Optimize Data Warehouse Migration Efforts by Factor of 50
This paper outlines the challenges encountered during the migration of a large data warehouse and how these challenges were tackled through innovative solutions.
Join the DZone community and get the full member experience.
Join For FreeAs technology is continuously evolving and the data processing requirements are exponentially growing, many enterprises are migrating their legacy data warehouses to the latest technologies. However, the incompatibilities between legacy and latest technologies, and the volume of workload, are posing a major impact on timelines and cost of the project.
This paper outlines the distinctive challenges encountered during the migration of a large data warehouse and details how these challenges were effectively tackled through the implementation of innovative solutions. The efforts were optimized, resulting in a significant reduction of costs by a factor of 50.
A major bank undertook a project to transition from legacy data warehouse technology to the latest platform. Primarily, the project included migrating legacy architecture involving Oracle and IBM PDOA to IBM IIAS (Db2).
The source architecture had Oracle as a landing zone, whereas the target state had Db2 as the landing zone. This posed technical complexities in integration with change data capture, which was responsible for bringing data to the landing zone, and ETLs responsible for loading data to staging.
The system was collecting data from 20 sources through 60 CDC subscriptions/tasks and there were 2000+ ETLs responsible for staging from landing. The incompatibilities between Oracle and Db2 had an impact on all of these. Refactoring 60 CDC subscriptions and 2000+ ETLs was not pragmatic, as it would have had a major impact on timeline and cost.
This paper covers the unique solutions implemented to avoid all these changes and optimize overall efforts and cost by a factor of 50.
Problem Description
The legacy architecture, as depicted in the diagram below, involved IBM Infosphere Change Data Capture (CDC) to collect data from various sources and insert it into Landing Zone in Oracle, and IBM DataStage ETLs to build Staging using data from Landing Zone and subsequently build Datamart in IBM PDOA (Db2).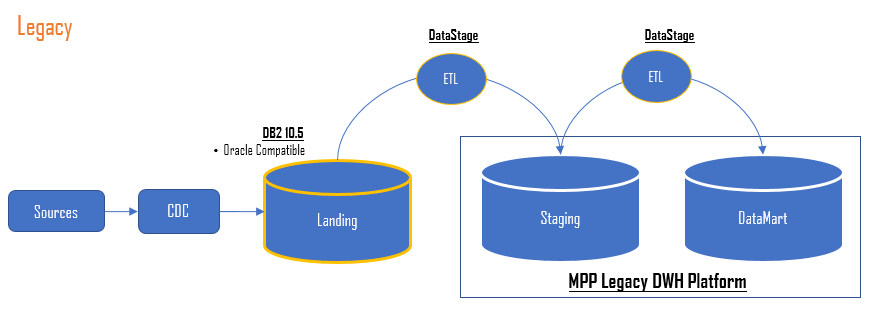
The target architecture, as depicted in the diagram below, involved IBM Infosphere Change Data Capture (CDC) to collect data from various sources and insert it into Landing Zone in IIAS (Db2), and DataStage ETLs to build Staging using data from Landing Zone and subsequently Datamart in IIAS (Db2).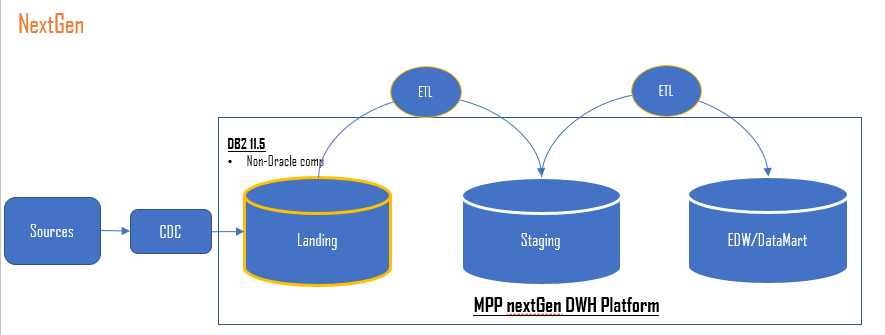
However, upon replacing Oracle with Db2, a significant portion of the ETL (Extract, Transform, Load) jobs between the landing and staging areas began to fail, resulting in substantial data discrepancies.
Mostly the issues were due to incompatibilities between Oracle and Db2. Fixing the issues warranted a change in ETL jobs. As the number of ETL jobs were 2000+ and the data volume was 600+ TB, fixing every ETL was a humongous task and led to a few person-years of effort. This was impacting overall project costs and timelines significantly.
Hence, an alternate and innovative approach was required to turn down the efforts from a couple of years to a few weeks.
This document gives a glimpse of how the incompatibility issue was handled and problems were fixed within a few weeks.
Solution Approach
At first, a detailed discovery of the existing landscape was performed and key differences between Oracle and Db2 were identified as follows:
- The difference in the behavior of 20 built-in functions
- Difference in empty string handling
- Incompatibilities in data types
- Difference in SQL syntaxes
Second, using automation scripts, instances of all these incompatibilities across all ETL jobs were identified.
The discovery and analysis revealed that the incompatibilities with built-in functions were leading to change in almost every ETL. So, the following options were evaluated:
- Manually change every ETL
- Develop automation to change every ETL
However, both were led to humongous efforts and hence an innovative approach was taken which drastically reduced efforts from a few person-years to less than four weeks.
Solution Details
The overall solution was designed and implemented using 3 features of IBM Db2 viz. Function overriding/overloading, CONNECT_PROC and FUNCTION_PATH.
The ETL jobs were heavily using 20+ built-in functions like TRANSLATE, RPAD, LPAD, etc., which were incompatible between Oracle and Db2. To address these incompatibilities, new functions were developed matching with Oracle behavior and were overridden/overloaded on built-in functions.
However, it was not straightforward due to the following challenges:
- The fix was required in read operations only of ETL and not in write operations, as the staging database didn’t have incompatibility issues.
- The functions were supposed to handle null and empty string differences as well
- Every function had specific differences
To address the first issue, CONNECT_PROC and FUNCTION_PATH features of Db2 were used to apply changes only to read users, and the other two challenges were handled in function designs.
The following sections give a step-by-step implementation:
Segregation of Read and Write Users and Accordingly Configure at ETL Level
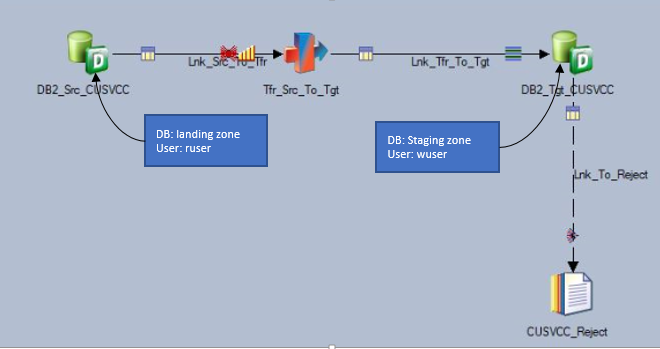
Since overridden functions were supposed to be applicable only while reading the data from the landing zone, and not while writing data into the staging zone, two separate users for reading and writing data were configured in ETL.
"user": user reading data from the landing zone."user": user writing the data to the target staging zone.![]()
Development of Overriding/Overloading Functions
Prioritized functions for override/overload based on number occurrences in ETLs, and developed functions including handling the NULL and empty string differences.
Following were the key considerations while developing overriding functions
- Developed functions for each type of data type e.g.
SUBSTRfunction was developed forCHARas wellVARCHARdata types as it was used for both the data types across all ETLs. - Kept maximum length possible for each function variable datatype to accommodate complete string from the column. e.g. length 256 for
CHARcolumn data type as the function was used for variable lengths across ETLs.
To elaborate on it in more detail, here are a few examples of functions:
SUBSTR Function
When the SUBSTR function in Db2 is used as SUBSTR (‘ABCD’, 3, 5) and if the length of the return string is greater than the length of the input string, Db2 gives the error “SQL0138N The Statement was not executed because a numeric argument of a scalar function is out of range” Whereas in Oracle it gives output i.e., ‘CD’.
This was handled by overriding the SUBSTR function which internally invokes the SUBSTRING function on attributes passed to the SUBSTR function when run by "ruser." The SUBSTRING function has intended behavior as if the length of the return string is greater than the length of the input string as SUBSTRING (‘ABCD’, 3, 5) it gives output as ‘CD’
The overridden SUBSTR function was also designed to handle NULL and empty string behavior differences between Oracle and Db2.
Sample code for SUBSTR function:
CREATE OR REPLACE FUNCTION RUSER.SUBSTR(SUB_EXPR VARCHAR(10000),SUB_POS INT, SUB_LENGTH INT)
RETURNS VARCHAR (500)
language sql
BEGIN
DECLARE SUB_VALUE VARCHAR (500);
SET SUB_VALUE=SYSIBM.SUBSTRING(SUB_EXPR, SUB_POS, SUB_LENGTH);
IF SYSIBM.LENGTH(SUB_VALUE)=0 AND SUB_VALUE='' THEN
SET SUB_VALUE=NULL;
END IF;
RETURN SUB_VALUE;
ENDTRANSLATE Function
The syntax of TRANSLATE function is different in Oracle and Db2. Function needs three arguments but between Oracle and Db2, the position of the 2nd and 3rd argument is swapped.
Oracle Syntax
TRANSLATE(char-string-exp, from-string-exp, to-string-exp,' ',pad-char-exp)DB2 Syntax
TRANSLATE(char-string-exp, to-string-exp, from-string-exp,' ',pad-char-exp)A new function with similar input and output types, but arguments 2 and 3 swapped, was developed. The sample code looks like this:
CREATE OR REPLACE FUNCTION RUSER.TRANSLATE(TRAN_EXPR VARCHAR(1000),TRAN_FROM VARCHAR(10),TRAN_TO VARCHAR(10))
RETURNS VARCHAR(1000)
language sql
BEGIN
DECLARE TRAN_VALUE VARCHAR(1000);
DECLARE CNTR_ZERO SMALLINT DEFAULT 0;
SET TRAN_VALUE=TRANSLATE(TRAN_EXPR,TRAN_TO,TRAN_FROM);
IF TRAN_VALUE='' THEN
SET TRAN_VALUE=NULL;--
END IF;--
RETURN TRAN_VALUE;
ENDLPAD Function
The LPAD function, when applied to decimal numbers having a decimal value of 0, shows different behavior between Db2 and Oracle with the results given below.
- Oracle: LPAD (1.0, 4, 0) => 0001
- DB2: LPAD (1.0, 4, 0) => 01.0
This was handled by overriding the LPAD function for decimal numbers. The new function checks if the decimal value of a given decimal number is 0 or not and if the decimal value is 0, it applies the LPAD function only to the integer part of the decimal number, else LPAD is applied to the complete decimal number.
Sample code:
CREATE OR REPLACE FUNCTION RUSER.LPAD (P_EXPP DECIMAL(25,3),P_LEN INT,P_VALUE INT)
RETURNS VARCHAR(4000)
LANGUAGE SQL
SPECIFIC TESTLPAD10
BEGIN
DECLARE RESULT_VALUE VARCHAR(50);--
DECLARE NUM_OUTPUT decimal(25,3);--
DECLARE NUM_EXPR VARCHAR(50);--
DECLARE P_EXPR VARCHAR(50);--
DECLARE C_P_EXPP BIGINT;--
SET C_P_EXPP= CAST (P_EXPP as BIGINT);
SET NUM_OUTPUT = P_EXPP - C_P_EXPP;
IF NUM_OUTPUT >0 THEN
SET P_EXPR=TRIM(BOTH '0' FROM P_EXPP);--
SET RESULT_VALUE = SYSIBM.LPAD(P_EXPR,P_LEN,P_VALUE);
ELSE
SET RESULT_VALUE = SYSIBM.LPAD(C_P_EXPP,P_LEN,P_VALUE);
END IF;--
RETURN RESULT_VALUE;--
ENDWith this approach, almost 20 Db2 build-in functions were overridden/overloaded without compromising data quality and performance.
The table below describes the list of functions and differences in behavior that were overridden.
Function Name |
Db2 (built-in) |
Oracle (over-ridden) |
Behavior changes handled |
TRANSLATE |
Translate("String",Search, Replace) |
Translate("String",Replace, Search) |
|
RPAD |
RPAD( string-expression , integer, pad) |
RPAD (string-expression , integer, pad) |
Oracle: rpad(1.0, 4, 0) => 1000 |
SUBSTR |
SUBSTR( string-expression , start , length ) |
SUBSTR (string-expression , start , length ) |
|
TO_CHAR |
TO_CHAR( string-expression) |
TO_CHAR( string-expression) |
|
and LPAD, CHAR, UPPER, SUBSTRING, REPLACE, NVL, VARCHAR, COALESCE, LEFT, RIGHT, RTRM, LTRIM, TRIM, NULLIF, TO_NUMBER, LENGTH,
|
|||
Enable Overridden/Overloaded Function to Only Read User
The last and most critical part of the solution was enabling overridden/overloaded functions for read users only.
According to the Db2 architecture, built-in functions within the SYSIBM schema are prioritized for execution. Db2 utilizes a parameter called FUNCTION_PATH to determine this preference. The default value of FUNCTION_PATH is set as "SYSIBM", "SYSFUN", "SYSPROC", "SYSIBMADM", "X" followed by the user's schema value denoted as X.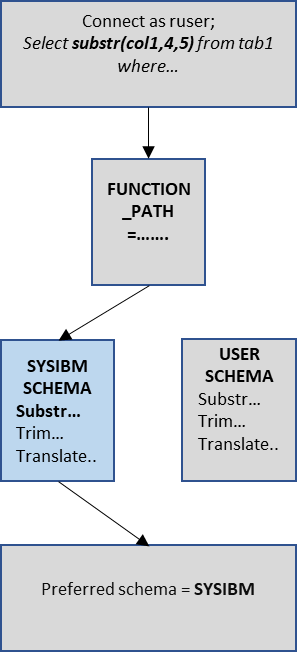
However, overridden functions reside in the user schema. Hence, in order to use overridden functions, and that to only for read user ruser, the FUNCTION_PATH value was required to be changed as and when the function is called by the read user. However, changing the value globally would have impacted write- user. Hence, another feature of Db2, called CONNECT_PROC was used.
The CONNECT_PROC is a configuration parameter and a procedure configured to this parameter is executed as and when any user connects to the database. So, a new stored procedure was created inside which a FUNCTION_PATH was set to user RUSER schema first and the procedure was configured to CONNECT_PROC parameter.
With this, as and when "ruser" connected to the database, a FUNCTION_PATH was set to use RUSER schema first and the default path was followed for other users.
The following code explains how the changing FUNCTION_PATH, only for ruser, during run-time was achieved.
db2 connect to <dbname> ; db2 update db cfg using CONNECT_PROC DB2TEST.TESTPROCCREATE or replace procedure DB2TEST.TESTPROC
LANGUAGE SQL
BEGIN
IF UPPER(SESSION_USER) = 'RUSER'
THEN
SET CURRENT FUNCTION PATH "RUSER","SYSIBM","SYSFUN","SYSPROC","SYSIBMADM";
END IF;
END
After applying this CONNECT_PROC, the order of preference for "ruser" changed dynamically as follows:
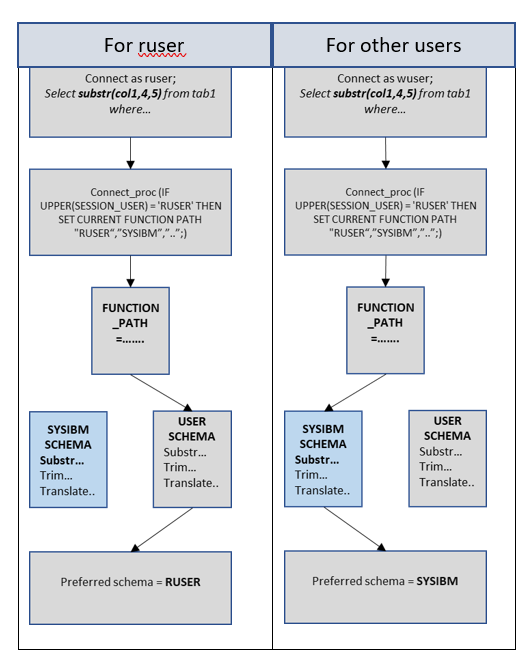
With this final change, function overriding and overloading for the incompatible built-in functions was successfully achieved for read users and avoided changes in ETL jobs.
Conclusion
Typically, in database migration projects, application code migration (applications, ETL jobs, stored procedures, triggers, functions) is considered the most complicated, and time and cost-consuming task.
While there is automation available to migrate various code objects, it does not address every challenge. In this project, the challenges were unique, looking unsurmountable due to volume, and conventional solutions were not looking feasible.
However, innovative thinking of using various features of Db2 in combination — function overriding/overloading, CONNECT_PROC and FUNCTION_PATH, resulted in an unprecedented solution and optimized overall efforts from a few persons per year to less than 4 weeks.
References
Opinions expressed by DZone contributors are their own.
Comments