PostgreSQL: Why and How WAL Bloats
This article is about the real life of PG’s Write-Ahead log and explores WAl and looks at why it bloats.
Join the DZone community and get the full member experience.
Join For Free
WAL. An Almost Short Introduction
Any changes to a PostgreSQL database, first of all, are saved in Write-Ahead log, so they will never get lost. Only after that actual changes are made to the data in memory pages (in a so-called buffer cache) and these pages are marked dirty — meaning they need to be synced to disk later.
For that there’s a Checkpoint process, ran periodically, that dumps all the "dirty" pages to disk. It also saves the position in WAL (called REDO point), up to which all changes are synchronized.
So in case of a Postgres DB crashes, it will restore its state by sequentially replaying the WAL records from REDO point. So all the WAL records before this point are useless for recovery, but still might be needed for replication purposes or for Point In Time Recovery.
From this description, a Super-Engineer might’ve figured out all the ways it will go wrong in real life :-) But in reality, usually one will do this in a reactive way: one needs to stumble upon a problem first.
WAL Bloats #1
Our (okmeter.io) monitoring agent for every instance of Postgres will find WAL files and collect their number and total size.
Here’s a case of some strange x6 growth of WAL size and segment count:
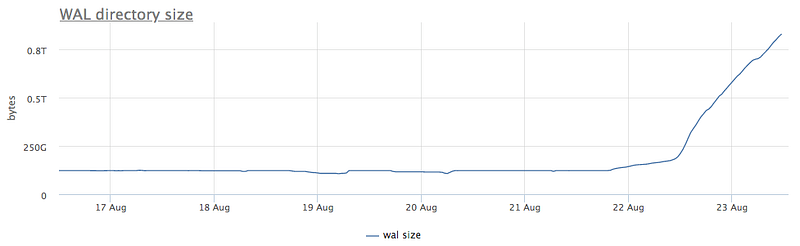
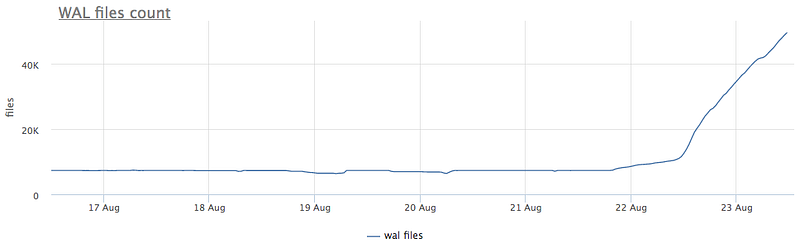
What could that be?
WAL is considered unneeded and to be removed after a Checkpoint is made. This is why we check it first. Postgres has a special system view called pg_stat_bgwriter that has info on checkpoints:
- checkpoints_timed — is a counter of checkpoints triggered due that the time elapsed from the previous checkpoint is more than pg setting
checkpoint_timeout. These are so called scheduled checkpoints. - checkpoints_req — is a counter of checkpoints ran due to uncheckpointed WAL size grew to more than
max_wal_sizesetting — requested checkpoints.
So let’s see:
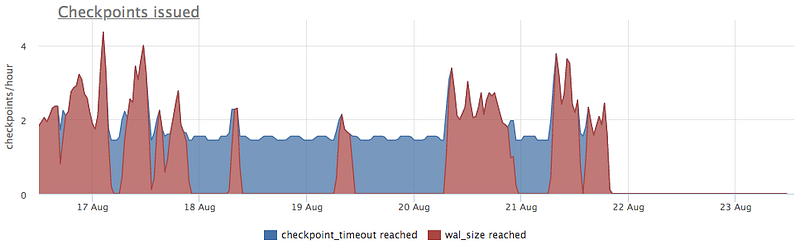
We see that after 21 Aug checkpoints ceased to run. Though we would love to know the exact reason it’s so, we can’t ¯\_(ツ)_/¯.
As one might remember, Postgres is known to be prone to unexpected behavior due to long-lasting transactions. Let’s see:
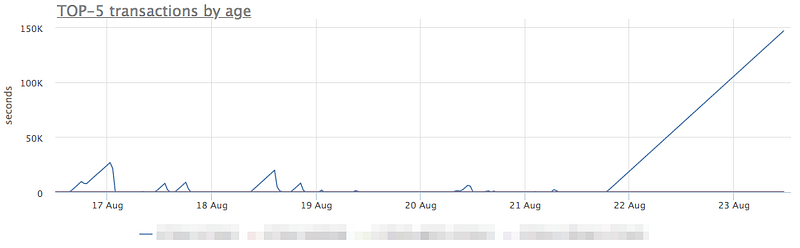
Yeah, it definitely very strange.
So what can we do about it?
- Kill it. Try
pg_cancel_backend - Try to figure out reasons of it halting.
- Wait, but check and monitor free disk space.
There’s an additional quirk here: all this leads to WAL bloat on all of the replicas too.
Using this as a chance to remind you — replica is not a backup.
WAL Bloats #2 — Archiving
Good backup is something that will allow you to restore at any point in the past.
So if “someone” (not you of course) executes this on the primary database:
DELETE FROM very_important_tbl;You better have a way to restore your DB state right before this transaction. It’s called Point-In-Time-Recovery, or just short — PITR.
And in Postgres, you would do this as a periodical full backup + WAL segments archives. For that, there’s a special setting — archive_command and ran a special postgres: archiver process. It periodically runs this command of your choice, and if it returns no error, deletes corresponding WAL segment file. But if there’s an error in archiving WAL file, which became more common with the wide use of cloud infrastructure (yes, I’m looking at you, AWS S3), it will retry and retry until successful. And this can lead to a massive amount of WAL files residing on disk and eating up its space.
So here’s a chart of a broken for a while WAL archiving:

You can get these counters from pg_stat_archiver system view.
Any monitoring systems collects different metrics on server infrastructure. And it’s not only charts but you can also alert on them and use them to improve your infrastructure to be more resilient.
The thing is that most of the widely used software is not designed with a goal of having deep observability capabilities. That’s why it’s so hard to have your monitoring set up in such a way that it will show you everything you need in time.
The most crucial metrics are hard to collect. It’s usually not presented by some system view, so you can just SELECT supa_useful_stat FROM cool_stat_view. While developing okmeter monitoring agent, we dig deep for meaningful and detailed metrics, so you’ll just have them when there’s need.
That is true for WAL and archiving as well — we not only collect fails from pg_stat_archiver and WAL size on disks, but with okmeter.io, you’ll have a metric that shows the amount of WAL residing on disks for the sole purpose of archiving. And here’s how it looks when your archival storage fails:
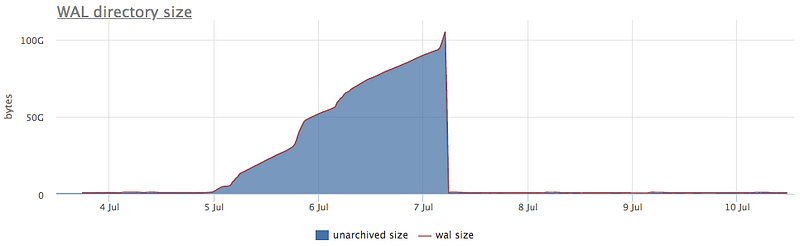
Our monitoring system — okmeter — will not only automatically collect such metrics, but we'll also alert you whenever archiving fails.
Replication
Postgres is well known for its Streaming Replication, which works via continuous transfer and replay of WAL segment files to/on a replica server.
For the case when some replica were unable to get all needed WAL segments instantly, there’s a stash of WAL files on the primary server. Special setting wal_keep_segments controls how many files will be kept by primary. But if a said replica will hang and lag behind for more than that, files will be removed silently, which will result in that this replica won’t be able to connect to primary and continue it’s streaming replication, drawing it unusable. To turn it back on, one would need to recreate the whole thing from a base backup.
For further controlling and mitigating that, Postgres, since version 9.4, has a special mechanism of Replication slots.
WAL Bloats #3 — Replication Slots
When those are used when setting up replication and a slot has gotten a connection from a replica at least once (you can think of it as “was initiated”), then in case of replica falling behind, the Primary server will keep all the needed WAL segments until said replica will connect and catch up with current state.
Or, if replica is forever gone, Primary will keep these segments forever, causing all the disk space to be used for that.
A forgotten (one without monitoring) replication slot cause not only WAL bloat but a possible database downtime.
Fortunately, it’s really easy to monitor it through the pg_replication_slots system view.
We suggest that you not only monitor for replication stots statuses but also track WAL size retained for that, as we do, for example, here:
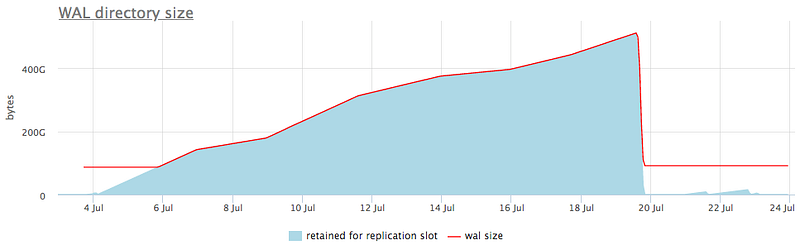
It not only shows total bloat of WAL, but in detailed view, you can see which slot causes that in particular:
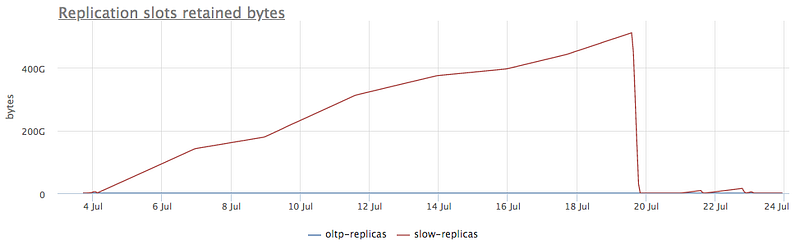
When we see which one it is, we can decide what to do about it. Either trying to fix those replicas or, if it’s not needed anymore, delete the slot.
These are the most common causes of WAL bloat, though I’m sure there are some others. It’s crucial to monitor it for the database’s uninterruptible service.
We recommend you set up such a monitoring or use one of SaaS offerings out there.
Published at DZone with permission of Pavel T. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments