Real-Time Stream Processing With Hazelcast and StreamNative
In this article, readers will learn about real-time stream processing with Hazelcast and StreamNative in a shorter time, along with demonstrations and code.
Join the DZone community and get the full member experience.
Join For FreeOne of the most useful features of real-time stream processing is to combine the strengths and advantages of various technologies to provide a unique developer experience and an efficient way of processing data in real-time at scale. Hazelcast is a real-time distributed computation and storage platform for consistently low latency queries, aggregation, and stateful computation against real-time event streams and traditional data sources. Apache Pulsar is a real-time multitenant geo-replicated distributed pub-sub messaging and streaming platform for real-time workloads, handling millions of events per hour.
However, real-time stream processing is not an easy task, especially when combining multiple live streams with large volumes of data stored in external data storages to provide context and instant results. When it comes to usage, Hazelcast can be used for the following things:
- Stateful data processing over real-time streaming data.
- Data at rest.
- A combination of data at rest and stateful data processing over real-time streaming data.
- Querying streaming.
- Batch data sources directly using SQL.
- Distributed coordination for microservices.
- Replicating data from one region to another.
- Replicating data between data centers in the same region.
While Apache Pulsar can be used for messaging and streaming, use cases take the place of multiple products and provide a superset of their features. Apache Pulsar is a cloud-native multitenant unified messaging platform to replace Apache Kafka, RabbitMQ, MQTT, and legacy messaging platforms. Apache Pulsar provides an infinite message bus for Hazelcast to act as an instant source and sink for any and all data sources.
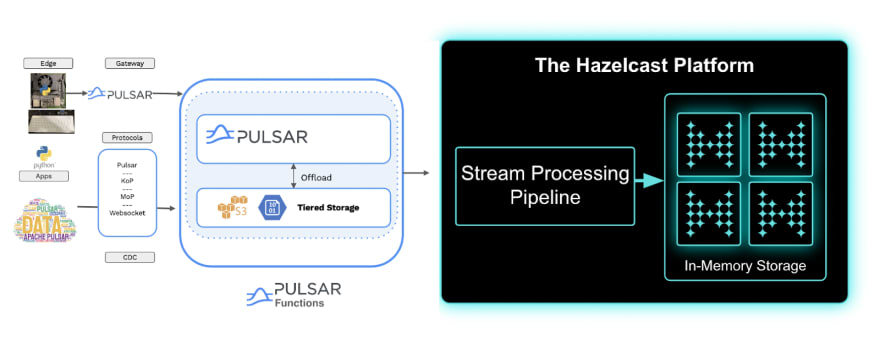
Prerequisites
We’re building an application where we ingest data from Apache Pulsar into Hazelcast and then process it in real time. To run this application, make sure your system has the following components:
- Hazelcast installed on your system: we’re using CLI.
- Pulsar installed on your system: we’re using Docker.
If you have macOS and Homebrew, you can install Hazelcast using the following command:
brew tap hazelcast/hz
brew install hazelcast@5.2.1Check if Hazelcast is installed:
hz -V
Then start a local cluster:
hz start
You should see the following in the console:
INFO: [192.168.1.164]:5701 [dev] [5.2.1]
Members {size:1, ver:1} [
Member [192.168.1.164]:5701 - 4221d540-e34e-4ff2-8ad3-41e060b895ce this
]You can start Pulsar in Docker using the following command:
docker run -it -p 6650:6650 -p 8080:8080 \
--mount source=pulsardata,target=/pulsar/data \
--mount source=pulsarconf,target=/pulsar/conf \
apachepulsar/pulsar:2.11.0 bin/pulsar standaloneTo install Management Center, use one of the following methods, depending on your operating system:
brew tap hazelcast/hz
brew install hazelcast-management-center@5.2.1Check that Management Center is installed:
hz-mc -V
Data Collection
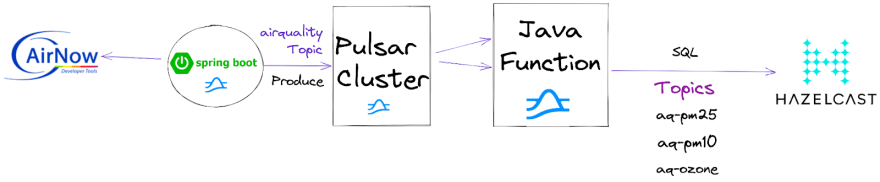
For our application, we wish to ingest air quality readings from around the United States via the AirNow data provider.
Source: AirNow API
With a simple Java application, we make REST calls to the AirNow API that provides air quality reading for major zip codes around the United States. The Java application sends the JSON-encoded AirNow data to the “airquality” Pulsar topic. From this point, a Hazelcast application can read it.
Source: GitHub
We also have a Java Pulsar function receiving each event from the “airquality” topic and parsing it into different topics based on which type of air quality reading it is. This includes PM2.5, PM10, and Ozone.
Source: GitHub
Example AirQuality Data
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","latitude":39.95,"longitude":-75.151,"parameterName":"PM10","aqi":19,"category":{"number":1,"name":"Good","additionalProperties":{}},"additionalProperties":{}}Example Ozone Data
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"O3","latitude":39.95,"longitude":-75.151,"aqi":8}Example PM10 Data
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"PM10","latitude":39.95,"longitude":-75.151,"aqi":19}Example PM2.5 Data
{"dateObserved":"2023-01-19 ","hourObserved":12,"localTimeZone":"EST","reportingArea":"Philadelphia","stateCode":"PA","parameterName":"PM2.5","latitude":39.95,"longitude":-75.151,"aqi":54}
Data Processing
In order to process the data collected, we used the Hazelcast Pulsar connector module to ingest data from Pulsar topics.
Note: you can use the same connector to write to Pulsar topics.
Using Hazelcast allows us to compute various aggregation functions (sum, avg, etc.) in real-time on a specified window of stream items. The Pulsar connector uses the Pulsar client library, which has two different ways of reading messages from a Pulsar topic. These are Consumer API and Reader API; both use the builder pattern (for more information, click here).
In your pom file, import the following dependencies:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.4</version>
</dependency>
<dependency>
<groupId>com.hazelcast.jet.contrib</groupId>
<artifactId>pulsar</artifactId>
<version>0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>2.10.1</version>
</dependency> We create a PulsarSources.pulsarReaderBuilder instance to connect to the previously started Pulsar cluster located at pulsar://localhost:6650.
StreamSource<Event>source = PulsarSources.pulsarReaderBuilder(
topicName,
() -> PulsarClient.builder().serviceUrl("pulsar://localhost:6650").build(),
() -> Schema.JSON(Event.class),
Message::getValue).build();We then create a pipeline to read from the source with a sliding window and aggregate count before we write to logger:
Pipeline p = Pipeline.create();
p.readFrom(source)
.withNativeTimestamps(0)
.groupingKey(Event::getUser)
.window(sliding(SECONDS.toMillis(60), SECONDS.toMillis(30)))
.aggregate(counting())
.writeTo(Sinks.logger(wr -> String.format(
"At %s Pulsar got %,d messages in the previous minute from %s.",
TIME_FORMATTER.format(LocalDateTime.ofInstant(
Instant.ofEpochMilli(wr.end()), ZoneId.systemDefault())),
wr.result(), wr.key())));
JobConfig cfg = new JobConfig()
.setProcessingGuarantee(ProcessingGuarantee.EXACTLY_ONCE)
.setSnapshotIntervalMillis(SECONDS.toMillis(1))
.setName("pulsar-airquality-counter");
HazelcastInstance hz = Hazelcast.bootstrappedInstance();
hz.getJet().newJob(p, cfg);You can run the previous code from your IDE (in this case, it will create its own Hazelcast member and run the job on it), or you can run this on the previously started Hazelcast member (in this case, you need to create a runnable JAR including all dependencies required to run it):
mvn package
bin/hz-cli submit target/pulsar-example-1.0-SNAPSHOT.jar
To cancel the job and shut down the Hazelcast cluster:
bin/hz-cli cancel pulsar-message-counter
hz-stopConclusion
In this article, we demonstrated how you can combine the strengths and advantages of various technologies to provide a unique developer experience and an efficient way of processing data in real-time at scale. We streamed air quality data from Apache Pulsar into Hazelcast, where we processed data in real-time. The rising trend in cloud technologies, the need for real-time intelligent applications, and the urgency to process data at scale have brought us to a new chapter of real-time stream processing, where latencies are measured, not in minutes but in milliseconds and submillisecond’s.
Hazelcast allows you to quickly build resource-efficient, real-time applications. You can deploy it at any scale, from small-edge devices to a large cluster of cloud instances. A cluster of Hazelcast nodes shares the data storage and computational load, which can dynamically scale up and down. When you add new nodes to the cluster, the data is automatically rebalanced across the cluster, and currently running computational tasks (known as jobs) snapshot their state and scale with processing guarantees. Pulsar allows you to use your choice of messaging protocols to quickly distribute events between multiple types of consumers and producers and act as a universal message hub. Pulsar separates compute from storage, allowing for dynamic scaling and efficient handling of fast data. StreamNative is the company made up of the original creators of Apache Pulsar and Apache BookKeeper. StreamNative provides a full enterprise experience for Apache Pulsar in the cloud and on-premise.
Published at DZone with permission of Fawaz Ghali, PhD. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments