Real-Time Streaming ETL Using Apache Kafka, Kafka Connect, Debezium, and ksqlDB
Clarify why we need to transfer data from one point to another, look at traditional approaches, and describe how to build a real-time streaming ETL process.
Join the DZone community and get the full member experience.
Join For FreeAs most of you already know, ETL stands for Extract-Transform-Load and is the process of moving data from one source system to another. First, we will clarify why we need to transfer data from one point to another; second, we will look at traditional approaches; finally, we will describe how one can build a real-time streaming ETL process using Apache Kafka, Kafka Connect, Debezium, and ksqlDB.
When we build our business applications, we design the data model considering the functional requirements of our application. We do not take account of any kind of operational or analytical reporting requirements. A data model for reporting requirements is to be denormalized, whereas the data model for operations of an application is to be mostly normalized. So, for reporting or any kind of analytical purposes, we are required to convert our data model into denormalized form.
In order to reshape our data, we need to move it to another database. One may argue that we can reshape our data within the same database using database views, or materialized views, but configurations for a reporting database may differ from an operational database, mostly an operational database is configured as an OLTP (transactional), and a reporting database is configured as OLAP (analytical). Moreover, executing a reporting process on an operational database will slow down the business transaction, and it will result in a slowdown in the business process, so your businesspeople will be unhappy with it. TLDR; if you need to prepare a report or want to make analytical studies on your operational database, you should move your data to another database.
In the industry, people mostly extract data from the source system in batches, in reasonable periods, mostly daily, but it can be hourly or once in two or three days. Keeping the period short may cause higher resource usage in the source system and frequent interruption in the target system; however, keeping it long may cause an up-to-date problem in the target system. So we need something that will cause a minimum effect on the source systems' performance and will update the target system in shorter periods or maybe in real time.
Now let’s see the proposed architecture. You can find the full source code of this demo project on my GitHub repository: https://github.com/dursunkoc/ksqlwithconnect. We will be using Debezium source connector to extract data changes from the source system.
Debezium is not extracting data using SQL. It uses database log files to track the changes in the database, so it has minimum effect on the source system. For more information about Debezium, please visit their website.
After the data is extracted, we need Kafka Connect to stream it into Apache Kafka in order to play with it and reshape it as we required. And we will be using ksqlDB in order to reshape the raw data in a way we are required in the target system. Let’s consider a simple ordering system database in which we have a customer table, a product table, and an orders table, as shown below.

Now, let’s consider we need to present a report on orders where we see purchaser’s email, and the name of the product on the same row. So we need a table, as shown below:
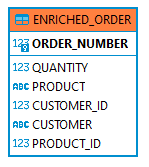
The customer column will contain the email of the customer which resides in the email field of the customers table, and the product column will contain the name of the product which resides in the name field of the products table.
First, we need to create a source connector to extract the data from source database. In our sample case, the source database is a MySQL database, so we will be using Debezium MySQL Source Connector as below:
CREATE SOURCE CONNECTOR `mysql-connector` WITH(
"connector.class"= 'io.debezium.connector.mysql.MySqlConnector',
"tasks.max"= '1',
"database.hostname"= 'mysql',
"database.port"= '3306',
"database.user"= 'root',
"database.password"= 'debezium',
"database.server.id"= '184054',
"database.server.name"= 'dbserver1',
"database.whitelist"= 'inventory',
"table.whitelist"= 'inventory.customers,inventory.products,inventory.orders',
"database.history.kafka.bootstrap.servers"= 'kafka:9092',
"database.history.kafka.topic"= 'schema-changes.inventory',
"transforms"= 'unwrap',
"transforms.unwrap.type"= 'io.debezium.transforms.ExtractNewRecordState',
"key.converter"= 'org.apache.kafka.connect.json.JsonConverter',
"key.converter.schemas.enable"= 'false',
"value.converter"= 'org.apache.kafka.connect.json.JsonConverter',
"value.converter.schemas.enable"= 'false');Now we will have Kafka topics for tables, customers, products, and orders from the source system.
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
-----------------------------------------------------------------
dbserver1 | 1 | 1
dbserver1.inventory.customers | 1 | 1
dbserver1.inventory.orders | 1 | 1
dbserver1.inventory.products | 1 | 1
default_ksql_processing_log | 1 | 1
my_connect_configs | 1 | 1
my_connect_offsets | 25 | 1
my_connect_statuses | 5 | 1
schema-changes.inventory | 1 | 1
-----------------------------------------------------------------Now, with the following scripts, we will create a ksqlDB stream for orders which joins customer and products data beside the order data.
CREATE STREAM S_CUSTOMER (ID INT,
FIRST_NAME string,
LAST_NAME string,
EMAIL string)
WITH (KAFKA_TOPIC='dbserver1.inventory.customers',
VALUE_FORMAT='json');
CREATE TABLE T_CUSTOMER
AS
SELECT id,
latest_by_offset(first_name) as fist_name,
latest_by_offset(last_name) as last_name,
latest_by_offset(email) as email
FROM s_customer
GROUP BY id
EMIT CHANGES;
CREATE STREAM S_PRODUCT (ID INT,
NAME string,
description string,
weight DOUBLE)
WITH (KAFKA_TOPIC='dbserver1.inventory.products',
VALUE_FORMAT='json');
CREATE TABLE T_PRODUCT
AS
SELECT id,
latest_by_offset(name) as name,
latest_by_offset(description) as description,
latest_by_offset(weight) as weight
FROM s_product
GROUP BY id
EMIT CHANGES;
CREATE STREAM s_order (
order_number integer,
order_date timestamp,
purchaser integer,
quantity integer,
product_id integer)
WITH (KAFKA_TOPIC='dbserver1.inventory.orders',VALUE_FORMAT='json');
CREATE STREAM SA_ENRICHED_ORDER WITH (VALUE_FORMAT='AVRO') AS
select o.order_number, o.quantity, p.name as product, c.email as customer, p.id as product_id, c.id as customer_id
from s_order as o
left join t_product as p on o.product_id = p.id
left join t_customer as c on o.purchaser = c.id
partition by o.order_number
emit changes;Finally, with help of a JDBC sink connector, we will push our enriched orders table into the PostgreSQL database.
CREATE SINK CONNECTOR `postgres-sink` WITH(
"connector.class"= 'io.confluent.connect.jdbc.JdbcSinkConnector',
"tasks.max"= '1',
"dialect.name"= 'PostgreSqlDatabaseDialect',
"table.name.format"= 'ENRICHED_ORDER',
"topics"= 'SA_ENRICHED_ORDER',
"connection.url"= 'jdbc:postgresql://postgres:5432/inventory?user=postgresuser&password=postgrespw',
"auto.create"= 'true',
"insert.mode"= 'upsert',
"pk.fields"= 'ORDER_NUMBER',
"pk.mode"= 'record_key',
"key.converter"= 'org.apache.kafka.connect.converters.IntegerConverter',
"key.converter.schemas.enable" = 'false',
"value.converter"= 'io.confluent.connect.avro.AvroConverter',
"value.converter.schemas.enable" = 'true',
"value.converter.schema.registry.url"= 'http://schema-registry:8081'
);You can find the full source code of this demo project on my GitHub repository: https://github.com/dursunkoc/ksqlwithconnect.
Published at DZone with permission of Dursun Koç, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments