Recognizing Music Genres With the Raspberry Pi Pico
In this article, we will deploy the TensorFlow Lite model to recognize the music genre from audio clips recorded with the microphone connected to the microcontroller.
Join the DZone community and get the full member experience.
Join For FreeThis article is an excerpt from my book TinyML Cookbook, Second Edition. You can find the code used in the article here.
Getting Ready
The application we will design in this article aims to continuously record a 1-second audio clip and run the model inference, as illustrated in the following image:
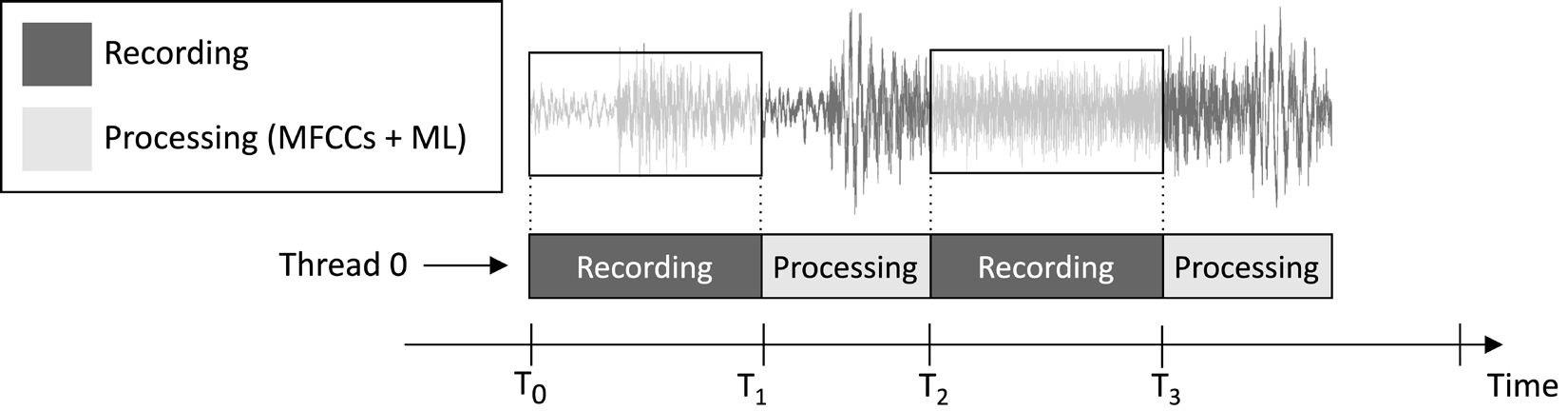
Figure 1: Recording and processing tasks running sequentially
From the task execution timeline shown in the preceding image, you can observe that the feature extraction and model inference are always performed after the audio recording and not concurrently. Therefore, it is evident that we do not process some segments of the live audio stream.
Unlike a real-time keyword spotting (KWS) application, which should capture and process all pieces of the audio stream to never miss any spoken word, here, we can relax this requirement because it does not compromise the effectiveness of the application.
As we know, the input of the MFCCs feature extraction is the 1-second raw audio in Q15 format. However, the samples acquired with the microphone are represented as 16-bit integer values. Hence, how do we convert the 16-bit integer values to Q15? The solution is more straightforward than you might think: converting the audio samples is unnecessary.
To understand why, consider the Q15 fixed-point format. This format can represent floating-point values within the [-1, 1] range. Converting from floating-point to Q15 involves multiplying the floating-point values by 32,768 (215). Nevertheless, because the floating-point representation originates from dividing the 16-bit integer sample by 32,768 (215), it implies that the 16-bit integer values are inherently in Q15 format.
How To Do It…
Take the breadboard with the microphone attached to the Raspberry Pi Pico. Disconnect the data cable from the microcontroller, and remove the push-button and its connected jumpers from the breadboard, as they are not required for this recipe. Figure 2 shows what you should have on the breadboard:
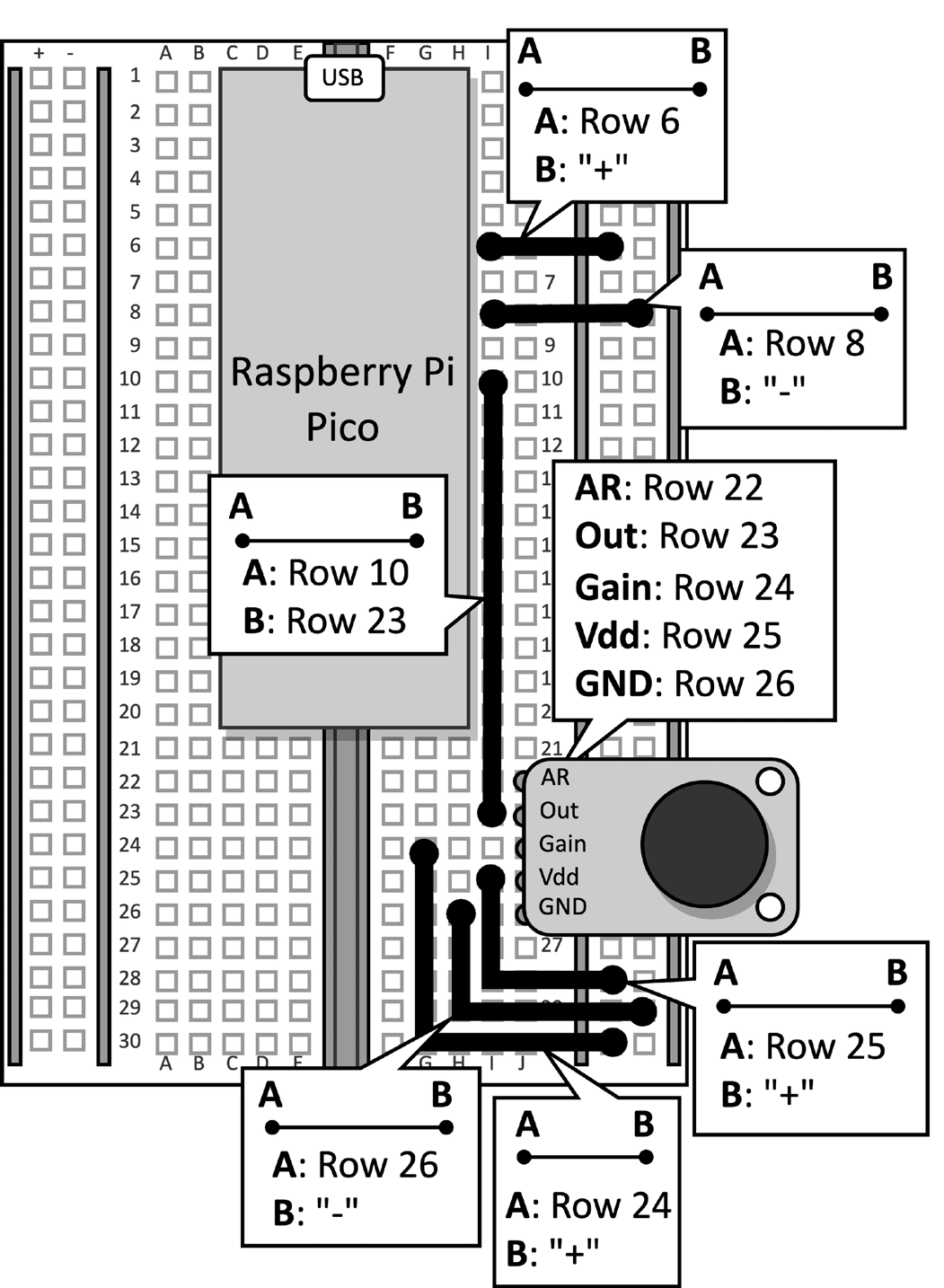
Figure 2: The electronic circuit built on the breadboard
After removing the push-button from the breadboard, open the Arduino IDE and create a new sketch.
Now, follow the following steps to develop the music genre recognition application on the Raspberry Pi Pico:
Step 1
Download the Arduino TensorFlow Lite library from the TinyML-Cookbook_2E GitHub repository.
After downloading the ZIP file, import it into the Arduino IDE.
Step 2
Import all the generated C header files required for the MFCCs feature extraction algorithm in the Arduino IDE, excluding test_src.h and test_dst.h.
Step 3
Copy the sketch developed in Chapter 6, Deploying the MFCCs feature extraction algorithm on the Raspberry Pi Pico for implementing the MFCCs feature extraction, excluding the setup() and loop() functions.
Remove the inclusion of the test_src.h and test_dst.h header files. Then, remove the allocation of the dst array, as the MFCCs will be directly stored in the model’s input.
Step 4
Copy the sketch developed in Chapter 5, Recognizing Music Genres with TensorFlow and the Raspberry Pi Pico – Part 1, to record audio samples with the microphone, excluding the setup() and loop() functions.
Once you have imported the code, remove any reference to the LED and the push-button, as they are no longer required. Then, change the definition of AUDIO_LENGTH_SEC to record audio lasting 1 second:
#define AUDIO_LENGTH_SEC 1Step 5
Import the header file containing the TensorFlow Lite model (model.h) into the Arduino project.
Once the file has been imported, include the model.h header file in the sketch:
#include "model.h"
Include the necessary header files for tflite-micro:
#include <TensorFlowLite.h>
#include <tensorflow/lite/micro/all_ops_resolver.h>
#include <tensorflow/lite/micro/micro_interpreter.h>
#include <tensorflow/lite/micro/micro_log.h>
#include <tensorflow/lite/micro/system_setup.h>
#include <tensorflow/lite/schema/schema_generated.h>Step 6
Declare global variables for the tflite-micro model and interpreter:
const tflite::Model* tflu_model = nullptr;
tflite::MicroInterpreter* tflu_interpreter = nullptr;
Then, declare the TensorFlow Lite tensor objects (TfLiteTensor) to access the input and output tensors of the model:
TfLiteTensor* tflu_i_tensor = nullptr;
TfLiteTensor* tflu_o_tensor = nullptr;
Step 7
Declare a buffer (tensor arena) to store the intermediate tensors used during the model execution:
constexpr int tensor_arena_size = 16384;
uint8_t tensor_arena[tensor_arena_size] __attribute__((aligned(16)));
The size of the tensor arena has been determined through empirical testing, as the memory needed for the intermediate tensors varies, depending on how the LSTM operator is implemented underneath. Our experiments on the Raspberry Pi Pico found that the model only requires 16 KB of RAM for inference.
Step 8
In the setup() function, initialize the serial peripheral with a 115200 baud rate:
Serial.begin(115200);
while (!Serial);
The serial peripheral will be employed to transmit the recognized music genre over the serial communication.
Step 9
In the setup() function, load the TensorFlow Lite model stored in the model.h header file:
tflu_model = tflite::GetModel(model_tflite);Then, register all the DNN operations supported by tflite-micro, and initialize the tflite-micro interpreter:
tflite::AllOpsResolver tflu_ops_resolver;
static tflite::MicroInterpreter static_interpreter(
tflu_model,
tflu_ops_resolver,
tensor_arena,
tensor_arena_size);
tflu_interpreter = &static_interpreter;Step 10
In the setup() function, allocate the memory required for the model, and get the memory pointer of the input and output tensors:
tflu_interpreter->AllocateTensors();
tflu_i_tensor = tflu_interpreter->input(0);
tflu_o_tensor = tflu_interpreter->output(0);
Step 11
In the setup() function, use the Raspberry Pi Pico SDK to initialize the ADC peripheral:
adc_init();
adc_gpio_init(26);
adc_select_input(0);
Step 12
In the loop() function, prepare the model’s input. To do so, record an audio clip for 1 second:
// Reset audio buffer
buffer.cur_idx = 0;
buffer.is_ready = false;
constexpr uint32_t sr_us = 1000000 / SAMPLE_RATE;
timer.attach_us(&timer_ISR, sr_us);
while(!buffer.is_ready);
timer.detach();After recording the audio, extract the MFCCs:
mfccs.run((const q15_t*)&buffer.data[0],
(float *)&tflu_i_tensor->data.f[0]);
As you can see from the preceding code snippet, the MFCCs will be stored directly in the model’s input.
Step 13
Run the model inference and return the classification result over the serial communication:
tflu_interpreter->Invoke();
size_t ix_max = 0;
float pb_max = 0;
for (size_t ix = 0; ix < 3; ix++) {
if(tflu_o_tensor->data.f[ix] > pb_max) {
ix_max = ix;
pb_max = tflu_o_tensor->data.f[ix];
}
}
const char *label[] = {"disco", "jazz", "metal"};
Serial.println(label[ix_max]);Now, plug the micro-USB data cable into the Raspberry Pi Pico. Once you have connected it, compile and upload the sketch on the microcontroller.
Afterward, open the serial monitor in the Arduino IDE and place your smartphone near the microphone to play a disco, jazz, or metal song. The application should now recognize the song’s music genre and display the classification result in the serial monitor!
Conclusion
In this article, you learned how to deploy a trained model for music genre classification on the Raspberry Pi Pico using tflite-micro.
Opinions expressed by DZone contributors are their own.
Comments