Rapid Debugging With Proper Exception Handling
In this article, you will learn when to use and when NOT to use exception handling using concrete examples.
Join the DZone community and get the full member experience.
Join For FreeAs a developer, often the most irritating part of development is debugging. Most programmers I have worked with would echo this sentiment. Often the first reaction to seeing an exception is a mixture of annoyance and frustration. Exceptions that are easy to debug yield the root cause often within a few minutes of debugging. The ones that annoy me the most are the ones that happen days after the system has been running properly in production, and their stack traces lead to a dead end. However, well-written code which manages exceptions properly not only helps you debug issues faster but, in certain situations, can help systems recover automatically without intervention.
Fortunately, there are some simple and effective tools that you can use to reduce the time you spend debugging the latter kind of exceptions. Often this technique doesn't really improve the reliability of the software that you are developing(At Least not at first), but it becomes much easier to root cause an issue and come up with a fix for it.
When Not to Use Exceptions?
Before jumping into the details of exception handling, it is critical to understand when not to use exceptions at all. Consider the following scenario where the client wants to close the session with the server by sending the "QUIT" command.
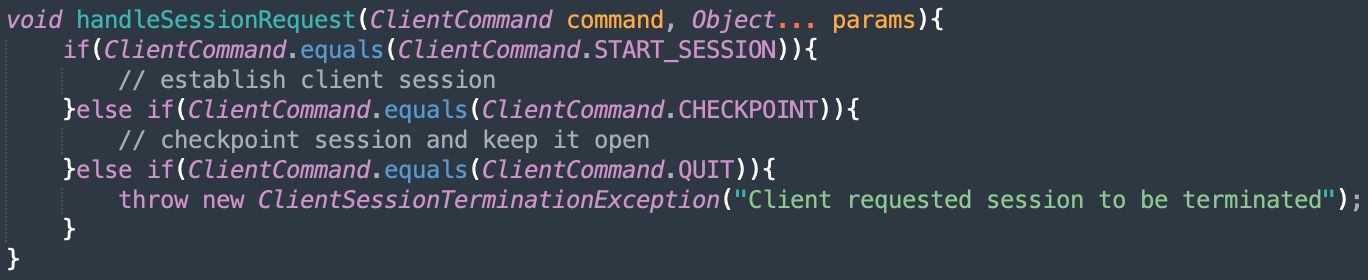
This is a horrible use of exceptions for a variety of reasons.
Exceptions are hard to follow both in implementation and maintainability: Since this is expected to happen, how does your client know whether something actually went wrong or this is just an expected exception? The code to gracefully close the session on the client side would be intermingled with other exceptions that can occur from this service. Imagine if you were a developer on the client team. Wouldn't it be frustrating to follow along with what's happening in your exception-handling code?
Signaling exceptional situations is hard: You are using exceptions to handle normal code flow. What's the plan for when an actual exception occurs? What happens if there is a client-side bug which catches a generic exception instead of this specific one?
Performance: When exceptions occur, your program control stack is thrown out of the window, and your normal call stack routine is disrupted. Since exceptions are expected to only occur in exceptional scenarios, the performance of these processes is often not of the highest priority by the run-time.
To summarize, always remember that exceptions should only be thrown for "EXCEPTIONAL" situations.
Basics of Exceptions in Java
Error vs. Exception/ Catching Throwable vs. Exception
An Error is a subclass of Throwable that indicates serious problems that a reasonable application should not try to catch. Most such errors are abnormal conditions. The ThreadDeath error, though a "normal" condition, is also a subclass of Error because most applications should not try to catch it. Catching throwable catches all errors. Since throwables are raised in extreme conditions, you are almost never expected to recover from it. Therefore catching throwable is not only a bad design practice but can also lead to unintended consequences, which can make the application harder to debug.
Checked vs. Unchecked Exceptions
Let's look at the hierarchy of exceptions in Java.
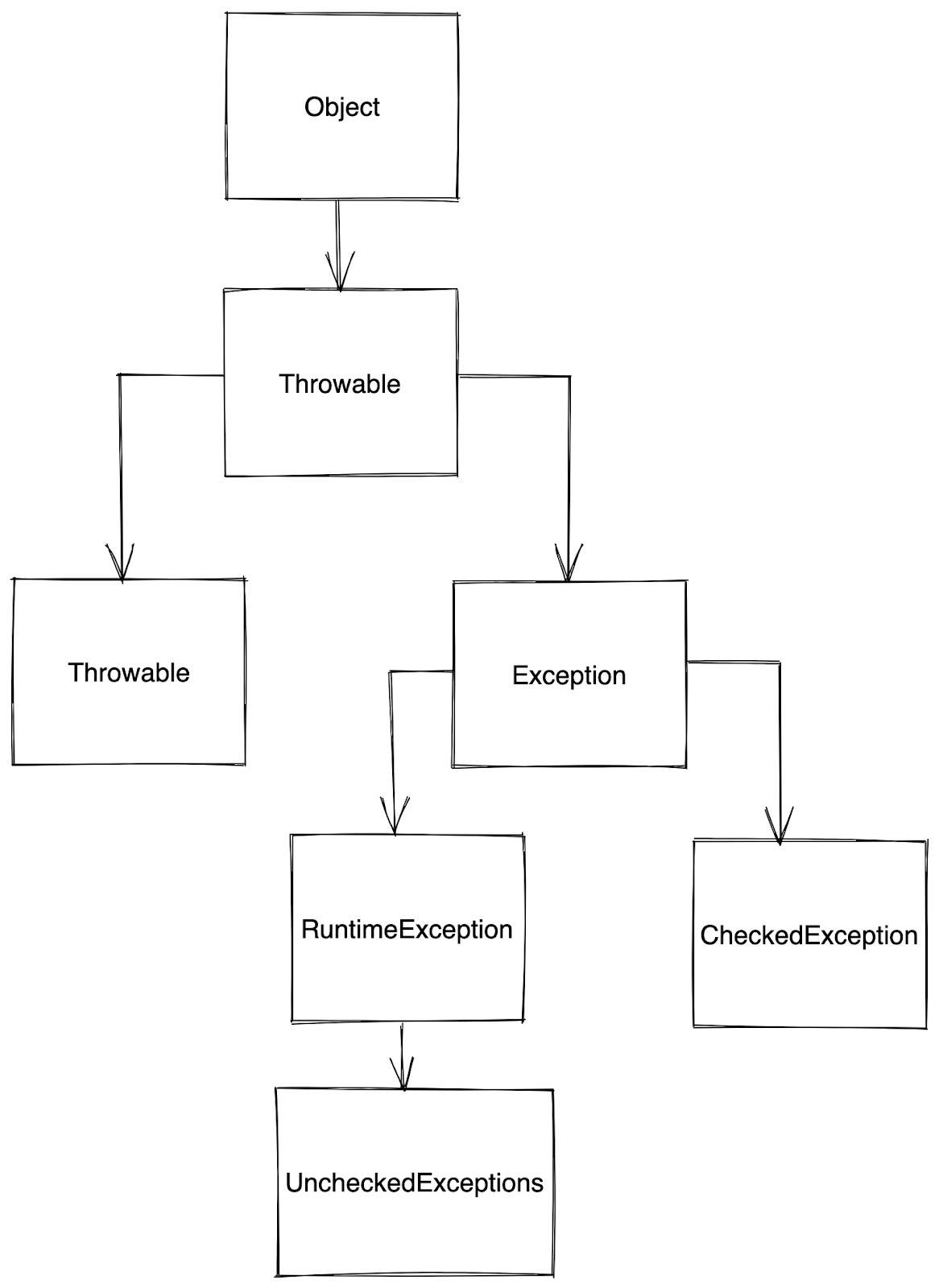
Checked and unchecked exceptions both inherit from the generic "Exception" class(at least indirectly); however, they serve very different purposes in their usage.
Throwing checked exceptions forces your caller to think about what they want to do with the exception. They can't simply ignore it. They either need to catch it and do something with it or explicitly throw it back to their caller. This is because the Java compiler won't let you compile a method call that can receive a checked exception and ignore it.

Unchecked exceptions are purely run-time exceptions. Often you don't anticipate all your callers to know about every single run-time exception that can be thrown from your application code. The caller doesn't need to explicitly think about what to do when a run-time exception is thrown.
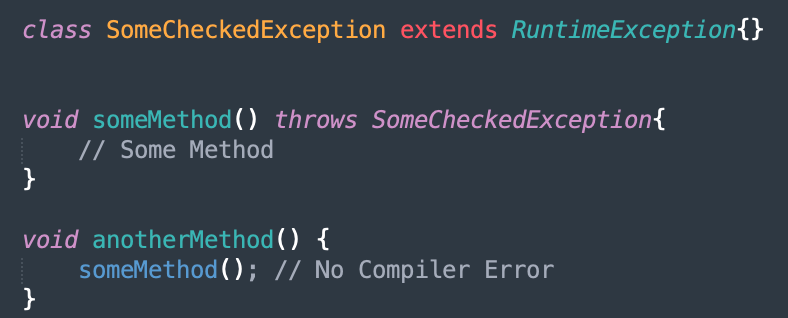
A general rule of thumb that I often follow is to use checked exceptions for when your caller would like to catch the exception and do something about it. This rule does come with a grain of salt. What if you are at the UI layer and making a service call? You probably want to catch all exceptions instead of showing a Java stack trace on the screen.
Throw Specific Exceptions
How many times have you seen a code that looks like this?
![]()
Often this is the easiest mistake to miss out on when writing the code. You are against a deadline, and exception handling is probably the last thing you think about.
Throwing generic exceptions significantly hampers your caller's ability to handle different exceptions differently. Here a caller would explicitly need to capture the generic exception, maybe do some string magic to understand what the issue with the code is, and then handle it appropriately. Instead, if you just threw a more specific exception, the caller would be able to clearly understand what has happened wrong by just catching different kinds of exceptions and handling each exception differently or as the program decides.
Never Swallow Exceptions
Swallowing exceptions is dangerous, with almost no exceptions anywhere. Here's a simple example to demonstrate the issue that can occur.
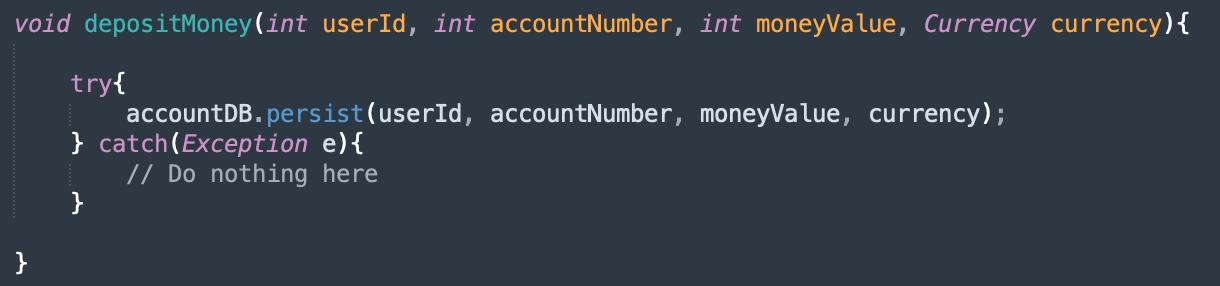
With the reliability of the DB call being 99.999%, suppose 0.001% calls to persist the value in the DB fails; what's the most likely user complaint that you will receive that you need to debug? "No money deposited in the account even though the transaction is marked as successful." This may seem like a scenario that never happens(or very rarely happens), but in the time that I have worked in the software industry, I have run across 100s of instances where I have read code that resembles this. Forget about recovering from exceptions; the caller here just doesn't know if there was an exception. You, as a developer receiving this bug report, have no idea what went wrong. Was there a problem with the database connection? Or were you throttled by your DB? Even basic questions like where did the exception happen become impossible to answer.
Don't Lose Your Stack Trace
A common and easy mistake that I have observed frequently is code that looks like this.
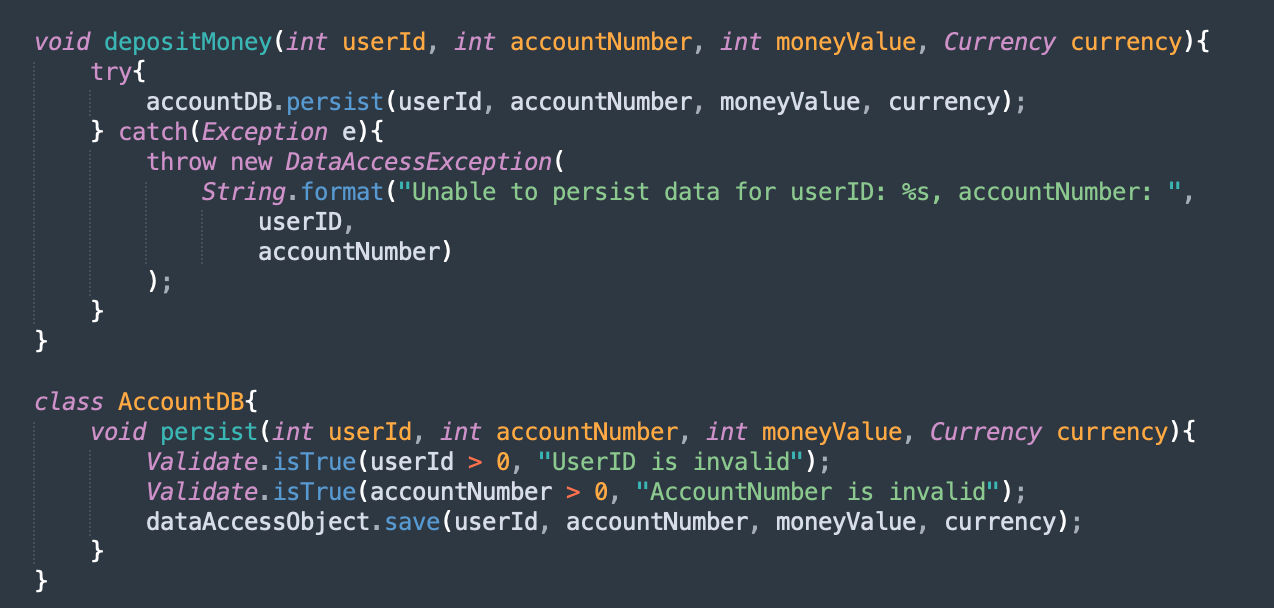
Unlike the previous example, here you know where the error happened. It happened when you made the persistent function call. However, what do you want to do about the error once you know something bad happened at this point? When you look at the stack trace, it doesn't tell you much other than where the error happened from. Was the user ID incorrect? Was the account number incorrect? Did the database save operation fails? Ensuring you propagate the stack trace to the caller is an easy way to answer these questions.
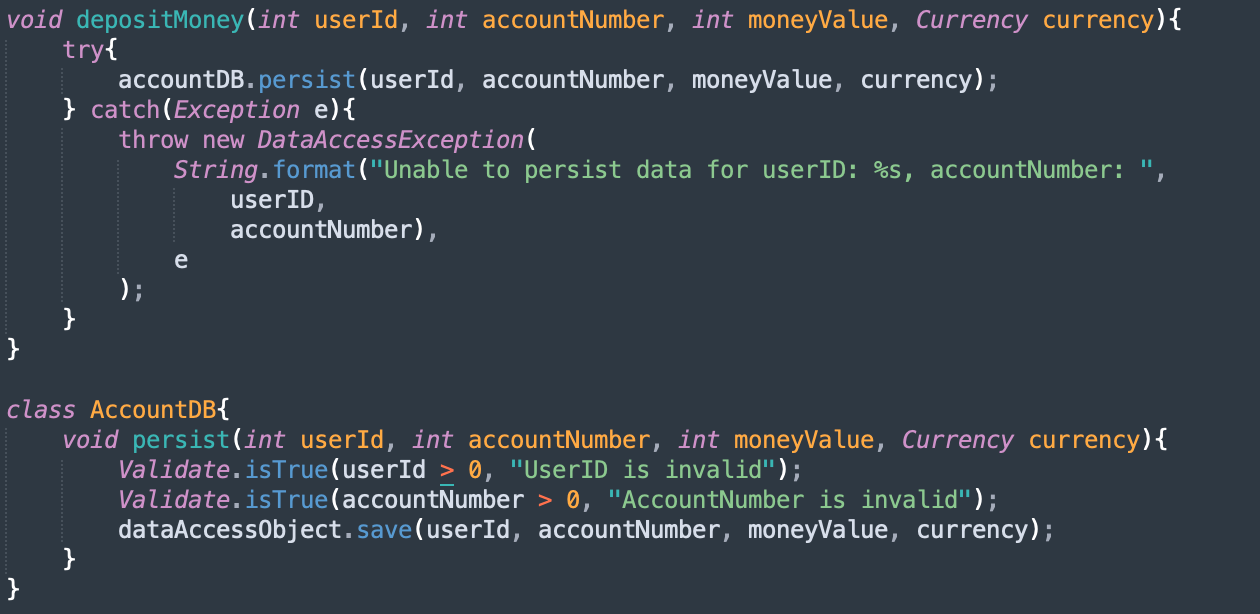
Here, the stack trace would precisely answer the questions we asked above. Just looking at the stack trace, you would know which line threw an exception. A recursive audit of all catch blocks is a must to find any loopholes in your system.
Fail-Fast
Often there are arguments made when we try to recover from failures automatically. Over time more complex and nuanced issues occur in these scenarios, which are frustrating to debug. Let's look at an example of this.
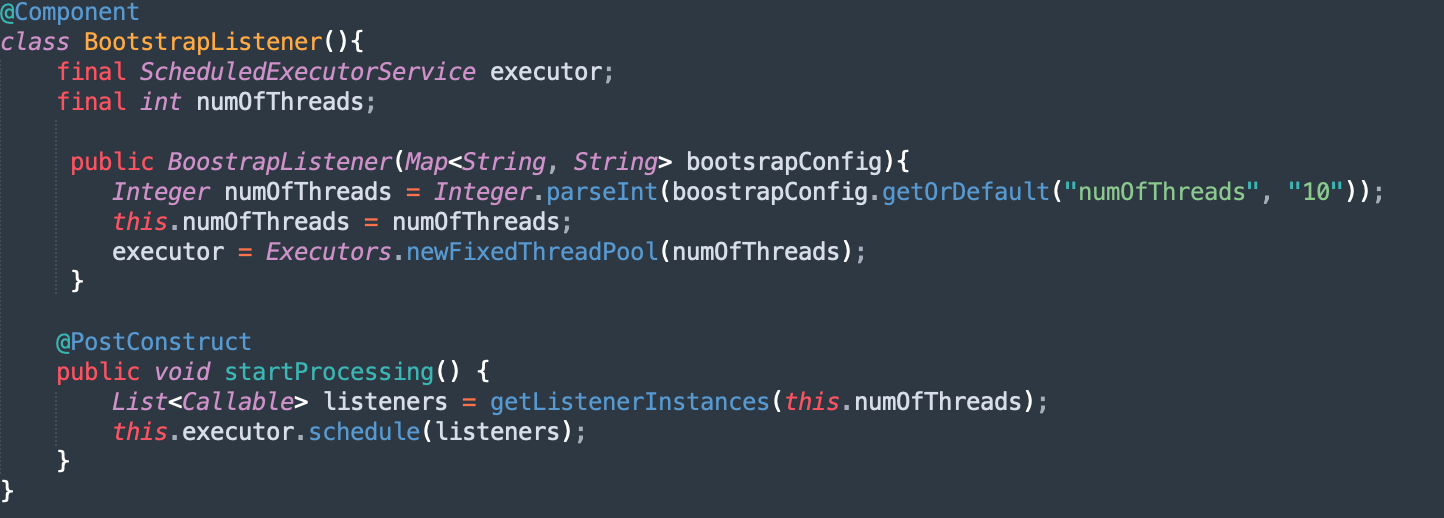
Imagine here you are bootstrapping a service that runs a bunch of listeners based on the available thread pool size. Now suppose one of the developers introduces a typo in the Config or while accessing the Config to get the number of threads. Nothing fails; your service bootstraps, but your latency starts to increase. I can imagine in certain scenarios, you would have to go to great lengths to root the cause of this issue.
Code that fails fast completely avoids this issue. You expect to use a certain config. Why not throw immediately if the Config is not found? Doing so not only pinpoints the issue precisely but also helps find issues during development, saving the hassle of pushing in an emergency fix.
Failing fast also means you fail at the place where you make assumptions about the state of the code. Let's look at another example to understand this.

This code can lead to a dead-end stack trace. If a NullPointerException is thrown when the process method is called, how do you know if either of the inputs to the function is null or the "divisor" is null? Instead, a code that adds a not null assertion in the constructor for the divisor would immediately let a debugger know what went wrong here.
Cleanup Resources
Cleaning up any resource instances when an exception occurs is extremely crucial to avoid memory leaks. Memory leaks are a tricky class of errors as the symptoms are often not easy to co-relate to the root cause.
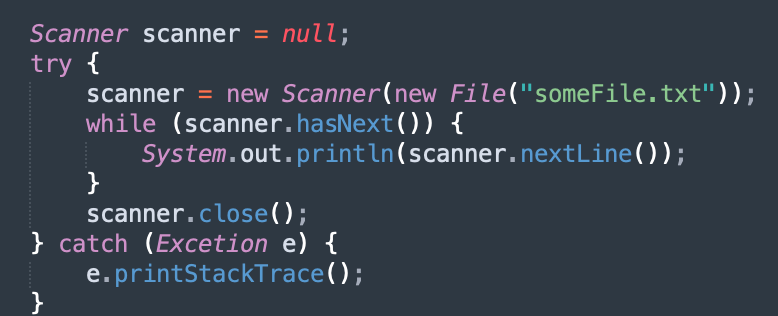
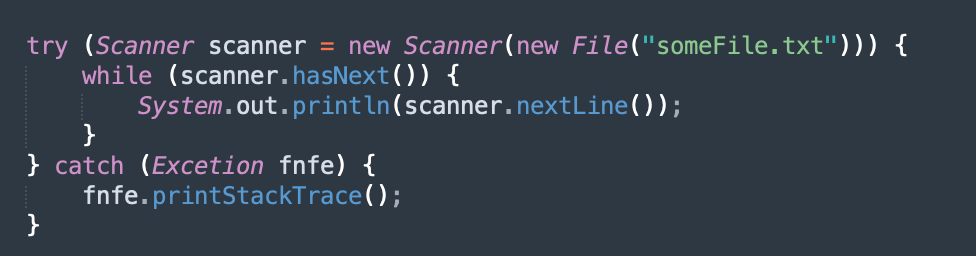
In the example mentioned above, if the scanner object was properly instantiated but an exception was raised while reading data from the file, the scanner object is never closed. Instead, use the try-with-resource semantic in Java to not worry about this issue at all.
Conclusion
As much as everyone hates exceptions, they are bound to happen. Java provides an excellent ecosystem around proper exception handling, which can help make your debugging life very easy. Understanding the basics of exception handling is paramount for good software delivery, and I intend to capture some methods which can help improve the robustness of your code and ultimately help cut down on the amount of time you spend debugging your code.
Opinions expressed by DZone contributors are their own.
Comments