Performance Differences Between Postgres and MySQL
In this article, we discuss what workload analysis and running queries can teach us about the performance differences in JSON, indexing, and concurrency.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
In the Arctype Community, we answer a lot of questions about database performance, especially between Postgres and MySQL. Performance is a vital yet complex task when managing a database. It can be affected by the configuration, the hardware, or even the design of the system. Interestingly, both PostgreSQL and MySQL are configured with compatibility and stability but depend on our database design's hardware infrastructure.
Not all relational database management systems (RDBMS) are created equal. Although PostgreSQL (or Postgres) and MySQL share some similarities, they also have unique qualities that make one a better choice over the other in specific situations. We discussed a lot of these differences in a previous post. Still, in terms of performance, they have a lot of differences.
In this article, we will discuss workload analysis and the running queries. We shall then further explain some basic configurations to improve our MySQL and PostgreSQL databases' performance. After that, we would outline some key differences between MySQL and PostgreSQL.
Table of Contents
- How to Measure Performance
- Query performance for JSON
- Indexing overhead
- Database replication and clusters
- Concurrency
- Conclusion
How To Measure Performance
MySQL has had a reputation as a fast database for read-heavy workloads, although frequently at the expense of concurrency when mixed with write operations. PostgreSQL, popularly called Postgres, presents itself as the most advanced open-source relational database, plus it's developed to be standards-compliant and feature-rich.
Previously, Postgres performance was more balanced, i.e., reads were generally slower than MySQL, but then it improved and can now write large amounts of data more efficiently, making concurrency handling better. The recent versions of MySQL and Postgres have slightly erased the performance difference between the two databases.
Using the old MyISAM engine in MySQL makes reading data extremely fast. Unfortunately, it's not readily available in recent versions of MySQL. But if using InnoDB (which allows key constraints, transactions), differences are negligible. These features are critical to enterprise or consumer-scale applications, so using the old engine is not an option. The good news is that MySQL is continuously improved to reduce the differences in heavy data writes.
A database benchmark is a reproducible experimental framework for characterizing and comparing the performance (time, memory, or quality) of database systems or algorithms on those systems. Such a practical framework defines the system under test, the workload, metrics, and experiments.
In the next 4 sections, we will discuss a few performance differences that make each database stand out.
JSON Queries Are Faster in Postgres
In this section, we see the benchmarking difference between PostgreSQL and MySQL.
Steps performed
- Create a project(Java, Node, or Ruby) where used DBs are PostgreSQL and MySQL.
- Create a sample JSON object to perform the WRITE and READ operation.
- The entire JSON object's size is assumed to be ~14 MB, creates around 200–210 entries into the database.
Statistics
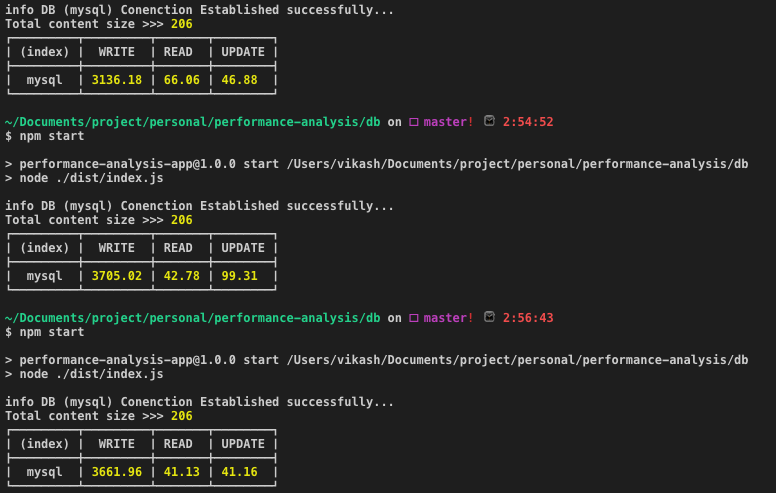
PostgreSQL: Avg time (in ms): WRITE: 2279.25 | READ: 31.65 | UPDATE: 26.26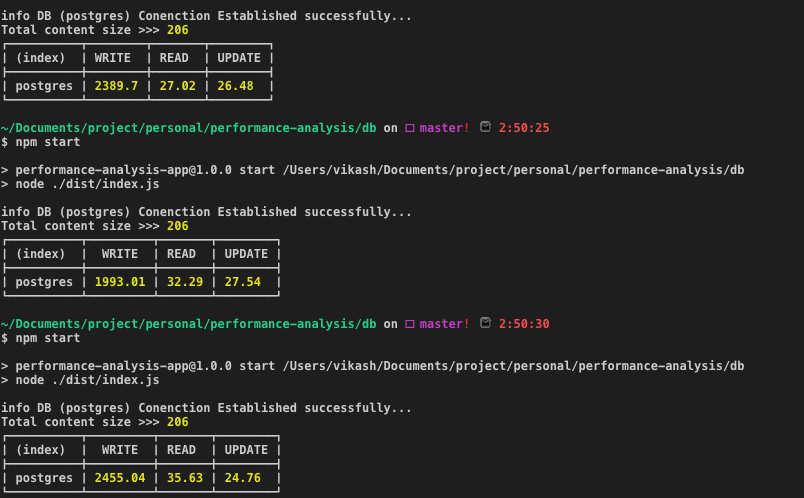
Conclusion
If we look at the numbers, it reflects that PostgreSQL is way better than MySQL if it’s a matter of dealing with JSON data type which is, of course, one of the key features of having PostgreSQL.
The frequent type of operation(READ, WRITE, UPDATE) performed in a database determines which database suits your personal or professional project. The definite conclusion from these metrics is that out of the box, while MySQL is architected to run faster than PostgreSQL, sometimes benchmarks are particular to the application.
Indexes
The index is a critical factor in all databases. It enhances database performance, as it allows the database servers to find and retrieve specific rows much faster than without an index. But, indexes add a particular overhead to the database system as a whole, so they should be used sensibly. Without an index, the database server would begin with the first row and then read through the entire table to find the relevant rows: the larger the table, the more costly the operation. Both PostgreSQL and MySQL have specific ways of handling indexes.
- Standard B Tree Indexes: PostgreSQL includes built-in support for regular B-tree and hash indexes. Indexes in PostgreSQL also support the following features:
- Expression indexes: can be created with an index of the result of an expression or function instead of a column's value.
- Partial indexes: index only a part of a table.
Let us assume we have a table in PostgreSQL named users, where each row in the table represents a user. The table is defined as follows.CREATE TABLE users ( id SERIAL PRIMARY KEY, email VARCHAR DEFAULT NULL, name VARCHAR);Now, let us assume we create the following indexes on the table above.

What is the difference between the two indexes shown above? The first index #1 is a partial index while index #2 is an expression index. As the PostgreSQL docs states,
“A partial index is built over a subset of rows in a table defined by a conditional expression (called the predicate of the partial index). The index contains entries only for those table rows that satisfy the predicate. A major reason for using a partial index is to avoid indexing commonly occurring values. Since a query searching for a commonly occurring value (one that accounts for more than a few percent of all the table rows) will run through most of the table anyway, the benefit from using an index is marginal. A better strategy is to create a partial index where such rows exclude altogether. Partial indexing reduces the index's size and hence speeds up those queries that do use the index. It will also speed up many write operations because the index does not need to update in all cases” - Documentation on Partial Indexes - Postgres Docs.
MySQL: Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are in B-trees. Exceptions include the indexes on spatial data types that use R-trees. MySQL also supports hash indexes, and the InnoDB engine uses inverted lists for FULLTEXT indexes.
Database Replication
Another performance difference, as it concerns both PostgreSQL and MySQL, is replication. Replication is the ability to copy data from one database server to another database on a different server. This distribution of information means that users can now access data without directly affecting other users. One of the difficult tasks of database replication is harmonizing data consistency across a distributed system. MySQL and PostgreSQL offer several possible options for database replication. Apart from one master to one standby and multiple standbys, PostgreSQL and MySQL offer the following replication options:
Multi-Version Concurrency Control
When users read and write to a database simultaneously, that phenomenon is known as concurrency. So, multiple clients reading and writing at the same time can lead to various edge cases/race conditions, i.e., read followed by write happened for same record X and numerous other conditions. Various modern databases make use of transactions to mitigate problems in concurrency.
Postgres was the first DBMS to rollout multi-version concurrency control (MVCC), which means reading never blocks writing and vice versa. This feature is one of the main reasons why businesses prefer Postgres to MySQL.
"Unlike most other database systems, which use locks for concurrency control, Postgres maintains data consistency by using a multi-version model. Furthermore, while querying a database, each transaction sees a snapshot of data (a database version) as it was some time ago, regardless of the underlying data's current state. It protects the transaction from viewing inconsistent data caused by (other) concurrent transaction updates on the same data rows, providing transaction isolation for each database session." Multi-Version Concurrency Control" — PostgreSQL Documentation
MVCC lets multiple readers and writers concurrently interact with the Postgres database, eliminating the need for a read-write lock every time someone interacts with the data. A side benefit is this process provides a significant efficiency boost. MySQL utilizing the InnoDB storage engine, MySQL supports writes and reads of the same row to not interfere with each other. Every time MySQL writes data into a row, it also writes an entry into the rollback segment. This data structure stores “undo logs” used to restore the row to its previous state. It’s called the “rollback segment” because it is the tool used to handle rolling back transactions.
"InnoDB is a multi-versioned storage engine: it keeps the information about old versions of changed rows to support transactional features such as concurrency and rollback. This information is stored in the tablespace in a data structure called a rollback segment (after an analogous data structure in Oracle). InnoDB uses the information in the rollback segment to perform the undo operations needed in a transaction rollback. It also uses the information to build earlier versions of a row for a consistent read." - InnoDB Multi-Versioning — MySQL MVCC
Conclusion
We have treated a few performance differences between PostgreSQL and MySQL in this post. It’s important to note that database performance relies on several other factors such as Hardware, type of OS, and most importantly, your understanding of the intended database. Both PostgreSQL and MySQL have unique qualities and drawbacks, but understanding what features would suit a project and integrating those features would ultimately result in performance.
I’d love to hear about your experience with database performance.
Published at DZone with permission of Blessing Krofegha. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments