Monitoring Generative AI Applications in Production
A comprehensive approach for monitoring Generative AI applications in production, combining infrastructure performance tracking with proactive content analysis.
Join the DZone community and get the full member experience.
Join For FreeGenerative AI (GenAI) and Large Language Models (LLMs) offer transformative potential across various industries. However, their deployment in production environments faces challenges due to their computational intensity, dynamic behavior, and the potential for inaccurate or undesirable outputs. Existing monitoring tools often fall short of providing real-time insights crucial for managing such applications. Building on top of the existing work, this article presents the framework for monitoring GenAI applications in production. It addresses both infrastructure and quality aspects.
On the infrastructure side, one needs to proactively track performance metrics such as cost, latency, and scalability. This enables informed resource management and proactive scaling decisions. To ensure quality and ethical use, the framework recommends real-time monitoring for hallucinations, factuality, bias, coherence, and sensitive content generation.
The integrated approach empowers developers with immediate alerts and remediation suggestions, enabling swift intervention and mitigation of potential issues. By combining performance and content-oriented monitoring, this framework fosters the stable, reliable, and ethical deployment of Generative AI within production environments.
Introduction
The capabilities of GenAI, driven by the power of LLMs, are rapidly transforming the way we interact with technology. From generating remarkably human-like text to creating stunning visuals, GenAI applications are finding their way into diverse production environments. Industries are harnessing this potential for use cases such as content creation, customer service chatbots, personalized marketing, and even code generation. However, the path from promising technology to operationalizing these models remains a big challenge[1].
Ensuring the optimal performance of GenAI applications demands careful management of infrastructure costs associated with model inference, cost, and proactive scaling measures to handle fluctuations in demand. Maintaining user experience requires close attention to response latency. Simultaneously, the quality of the output generated by LLMs is of utmost importance. Developers must grapple with the potential for factual errors, the presence of harmful biases, and the possibility of the models generating toxic or sensitive content. These challenges necessitate a tailored approach to monitoring that goes beyond traditional tools.
The need for real-time insights into both infrastructure health and output quality is essential for the reliable and ethical use of GenAI applications in production. This article addresses this critical need by proposing solutions specifically for real-time monitoring of GenAI applications in production.
Current Limitations
The monitoring and governance of AI systems have garnered significant attention in recent years. Existing literature on AI model monitoring often focuses on supervised learning models [2]. These approaches address performance tracking, drift detection, and debugging in classification or regression tasks. Research in explainable AI (XAI) has also yielded insights into interpreting model decisions, particularly for black-box models [3]. This field seeks to unravel the inner workings of these complex systems or provide post-hoc justifications for outputs [4]. Moreover, studies on bias detection explore techniques for identifying and mitigating discriminatory patterns that may arise from training data or model design [5].
While these fields provide a solid foundation, they do not fully address the unique challenges of monitoring and evaluating generative AI applications based on LLMs. Here, the focus shifts away from traditional classification or regression metrics and towards open-ended generation. Evaluating LLMs often involves specialized techniques like human judgment or comparison against reference datasets [6]. Furthermore, standard monitoring and XAI solutions may not be optimized for tracking issues prevalent in GenAI, such as hallucinations, real-time bias detection, or sensitivity to token usage and cost.
There has been some recent work in helping solve this challenge [8], [9]. This article builds upon prior work in these related fields while proposing a framework designed specifically for the real-time monitoring needs of production GenAI applications. It emphasizes the integration of infrastructure and quality monitoring, enabling the timely detection of a broad range of potential issues unique to LLM-based applications.
This article concentrates on monitoring Generative AI applications utilizing model-as-a-service (MLaaS) offerings such as Google Cloud's Gemini, OpenAI's GPTs, Claude on Amazon Bedrock, etc. While the core monitoring principles remain applicable, self-hosted LLMs necessitate additional considerations. These include model optimization, accelerator (e.g. GPU) management, infrastructure management, scaling, etc - factors outside the scope of this discussion. Also, this article focuses on text-to-text models, but the principles can be extended to other modalities as well. The subsequent sections will focus on various metrics, techniques, and architecture for capturing those metrics to gain visibility into LLM's behavior in production.
Application Monitoring
Monitoring the performance and resource utilization of Generative AI applications is vital for ensuring their optimal functioning and cost-effectiveness in production environments. This section delves into the key components of application monitoring for GenAI, specifically focusing on cost, latency, and scalability considerations.
Cost Monitoring and Optimization
The cost associated with deploying GenAI applications can be significant, especially when leveraging MLaaS offerings. Therefore, granular cost monitoring and optimization are crucial. Below are some of the key metrics to focus on:
Granular Cost Tracking
MLaaS providers typically charge based on factors such as the number of API calls, tokens consumed, model complexity, and data storage. Tracking costs at this level of detail allows for a precise understanding of cost drivers. For MLaaS LLMs, input and output characters/token count can be the key driver of cost. Most models have tokenizer APIs to count the characters/tokens for any given text. These APIs can help understand usage for monitoring and optimizing inference costs. Below is an example of generating a billable character count for Google Cloud’s Gemini model.
import vertexai
from vertexai.generative_models import GenerativeModel
def generate_count(project_id: str, location: str) -> str:
# Initialize Vertex AI
vertexai.init(project=project_id, location=location)
# Load the model
model = GenerativeModel("gemini-1.0-pro")
# prompt tokens count
count = model.count_tokens("how many billable characters are here?"))
# response total billable characters
return count.total_billable_characters
generate_count('your-project-id','us-central1')Usage Pattern Analysis and Token Efficiency
Analyzing token usage patterns plays a pivotal role in optimizing the operating costs and user experience of GenAI applications. Cloud providers often impose token-per-second quotas, and consistently exceeding these limits can degrade performance. While quota increases may be possible, there are often hard limits. Creative resource management may be required for usage beyond these thresholds. A thorough analysis of token usage over time helps identify avenues for cost optimization. Consider the following strategies:
- Prompt optimization: Rewriting prompts to reduce their size reduces token consumption and should be a primary focus of optimization efforts.
- Model tuning: A model fine-tuned on a well-curated dataset can potentially deliver similar or even superior performance with smaller prompts. While some providers charge similar fees for base and tuned models, premium pricing models for tuned models also exist. One needs to be cognizant of these, before making a decision. In certain cases, model tuning can significantly reduce token usage and associated costs.
- Retrieval-augmented generation: Incorporating information retrieval techniques can help reduce input token size by strategically limiting the data fed into the model, potentially reducing costs.
- Smaller model utilization: When a smaller model is used in tandem with high-quality data, not only can it achieve comparable performance to a larger model, but it offers a compelling cost-saving strategy too.
The token count analysis code example provided earlier in the article can be instrumental in understanding and optimizing token usage. It's worth noting that pricing models for tuned models vary across MLaaS providers, highlighting the importance of careful pricing analysis during the selection process.
Latency Monitoring
In the context of GenAI applications, latency refers to the total time elapsed between a user submitting a request and receiving a response from the model. Ensuring minimal latency is crucial for maintaining a positive user experience, as delays can significantly degrade perceived responsiveness and overall satisfaction. This section delves into the essential components of robust latency monitoring for GenAI applications.
Real-Time Latency Measurement
Real-time tracking of end-to-end latency is fundamental. This entails measuring the following components:
- Network latency: Time taken for data to travel between the user's device and the cloud-based MLaaS service.
- Model inference time: The actual time required for the LLM to process the input and generate a response.
- Pre/post-processing overhead: Any additional time consumed for data preparation before model execution and formatting responses for delivery.
Impact on User Experience
Understanding the correlation between latency and user behavior is essential for optimizing the application. Key user satisfaction metrics to analyze include:
- Bounce rate: The percentage of users who leave a website or application after viewing a single interaction.
- Session duration: The length of time a user spends actively engaged with the application.
- Conversion rates: (When applicable) The proportion of users who complete a desired action, such as a purchase or sign-up.
Identifying Bottlenecks
Pinpointing the primary sources of latency is crucial for targeted fixes. Potential bottleneck areas warranting investigation include:
- Network performance: Insufficient bandwidth, slow DNS resolution, or network congestion can significantly increase network latency.
- Model architecture: Large, complex models may have longer inference times. Many times using smaller models, with higher quality data and better prompts can help yield necessary results.
- Inefficient input/output processing: Unoptimized data handling, encoding, or formatting can add overhead to the overall process.
- MLaaS platform factors: Service-side performance fluctuations on the MLaaS platform can impact latency.
Proactive latency monitoring is vital for maintaining the responsiveness and user satisfaction of GenAI applications in production environments. By understanding the components of latency, analyzing its impact on user experience, and strategically identifying bottlenecks, developers can make informed decisions to optimize their applications.
Scalability Monitoring
Production-level deployment of GenAI applications necessitates the ability to handle fluctuations in demand gracefully. Regular load and stress testing are essential for evaluating a system's scalability and resilience under realistic and extreme traffic scenarios. These tests should simulate diverse usage patterns, gradual load increases, peak load simulations, and sustained load. Proactive scalability monitoring is critical, particularly when leveraging MLaaS platforms with hard quota limits for LLMs. This section outlines key metrics and strategies for effective scalability monitoring within these constraints.
Autoscaling Configuration
Leveraging the autoscaling capabilities provided by MLaaS platforms is crucial for dynamic resource management. Key considerations include:
- Metrics: Identify the primary metrics that will trigger scaling events (e.g., response time, API requests per second, error rates). Set appropriate thresholds based on performance goals.
- Scaling policies: Define how quickly resources should be added or removed in response to changes in demand. Consider factors like the time it takes to spin up additional model instances.
- Cooldown periods: Implement cooldown periods after scaling events to prevent "thrashing" (rapid scaling up and down), which can lead to instability and increased costs.
Monitoring Scaling Metrics
During scaling events, meticulously monitor these essential metrics:
- Response time: Ensure that response times remain within acceptable ranges, even when scaling, as latency directly impacts user experience.
- Throughput: Track the system's overall throughput (e.g., requests per minute) to gauge its capacity to handle incoming requests.
- Error rates: Monitor for any increases in error rates due to insufficient resources or bottlenecks that can arise during scaling processes.
- Resource utilization: Observe CPU, memory, and GPU utilization to identify potential resource constraints.
MLaaS platforms' hard quota limits pose unique challenges for scaling GenAI applications. Strategies to address this include:
- Caching: Employ strategic caching of model outputs for frequently requested prompts to reduce the number of model calls.
- Batching: Consolidate multiple requests and process them in batches to optimize resource usage.
- Load balancing: Distribute traffic across multiple model instances behind a load balancer to maximize utilization within available quotas.
- Hybrid deployment: Consider a hybrid approach where less demanding requests are served by MLaaS models, and those exceeding quotas are handled by a self-hosted deployment (assuming the necessary expertise).
Proactive application monitoring, encompassing cost, latency, and scalability aspects, underpins the successful deployment and cost-effective operation of GenAI applications in production. By implementing the strategies outlined above, developers and organizations can gain crucial insights, optimize resource usage, and ensure the responsiveness of their applications for enhanced user experiences.
Content Monitoring
Ensuring the quality and ethical integrity of GenAI applications in production requires a robust content monitoring strategy. This section addresses the detection of hallucinations, accuracy issues, harmful biases, lack of coherence, and the generation of sensitive content.
Hallucination Detection
Mitigating the tendency of LLMs to generate plausible but incorrect information is paramount for their ethical and reliable deployment in production settings. This section delves into grounding techniques and strategies for leveraging multiple LLMs to enhance the detection of hallucinations.
Human-In-The-Loop
To address the inherent issue of hallucinations in LLM-based applications, the human-in-the-loop approach offers two key implementation strategies:
- End-user feedback: Incorporating direct feedback mechanisms, such as thumbs-up/down ratings and options for detailed textual feedback, provides valuable insights into the LLM's output. This data allows for continuous model refinement and pinpoints areas where hallucinations may be prevalent. End-user feedback creates a collaborative loop that can significantly enhance the LLM's accuracy and trustworthiness over time.
- Human review sampling: Randomly sampling a portion of LLM-generated outputs and subjecting them to rigorous human review establishes a quality control mechanism. Human experts can identify subtle hallucinations, biases, or factual inconsistencies that automated systems might miss. This process is essential for maintaining a high standard of output, particularly in applications where accuracy is paramount.
Implementing these HITL strategies fosters a symbiotic relationship between humans and LLMs. It leverages human expertise to guide and correct the LLM, leading to progressively more reliable and factually sound outputs. This approach is particularly crucial in domains where accuracy and the absence of misleading information are of utmost importance.
Grounding in First-Party and Trusted Data
Anchoring the output of GenAI applications in reliable data sources offers a powerful method for hallucination detection. This approach is essential, especially when dealing with domain-specific content or scenarios where verifiable facts are required. Techniques include:
- Prompt engineering with factual constraints: Carefully construct prompts that incorporate domain-specific knowledge, reference external data, or explicitly require the model to adhere to a known factual context. For example, a prompt for summarizing a factual document could include instructions like, "Restrict the summary to information explicitly mentioned in the document.

- Retrieval Augmented Generation: Augment LLMs using trusted datasets that prioritize factual accuracy and adherence to provided information. This can help reduce the model's overall tendency to fabricate information.
- Incorporating external grounding sources: Utilize APIs or services designed to access and process first-party data, trusted knowledge bases, or real-world information. This allows the system to cross-verify the model's output and flag potential discrepancies. For instance, a financial news summarization task could be coupled with an API that provides up-to-date stock market data for accuracy validation.
- LLM-based output evaluation: The unique capabilities of LLMs can be harnessed to evaluate the factual consistency of the generated text. Strategies include:
- Self-consistency check: This can be achieved through multi-step generation, where a task is broken into smaller steps, and later outputs are checked for contradictions against prior ones. For instance, asking the model to first outline key points of a document and then generate a full summary allows for verification that the summary aligns with those key points. Alternatively, rephrasing the original prompt in different formats and comparing the resulting outputs can reveal inconsistencies indicative of fabricated information.
- Cross-model comparison: Feed the output of one LLM as a prompt into a different LLM with potentially complementary strengths. Analyze any inconsistencies or contradictions between the subsequent outputs, which may reveal hallucinations.
![]()
- Metrics for tracking hallucinations: Accurately measuring and quantifying hallucinations generated by LLMs remains an active area of research. While established metrics from fields such as information retrieval and classification offer a foundation, the unique nature of hallucination detection necessitates the adaptation of existing metrics and the development of novel ones. This section proposes a multi-faceted suite of metrics, including standard metrics creatively adapted for this context as well as novel metrics specifically designed to capture the nuances of hallucinated text. Importantly, I encourage practitioners to tailor these metrics to the specific sensitivities of their business domains. Domain-specific knowledge is essential in crafting a metric set that aligns with the unique requirements of each GenAI deployment.

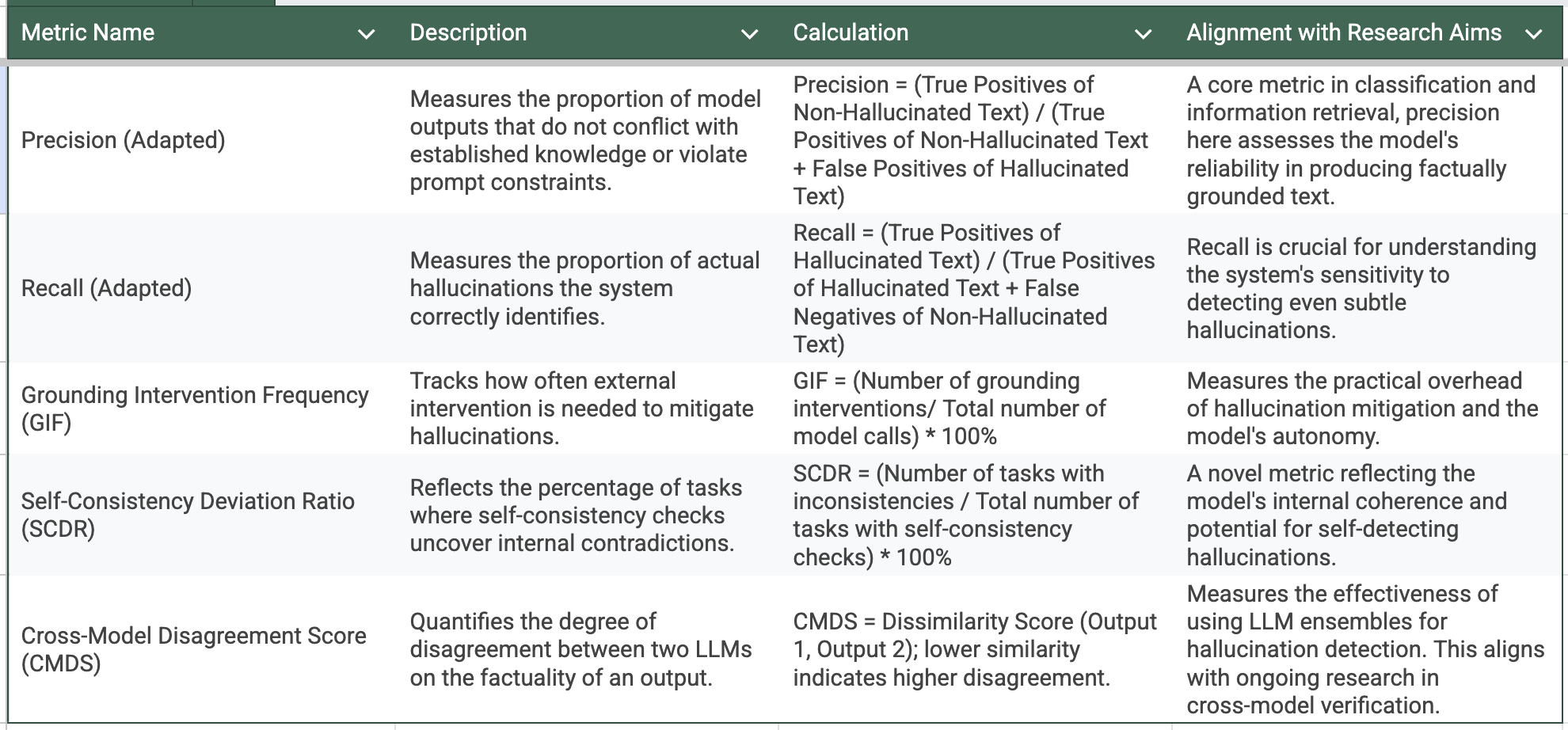
Considerations and Future Directions
Specificity vs. Open-Endedness
Grounding techniques can be highly effective in tasks requiring factual precision. However, in more creative domains where novelty is expected, strict grounding might hinder the model's ability to generate original ideas.
Data Quality
The reliability of any grounding strategy depends on the quality and trustworthiness of the external data sources used. Verification against curated first-party data or reputable knowledge bases is essential.
Computational Overhead
Fact-checking, data retrieval, and multi-model evaluation can introduce additional latency and costs that need careful consideration in production environments.
Evolving Evaluation Techniques
Research into the use of LLMs for semantic analysis and consistency checking is ongoing. More sophisticated techniques for hallucination detection leveraging LLMs are likely to emerge, further bolstering their utility in this task.
Grounding and cross-model evaluation provide powerful tools to combat hallucinations in GenAI outputs. Used strategically, these techniques bolster the factual accuracy and trustworthiness of these applications, promoting their robust deployment in real-world scenarios.
Bias Monitoring
The issue of bias in LLMs is a complex and pressing concern, as these models have the potential to perpetuate or amplify harmful stereotypes and discriminatory patterns present in their training data. Proactive bias monitoring is crucial for ensuring the ethical and inclusive deployment of GenAI in production. This section explores data-driven, actionable strategies for bias detection and mitigation.
Fairness Evaluation Toolkits
Specialized libraries and toolkits offer a valuable starting point for bias assessment in LLM outputs. While not all are explicitly designed for LLM evaluation, many can be adapted and repurposed for this context. Consider the following tools:
- Aequitas: Provides a suite of metrics and visualizations for assessing group fairness and bias across different demographics. This tool can be used to analyze model outputs for disparities based on sensitive attributes like gender, race, etc. ([invalid URL removed])
- FairTest: Enables the identification and investigation of potential biases in model outputs. It can analyze the presence of discriminatory language or differential treatment of protected groups. ([invalid URL removed])
Real-Time Analysis
In production environments, real-time bias monitoring is essential. Strategies include:
- Keyword and phrase tracking: Monitor outputs for specific words, phrases, or language patterns historically associated with harmful biases or stereotypes. Tailor these lists to sensitive domains and potential risks related to your application.
- Dynamic prompting for bias discovery: Systematically test the model with carefully constructed inputs designed to surface potential biases. For example, modify prompts to vary gender, ethnicity, or other attributes while keeping the task consistent, and observe whether the model's output exhibits prejudice.
Mitigation Strategies
When bias is detected, timely intervention is critical. Consider the following actions:
- Alerting: Implement an alerting system to flag potentially biased outputs for human review and intervention. Calibrate the sensitivity of these alerts based on the severity of bias and its potential impact.
- Filtering or modification: In sensitive applications, consider automated filtering of highly biased outputs or modification to neutralize harmful language. These measures must be balanced against the potential for restricting valid and unbiased expressions.
- Human-in-the-loop: Integrate human moderators for nuanced bias assessment and for determining appropriate mitigation steps. This can include re-prompting the model, providing feedback for fine-tuning, or escalating critical issues.
Important Considerations
- Evolving standards: Bias detection is context-dependent and definitions of harmful speech evolve over time. Monitoring systems must remain adaptable.
- Intersectionality: Biases can intersect across multiple axes (e.g., race, gender, sexual orientation). Monitoring strategies need to account for this complexity.
Bias monitoring in GenAI applications is a multifaceted and ongoing endeavor. By combining specialized toolkits, real-time analysis, and thoughtful mitigation strategies, developers can work towards more inclusive and equitable GenAI systems.
Coherence and Logic Assessment
Ensuring the internal consistency and logical flow of GenAI output is crucial for maintaining user trust and avoiding nonsensical results. This section offers techniques for unsupervised coherence and logic assessment, applicable to a variety of LLM-based tasks at scale.
Semantic Consistency Checks
Semantic Similarity Analysis
Calculate the semantic similarity between different segments of the generated text (e.g., sentences, paragraphs). Low similarity scores can indicate a lack of thematic cohesion or abrupt changes in topic.
Implementation
Leverage pre-trained sentence embedding models (e.g., Sentence Transformers) to compute similarity scores between text chunks.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-distilroberta-base-v2')
generated_text = "The company's stock price surged after the earnings report. Cats are excellent pets."
sentences = generated_text.split(".")
embeddings = model.encode(sentences)
similarity_score = cosine_similarity(embeddings[0], embeddings[1])
print(similarity_score) # A low score indicates potential incoherenceTopic Modeling
Apply topic modeling techniques (e.g., LDA, NMF) to extract latent topics from the generated text. Inconsistent topic distribution across the output may suggest a lack of a central theme or focus.
Implementation
Utilize libraries like Gensim or scikit-learn for topic modeling.
Logical Reasoning Evaluation
Entailment and Contradiction Detection
Assess whether consecutive sentences within the generated text exhibit logical entailment (one sentence implies the other) or contradiction. This can reveal inconsistencies in reasoning.
Implementation
Employ entailment models (e.g., BERT-based models fine-tuned on Natural Language Inference datasets like SNLI or MultiNLI).
These techniques can be packaged into user-friendly functions or modules, shielding users without deep ML expertise from the underlying complexities.
Sensitive Content Detection
With GenAI's ability to produce remarkably human-like text, it's essential to be proactive about detecting potentially sensitive content within its outputs. This is necessary to avoid unintended harm, promote responsible use, and maintain trust in the technology. The following section explores modern techniques specifically designed for sensitive content detection within the context of large language models. These scalable approaches will empower users to safeguard the ethical implementation of GenAI across diverse applications.
- Perspective API integration: Google's Perspective API offers a pre-trained model for identifying toxic comments. It can be integrated into LLM applications to analyze generated text and provide a score for the likelihood of containing toxic content. The Perspective API can be accessed through a REST API. Here's an example using Python:
from googleapiclient import discovery
import json
def analyze_text(text):
client = discovery.build("commentanalyzer", "v1alpha1")
analyze_request = {
"comment": {"text": text},
"requestedAttributes": {"TOXICITY": {}},
}
response = client.comments().analyze(body=analyze_request).execute()
return response["attributeScores"]["TOXICITY"]["summaryScore"]["value"]
text = "This is a hateful comment."
toxicity_score = analyze_text(text)
print(f"Toxicity score: {toxicity_score}")The API returns a score between 0 and 1, indicating the likelihood of toxicity. Thresholds can be set to flag or filter content exceeding a certain score.
- LLM-based safety filter: Major MLaaS providers like Google offer first-party safety filters integrated into their LLM offerings. These filters use internal LLM models trained specifically to detect and mitigate sensitive content. When using Google's Gemini API, the safety filters are automatically applied. You can access different creative text formats with safety guardrails in place. They also provide a second level of safety filters that users can leverage to apply additional filtering based on a set of metrics. For example, Google Cloud’s safety filters are mentioned here.
- Human-in-the-loop evaluation: Integrating human reviewers in the evaluation process can significantly improve the accuracy of sensitive content detection. Human judgment can help identify nuances and contextual factors that may be missed by automated systems. A platform like Amazon Mechanical Turk can be used to gather human judgments on the flagged content.
- Evaluator LLM: This involves using a separate LLM (“Evaluator LLM”) specifically to assess the output of the generative LLM for sensitive content. This Evaluator LLM can be trained on a curated dataset labeled for sensitive content. Training an Evaluator LLM requires expertise in deep learning. Open-source libraries like Hugging Face Transformers provide tools and pre-trained models to facilitate this process. An alternative is to use general-purpose LLMs such as Gemini or GPT with appropriate prompts to discover sensitive content.
The language used to express sensitive content constantly evolves, requiring continuous updates to the detection models. By combining these scalable techniques and carefully addressing the associated challenges, we can build robust systems for detecting and mitigating sensitive content in LLM outputs, ensuring responsible and ethical deployment of this powerful technology.
Conclusion
Ensuring the reliable, ethical, and cost-effective deployment of Generative AI applications in production environments requires a multifaceted approach to monitoring. This article presented a framework specifically designed for real-time monitoring of GenAI, addressing both infrastructure and quality considerations.
On the infrastructure side, proactive tracking of cost, latency, and scalability is essential. Tools for analyzing token usage, optimizing prompts, and leveraging auto-scaling capabilities play a crucial role in managing operational expenses and maintaining a positive user experience. Content monitoring is equally important for guaranteeing the quality and ethical integrity of GenAI applications. This includes techniques for detecting hallucinations, such as grounding in reliable data sources and incorporating human-in-the-loop verification mechanisms. Strategies for bias mitigation, coherence assessment, and sensitive content detection are vital for promoting inclusivity and preventing harmful outputs.
By integrating the monitoring techniques outlined in this article, developers can gain deeper insights into the performance, behavior, and potential risks associated with their GenAI applications. This proactive approach empowers them to take informed corrective actions, optimize resource utilization, and ultimately deliver reliable, trustworthy, and ethical AI-powered experiences to users. While we have focused on MLaaS offerings, the principles discussed can be adapted to self-hosted LLM deployments.
The field of GenAI monitoring is rapidly evolving. Researchers and practitioners should remain vigilant regarding new developments in hallucination detection, bias mitigation, and evaluation techniques. Additionally, it's crucial to recognize the ongoing debate around the balance between accuracy restrictions and creativity in generative models.
Reference
- M. Korolov, “For IT leaders, operationalized gen AI is still a moving target,” CIO, Feb. 28, 2024.
- O. Simeone, "A Very Brief Introduction to Machine Learning With Applications to Communication Systems," in IEEE Transactions on Cognitive Communications and Networking, vol. 4, no. 4, pp. 648-664, Dec. 2018, doi: 10.1109/TCCN.2018.2881441.
- F. Doshi-Velez and B. Kim, "Towards A Rigorous Science of Interpretable Machine Learning", arXiv, 2017. [Online].
- A. B. Arrieta et al. "Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI." Information Fusion 58 (2020): 82-115.
- A. Saleiro et al. "Aequitas: A Bias and Fairness Audit Toolkit." arXiv, 2018. [Online].
- E. Bender and A. Koller, “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data,” Proceedings of the 58th Annual Meeting of the Association for Computational
- S. Mousavi et al., “Enhancing Large Language Models with Ensemble of Critics for Mitigating Toxicity and Hallucination,” OpenReview.
- X. Amatriain, “Measuring And Mitigating Hallucinations In Large Language Models: A Multifaceted Approach”, Mar. 2024. [Online].
Opinions expressed by DZone contributors are their own.
Comments