"policyname":"lambdarolepolicy",
"roles":[
{
"ref":"codepipelinelambdarole"
}
],
"policydocument":{
"version":"2012-10-17",
"statement":[
{
"effect":"allow",
"action":[
"logs:*"
],
"resource":[
"arn:aws:logs:*:*:*"
]
},
{
"effect":"allow",
"action":[
"codepipeline:putjobsuccessresult",
"codepipeline:putjobfailureresult"
],
"resource":[
"*"
]
}
]
}
}
},aws::lambda::function
in the code snippet below, you see how i’m defining the lambda function in cloudformation. there are several things to point out here. i uploaded some javascript (node.js) code to s3 with the name
archive.zip
into a bucket specific by the s3bucket parameter that i set when i launched the cloudformation stack. this s3 bucket needs to have
s3 versioning
enabled on it. moreover, the
archive.zip
file needs to have the
.js
file used by lambda in the
root
of the
archive.zip
. keep in mind that i can call the .zip file whatever i want, but once i name the file and upload it then my cloudformation template needs to refer to the correct name of the file.
also, you see that i’ve defined a handler named
validateurl.handler
. this means that the javascript file in the archive.zip that hosts the file(s) that lambda runs must be named
validateurl.js
. if i want to use a different name, i must change both the javascript filename and the cloudformation template that references it.
cloudformation json to define lambda function execution :
"codepipelinelambdatest":{
"type":"aws::lambda::function",
"dependson":[
"codepipelinelambdarole",
"lambdacodepipelineexecutionpolicy"
],
"properties":{
"code":{
"s3bucket":{
"ref":"s3bucket"
},
"s3key":"archive.zip"
},
"role":{
"fn::getatt":[
"codepipelinelambdarole",
"arn"
]
},
"description":"validate a website url",
"timeout":20,
"handler":"validateurl.handler",
"runtime":"nodejs",
"memorysize":128
}
},lambda test function
with all of this configuration to get something to run, sometimes it’s easy to overlook that we’re actually executing something useful and not just configuring the support infrastructure. the snippet below is the actual test that gets run as part of the lambda action in the lambda stage that i defined in the cloudformation template for codepipeline. this code is taken directly from the integrate aws lambda functions into pipelines in aws codepipeline instructions from aws. this javascript code verifies that it can access the supplied website url of the deployed application. if it fails, it signals for codepipeline to cease any further actions in the pipeline.
javascript to test access to a website :
var assert = require('assert');
var aws = require('aws-sdk');
var http = require('http');
exports.handler = function(event, context) {
var codepipeline = new aws.codepipeline();
// retrieve the job id from the lambda action
var jobid = event["codepipeline.job"].id;
// retrieve the value of userparameters from the lambda action configuration in aws codepipeline, in this case a url which will be
// health checked by this function.
var url = event["codepipeline.job"].data.actionconfiguration.configuration.userparameters;
// notify aws codepipeline of a successful job
var putjobsuccess = function(message) {
var params = {
jobid: jobid
};
codepipeline.putjobsuccessresult(params, function(err, data) {
if(err) {
context.fail(err);
} else {
context.succeed(message);
}
});
};
// notify aws codepipeline of a failed job
var putjobfailure = function(message) {
var params = {
jobid: jobid,
failuredetails: {
message: json.stringify(message),
type: 'jobfailed',
externalexecutionid: context.invokeid
}
};
codepipeline.putjobfailureresult(params, function(err, data) {
context.fail(message);
});
};
// validate the url passed in userparameters
if(!url || url.indexof('http://') === -1) {
putjobfailure('the userparameters field must contain a valid url address to test, including http:// or https://');
return;
}
// helper function to make a http get request to the page.
// the helper will test the response and succeed or fail the job accordingly
var getpage = function(url, callback) {
var pageobject = {
body: '',
statuscode: 0,
contains: function(search) {
return this.body.indexof(search) > -1;
}
};
http.get(url, function(response) {
pageobject.body = '';
pageobject.statuscode = response.statuscode;
response.on('data', function (chunk) {
pageobject.body += chunk;
});
response.on('end', function () {
callback(pageobject);
});
response.resume();
}).on('error', function(error) {
// fail the job if our request failed
putjobfailure(error);
});
};
getpage(url, function(returnedpage) {
try {
// check if the http response has a 200 status
assert(returnedpage.statuscode === 200);
// check if the page contains the text "congratulations"
// you can change this to check for different text, or add other tests as required
assert(returnedpage.contains('congratulations'));
// succeed the job
putjobsuccess("tests passed.");
} catch (ex) {
// if any of the assertions failed then fail the job
putjobfailure(ex);
}
});
};post-commit git hook for archiving and uploading to s3
i’m in the process of figuring out how to add a post-commit hook that moves files committed to a specific directory in a git repository, zip up the necessary artifacts and upload to a pre-defined directory in s3 so that i can remove this manual activity as well.
summary
by adding the ability to invoke lambda functions directly from codepipeline, aws has opened a whole new world of what can be orchestrated into our software delivery processes in aws. you learned how to automate the provisioning of not just the lambda configuration, but dependent aws resources including the automated provisioning of your pipelines in aws codepipeline. if you have any questions, reach out to us on twitter @stelligent or @paulduvall .
resources
Published at DZone with permission of Paul Duvall, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments