Monolith to Modular — Part 4: Sizing and Estimating Scope
Learn how to estimate and plan for the scope of your microservices application when migrating from a monolithic codebase.
Join the DZone community and get the full member experience.
Join For FreeModule extractions with many tens or hundreds of violations to resolve will benefit from preparatory planning and estimation.
This is the fourth post in a series that will explore the challenges of migrating a monolithic code base to a modular architecture
Series links:
Post 1 – Migrating from Monolith to Modular
Post 2 – Monolith to Modular – The Extract Module Use Case
Post 3 – Monolith to Modular – Managing Violations
Post 4 – Monolith to Modular – Sizing and Estimating Scope (this post)
In our previous post, we described how to identify, manage and resolve dependencies that violate a target architecture. In this post, we describe the use of violating dependency details to size and scope the refactoring effort.
In the example levelized structure diagram below, three packages have cyclic dependencies.

Attempts to move code responsible for remote communication into a new comms module resolves the feedback dependency from seaview to assemblies. But another is created from assemblies to comms which prevents the creation of the new module (the dotted arrow).

In the following levelized structure diagram, the feedback dependency is selected (highlighted in blue) and the details of the interfaces, classes, and members that comprise the dependency are shown in the breakout beneath. This list of code constructs causing the feedback dependency shows the size and scope of the refactoring needed to resolve it. In this example, there are 40 references contributing to the feedback dependency.
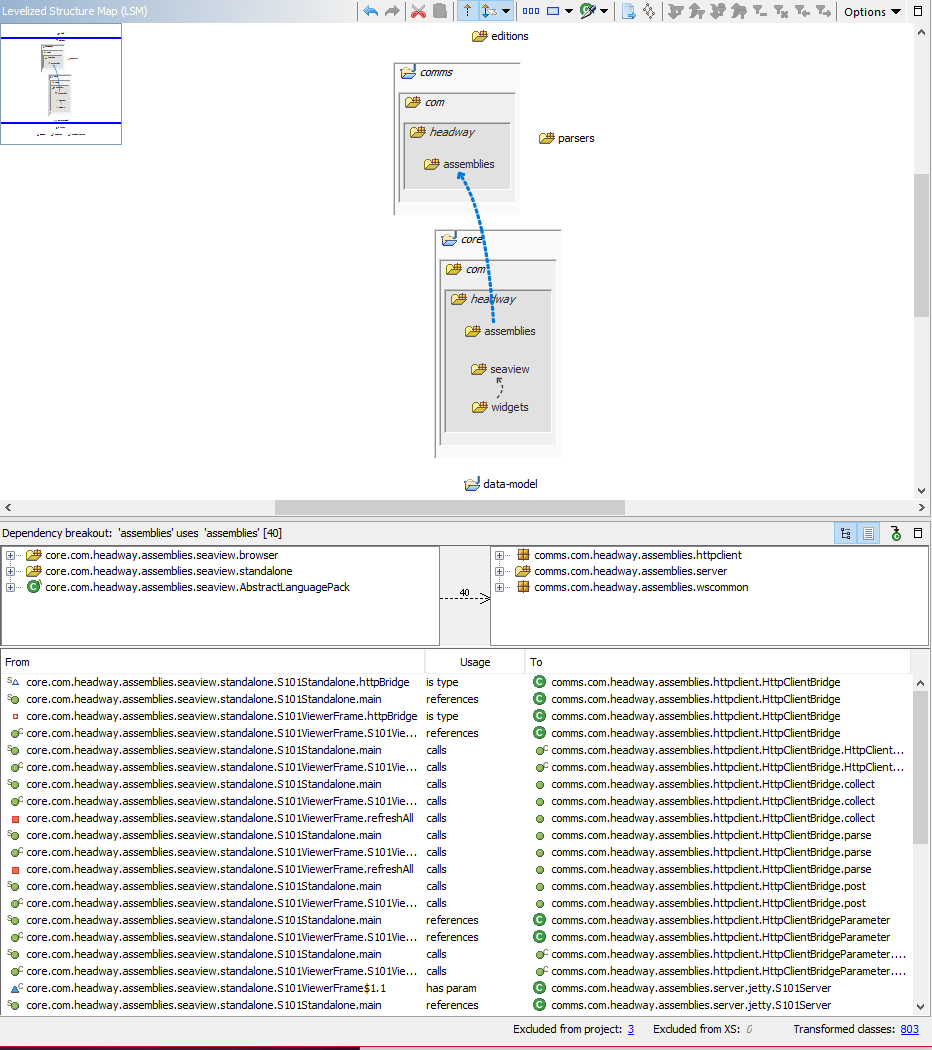
It might be tempting to bulk import a story per dependency into an agile planning tool, but careful grouping of the violations will yield fewer stories and a shorter time to deliver them. The number and nature of the stories is driven by the type of the dependencies and how they are to be fixed and tested, and by whom:
- Will the fix be at the from or to end of the dependency – or both?
- Which team is responsible for the code that will be refactored?
- Will the refactoring be done by incorporating the stories into a team’s existing backlog?
- Or is there a re-engineering team in place tasked with the dependency removal?
- How will the changes be tested?
The detailed dependency list can be imported into a spreadsheet. Use this raw list as input to the backlog creation. Ordering by the "from" or "to" columns helps to identify dependencies that can be grouped together into a single story.

Structural refactoring should have no effect on application functionality. The only way to test the changes is through regression testing. If the application does not have an automated regression suite the cost of manual testing can far exceed the cost of changing the code. The worst case scenario is one in which the velocity of the team is determined not by the code changes but by the manual regression testing effort.
Example of Test Impact
As an example, consider the situation where a method in an implementation class is being called directly. The method isn’t suitable for inclusion in the interface because it exposes the module’s internal model in the return type. A new method with a suitable new class for the return type must be implemented which delegates to the existing method and converts the internal model to the new return type. The first violation probably appeared when a developer under pressure to deliver a change in functionality took the shortcut of referencing the implementation class, rather than implementing the delegating method. Once it exists, other calls to the method can appear across the code base. Another developer under pressure takes the same shortcut or worse, blindly copies the call to the implementation class.
One option is to group all of these calls together in a single story. When playing the story the developer will implement the missing delegating method and then refactor all the offending code to use the interface and its new method. But if the calls are spread across the code base this one story could affect many different areas of functionality. Without an automated test suite, such a change would result in a significant manual testing effort.
So another option is to group violations into stories for each functional area. A story to implement the delegating method must be played first. When sprints are planned, the stories affecting the same functional area are played together such that many changes can be regression tested together.
Summary
Whichever way the work is partitioned up and assigned to developers, each story should be a discrete piece of work that can be completed and deployed independently. This allows the stories to be played at a pace to suit the team(s) involved. Should priorities change the refactoring can be halted without losing any stories already played.
You can see a worked example of Extract Module in this blog post. If you are interested in seeing how your software project looks in Structure101 Studio or Workspace, download a free trial.
Opinions expressed by DZone contributors are their own.
Comments