Moving Data From Cassandra (OLTP) to Data Warehousing
Learn the best steps for transferring data from Cassandra to your data warehouse.
Join the DZone community and get the full member experience.
Join For FreeOverview
Data should be streamed to analytics engines in real-time or near real-time in order to incrementally upload transnational data to a data warehousing system. In my case, my OLTP is Cassandra and OLAP is Snowflake. The OLAP system requires data from Cassandra on a periodic basis. Requirements pertaining to this scenario are:
- The frequency of the data copy needs to be reduced drastically.
- Data has to be consistent. Cassandra and Snowflake should be in sync.
- In a few cases, all mutations have to be captured
- Currently, production cluster data size is in petabytes; hourly at least 100 gigabytes of data is generated.
With such a granularity requirement, one should not copy the data from an OLTP system to OLAP, as it would be invasive to read the path, and writing the path of Cassandra would result in an impinge on TPS. Thus, we are required to provide a different solution for copying the Cassandra data to Snowflake.
Copying entire data (which is in Terabytes) would be very inefficient and would not provide any benefits, as the sole expectation is to apply all new Cassandra mutations on Snowflake.
OLTP Ecosystem
- The entire OLTP follows microservice architecture.
- We have implemented a database-per-service approach.
- On the OLTP side, graph-ql is used to transfer data from Cassandra.
- Each microservice follows repository design patterns.
Potential Solutions
We considered the following solutions. Here are their summaries.
No |
Solution |
Pros |
Cons |
1. |
Using Cassandra Trigger to capture all the mutations in Cassandra. All of the changes are to be pushed to Kafka, and Spark jobs will consume the data and apply the changes on Snowflake. |
Each and every change gets applied to Snowflake. Delta can be captured and data gets uploaded incrementally to Snowflake. |
This will put an enormous load on the Cassandra cluster. Also, it cannot be designed as per intelligent rate-limiting that is based on the cluster load intelligently buffering the changes before pushing to Kafka. |
2. |
Adding a timestamp in each table and updating its value for each operation. |
Delta can be captured by using a range query. In order to do so, use the last_query_timestmap value stored on the ETL pipeline. This is extremely non-invasive to write path and read path as delta can be captured by using a range query. Based on the frequency, a range query can be fired to retrieve the new modified rows and inserted rows. |
The current schema does not have a timestamp column across all the microservices. This demands a change in the existing application code. Deleting the operation is not captured. For instance, if there is any delete or truncate operation, the subsequent operation will not be applied to Snowflake. This leads to a data consistency issue. |
3. |
Using Kafka partition-offset to identify the delta. Each domain entity will be mapped to different Kafka topic. Cassandra clustering column id is used as a partition id of the Kafka topic. The last offset will hold the data that was synced latest. Each domain microservice will then have to identify which delta has to be pushed to the Kafka topic. |
Each upsert is captured. This is extremely non-invasive to write path and read path as delta can be captured by using a range query. Based on the frequency, a range query can be fired to retrieve the new modified rows and inserted rows. Frequency can be changed on the fly. |
This approach cannot capture the delete and truncate operations. Each domain microservice will have to own the push data mechanism. This implies that there are code changes in the transnational system. Any change in the domain entity may end up in a code change, Kafka topic structural change, or a client code change (spark job). |
4. |
Pushing mutations (insert, update, and delete) to Cassandra as well as Kafka. This occurs whenever a service is making changes on Cassandra, thus pushing the operations to Kafka. Spark jobs in turn will consume the messages and apply the transformation on Snowflake. |
Each mutation will be captured. |
A microservice will have to own this arrangement. Whenever there is a Cassandra operation, the microservice will have to push the message on to the Kafka. There is a potential issue in which Cassandra's operation might be successful and Kafka's message would then be lost. There are many combinations that can lead to data integrity issues. This will put stress on the microservice, as a particular API invocation there can be multiple Cassandra operations. We could have used event-sourcing and written to Kafka first. This results in a "read your writes" problem. |
5. |
Using Cassandra Change Data Capture (Cassandra - CDC). |
Each mutation will be captured. This is extremely non-invasive to write path and read path, as CDC works on commit log design. In Cassandra, CDC captures the operations performed in recent times and dumps all the data as logs into CDC logs. There is no impact to the transnational system, as Cassandra offers this feature out of the box. |
This feature is available in Cassandra 3.8 onward. Currently, our cluster is using Cassandra 3.7. In any case, our upgrade to the latest Cassandra version is pending. Until the upgrade is done, our analytics team will have to linger on using the current approach of copying the data. Unlike Oracle/Mysql/Sqlserver CDC, Cassandra CDC can be unreliable. Any operation on Cassandra is captured as an event. CDC does not grantee event duplication and event ordering. This has to be done in the client code. |
6. |
Using incremental backup - capturing a snapshot. This approach relies upon the periodic snapshot of Cassandra and uploading the snapshot to Snowflake. |
There is a guarantee that OLTP and OLAP data will be in sync. This is extremely non-invasive to write path and read path with one caveat - a snapshot is captured not on demand but on the basis of load on the system. |
As our sink is not Cassandra (its Snowflake), applying snapshot is not a straightforward operation. There is a requirement to maintain the small Cassandra cluster that can hold the data as a buffer. |
7. |
Cassandra In Sync Replication Cluster The idea is to replicate data in asynchronous fashion from OLTP cluster to a new cluster - analytics data cluster. This is done by Cassandra out of the box. As data is being replicated in async fashion, the probability of having any stress on the OLTP cluster is minimal. From the Cassandra analytics cluster, data is to be copied to Snowflake. |
This is the most reliable and simplest approach. NetworkTopologyStrategy guarantees non-invasive replication, and backup of data can be created in different geographies. |
This puts additional burden on the infrastructure cost - additional Cassandra cluster, data transfer (possibly over the network to a different AZ). The biggest downside is the inability to capture the delta. Every time all of the data needs to be copied from the replication cluster to Snowflake. One can not add triggers to the replication cluster, as those triggers would be copied to the OLTP cluster. Data from the replication cluster can not be truncated, as that operation would be applied to the OLTP cluster. |
8. |
Using Data Stax Enterprise system. Adopting this approach would be highly disruptive, as it would affect the entire reporting and analytics engine. Another important factor is license costs. It is way out of scope. This approach was not even discussed after a certain extent. |
Its a comprehensive suite of solutions - backup, restore, analytics, monitoring, and management |
Out of scope Datastax vendor specific Expensive |
In case of your analytics engine is based on Cassandra, use approach five through eight. In case the OLTP system is designed from scratch, use approaches one, two, or four.
However, many solutions fade away drastically when you have existing running OLTP and OLAP systems. We require a generic and non-invasive solution that does not require any change in the existing systems (including microservice implementation and domain data model). We narrowed down the approaches to CDC and Incremental backup plus snapshot. In reality, these are generic options for applying OLTP mutations on OLAP. In general, the CDC approach would have worked, as it provides a precise level of granularity when it comes to data replication as each operation is captured and can be performed on the target system. This is applicable to the entire RDBMS world and NoSQL solutions such as MongoDB and InfluxDB. However, CDC in Cassandra is very basic and currently has many open issues.
Cassandra CDC
Change Data Capture (CDC) logging captures and tracks data that has changed. CDC logging is configured per table, with limits on the amount of disk space to consume for storing the CDC logs. CDC logs use the same binary format as the commit log. The generic architecture includes Kafka as a CDC audit replication log and a CDC connector such as Debezium. However, as per current Cassandra implementation, the CDC feature has many issues such as event duplication and event out of order. Because of these issues, CDC's reliability is not 100%. Cassandra documentation explicitly states that client program/CDC log consumer has to handle the issues and require to do employ techniques used by Cassandra to achieve reliability, techniques such as last write wins, timestamp collisions, and so on. Currently, there are no third-party tools that provide such functionality. Debezium and Uber's DBEvents are two promising projects that address CDC needs; however there Cassandra CDC connector is still in its incubation phase. As per Cassandra 4.x road map, there is no plan to improve the reliability of the CDC feature. The current issues of CDC require complex engineering and require significant efforts to grantee high data quality and freshness. That's why this approach has been discarded.
Cassandra in Sync Replication Cluster
This approach is generic. The approach spins up another Cassandra cluster (OLAP) and uses Cassandra's multi-DC replication feature to replicate data live to this cluster. This cluster should be very small and the replication factor should be one, as this cluster acts as the intermediary data store. These two clusters will be in sync and differ in terms of replication factor and nodes. OLTP cluster will use the consistency level of local.quorum and the microservice application instances will be aware of only these Cassandra nodes. So, there is no change in the status quo.
Spark jobs that use the OLTP cluster to copy data to Snowflake will point to a replication cluster. The biggest downside of this approach for us is the fact that these two clusters are mirror copies of each other. So, whatever operations user performs on the replication cluster gets applied to the production cluster; the replication cluster data then cannot be truncated and triggers cannot be added.
This also implies that the replication cluster will keep the entire copy of the production data. For example, if RF on the production cluster is three and replication cluster RF is one, then the replication cluster size will be one-third of the production cluster. This proportion remains approximately the same for cost. Another downside is the fact that the entire copy of the data has to be uploaded to the data warehousing for each use.
This is an overhead, as general analytics data is append-only. So, it is not a sensible approach to copy such a large data repository. As time passes, the size of the data will be petabytes — imagine the computing power required to copy the data. That's why even though the approach is enticing and easy to adopt with little maintenance overhead, it has major disadvantages.
Incremental Back-up Plus Snapshot
Finally, we were left with this approach. In Cassandra, snapshot and incremental backup features are really solid. The original purpose of these features was to support backup. Restores from backups are unnecessary in the event of disk or system hardware failure even if an entire active site goes off-line. As long as there is one node with the replicated data, Cassandra can recover that data without any reliance on the external source. In Cassandra, capturing the snapshot is not a write or read invasive operation. Cassandra provides a native node-level snapshot option via the node tool command. Snapshot creates a hard link to existing Cassandra data files. Thisis used with the incremental backup feature that provides the capability of point in time restore. The granularity can be fine-tuned to 10 to 15 minutes. However, this is not near real-time data replication. You can not achieve the preciseness and granularity of few seconds or two to five minutes with this approach. If this is the requirement, then I would recommend to go ahead with the previous approach of in sync replication at the cost of infrastructure expenses.
In general, the analytics engine requirement is to receive the delta from the production cluster on a periodic basis. That's how most data warehousing solutions work. Our business requirements currently states that we receive the delta from production cluster every day. In the future, we would like to support hourly frequency. Considering the cost factor and business requirements, this approach wins handsdown.
The following subsection explains the high-level design of the approach.
The data folder contains a subfolder for each keyspace. Each subfolder contains three kinds of files:
Data files: A SSTable (Sorted Strings Table) is a file of key-value string pairs (sorted by keys).
Index file: (Key, offset) pairs (points into data file)
Bloom filter: all keys in the data file
The incremental backup operation captures all of the mutations, including deletions. As per our requirement, we need to capture delete mutations only in the case of agent keyspace. For other keyspaces, we are not concerned with deletions. In fact, on most of the keyspaces, we do not have to delete the data. When it comes to the replication cluster, it is not essential to keep all of the data. Once the Spark job is triggered, you can query the keyspace to get data and then can upload the data to Snowflake.
Once this upload is finished, you can execute a truncate command on the keyspace to ensure that data size remains under a certain limit. For incremental backup, only a schema is required. So, if a schema is intact, then the incremental backup can simply keep on loading the delta, and Spark jobs will continue copying the entire data in the keyspace to Snowflake.
In the case that all of the mutations are required to be captured, old data is required. This is expanded upon in the flowchart attached below. Spark jobs will be required to copy and truncate the data. From there, it’s easy to do configuration per keyspace. In cases in which deletion mutations are required, all of the data has to be preserved. So the curious case of copying keyspace data to Snowflake still exists. However, it can be easily solved, as in this cluster and for keyspaces in question, triggers can be enabled. Once triggers are enabled, each batch of mutations will trigger an event. The fact that Cassandra triggers can be implemented in programs also helps.
One of the important design decisions is to ensure that Spark jobs copy data from the production cluster to the replication cluster and then migrate the data from the replication cluster to Snowflake the jobs do not execute in parallel. In that case, there is a chance of data contention issues, as multiple writers and mutations occur. In order to avoid any such situations, the Spark scheduler must be used. Spark scheduler configuration will ensure that these two jobs are not executed in parallel.
AWS deployment is as follows:
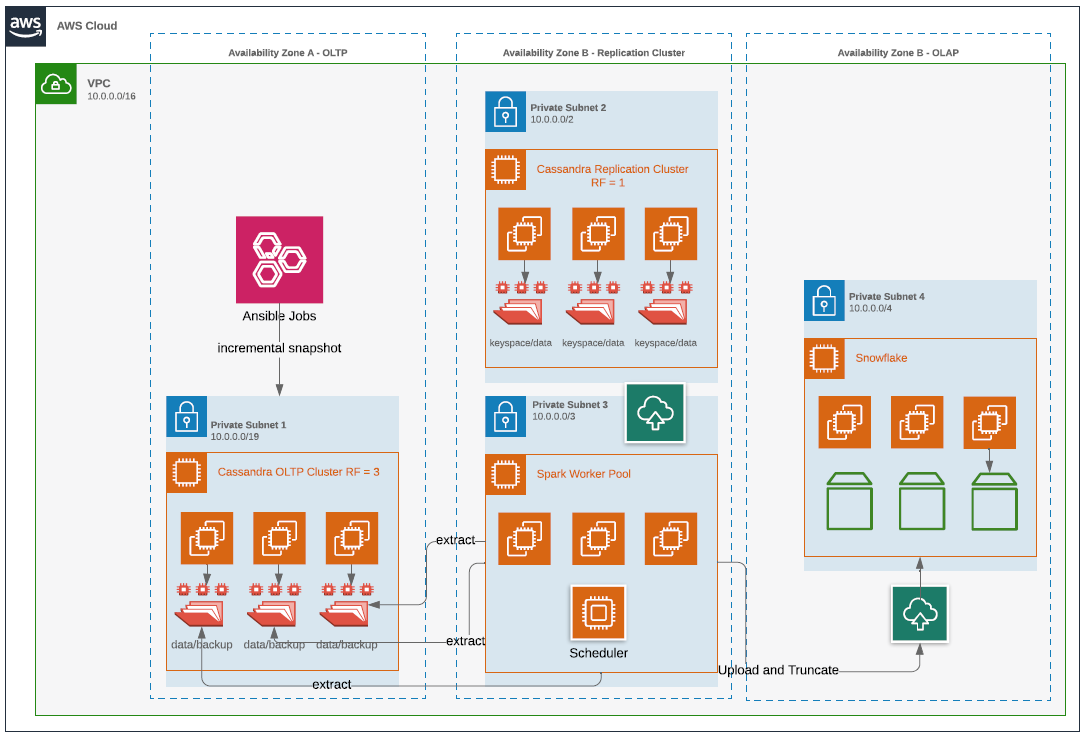
The following flow chart summarizes the entire approach.

Opinions expressed by DZone contributors are their own.
Comments