MongoDB to Couchbase, Part 4: Data Modeling
Data modeling is a well-defined and mature field in relational database systems. In this post, read a comparison of modeling methods in MongoDB and Couchbase.
Join the DZone community and get the full member experience.
Join For FreeTo Embed or Not to Embed. That is the Question. - Hamlet
Data modeling is a well-defined and mature field in relational database systems. The model provides a consistent framework for application developers to add and manipulate the data. Everything is great until you need to change. This lack of schema flexibility was a key trigger for NoSQL database systems. As we've learned before, both MongoDB and Couchbase are JSON-based document databases. JSON gives the developers schema flexibility: the indexes, collections, query engine provide access paths to this data. The developer uses MQL in MongoDB and N1QL in Couchbase to query this data. Let's compare the modeling methods in Couchbase. Note: This article is short because the modeling options are similar. That's a good thing. Some differences in modeling options, access methods, and optimizations are highlighted below.
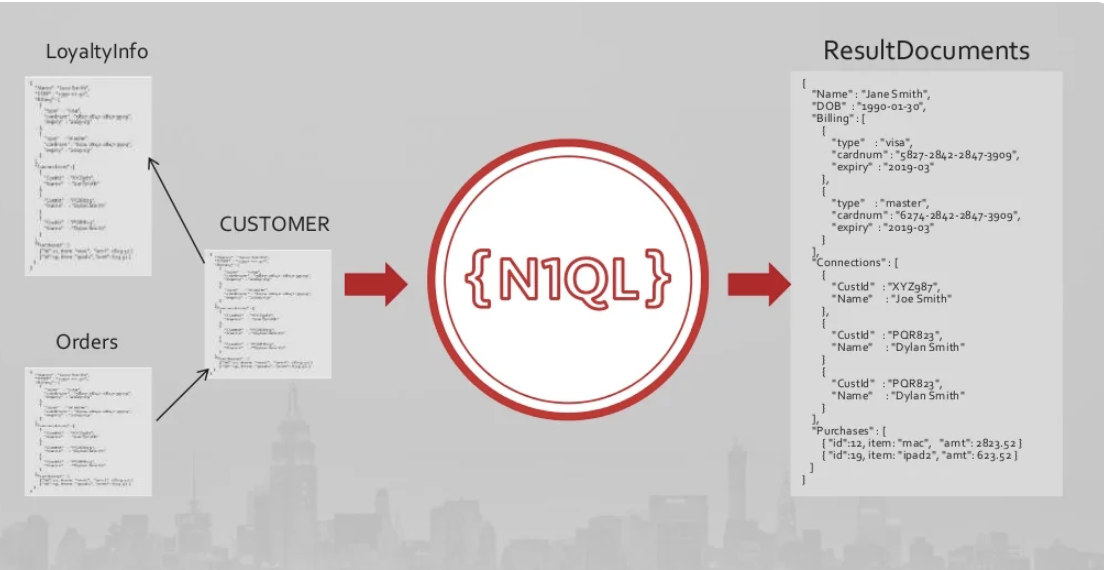
Couchbase N1QL Query Processing on JSON
Remember, any database can store any type of data. It's the ability to index and query efficiently that will help you to get your workload to meet your latency and throughput requirements. Databases are only as good as their access methods. The proof is in the pudding. See additional details of Couchbase data modeling and customer examples in my article Introduction to Couchbase for Oracle Developers and Experts: Part 4: Data Modeling. Additional details on utilizing arrays can be found in this slide deck.
Comparison of Modeling Options and Supporting Features
Mongo DB
Couchbase
Data Modeling Guides at this introduction, this video tutorial, and this additional video tutorial.
Additional examples
Data Modeling Guides: in this Couchbase documentation, this JSON Data Modeling Guide, and this video.
More examples at this blog.
Flexible document model based on BSON (binary JSON)
Flexible document model based on JSON and binary objects
Supports embedding and loose references (no foreign key reference enforcement)
Supports embedding and loose references (no foreign key reference enforcement)
Atomic Write operations:
Single document atomicity by default; Multi-document writes are supported as well as single-document atomicity.
Multi-document atomicity and full ACID for MQL operations is supported via transactions in 4.2 and above.
Atomic Write operations:
Single document atomicity by default; Multi-document writes are supported as well as single-document atomicity. The operations can be done via direct KV SDK or N1QL.
Multi-document atomicity has been supported since 6.5. Full ACID for N1QL statements is supported via N1QL transactions in 7.0 and above.
Performance Advisor:
Index advisor built into MongoDB ops manager
Performance Advisor:
Has index advisor built into the product (via ADVISE statement and ADVISOR function) as well as an open service.
Schema Validation is optionally done synchronously.
Synchronous schema validation is unavailable. Schema validation can be done asynchronously.
Embedded data model
Exactly the same thing on JSON and Couchbase
Normalized data model: References to other documents are stored as ObjectId().
Example:
“product”: ObjectId("Lego.US.beatles123”)
“friends”: [ObjectId("fred.123”), objectId(“joe.234”), objectId(“john.345”)]
In a normalized schema, queries typically end up joining the data using the $lookupoperator. $lookup implements left outer join against an unsharded collection. Joining between two sharded collections has to be implemented by the application/user.$graphlookup mimics recursion using Oracle’s CONNECT BY feature by querying the same object based on the previous result.
Normalized data model: References to other documents are simply stored as a string representing the document key of the references.
Example:
“product”:"Lego.US.beatles123”
“friends”: ["fred.123”, “joe.234”, “john.345”]
In a normalized schema, queries can issue INNER JOIN, LEFT OUTER JOIN, and RIGHT OUTER JOIN to manage the data. Collections in Couchbase are always automatically sharded (hash partitioned). All joins are supported partitioned collections. See details here and here.Couchbase doesn’t have the equivalent recursive querying capability. There are some workarounds: See here; The JavaScript UDF feature in 7.1 will help you write a loop or recursion easily.
Sharding Collections
The collections are not sharded by default. You’d need to add the config servers and mongos to shard a collection. Mongo supports hash and range-based strategies for collection and index sharding. Indexes follow the collections shard strategy since the MongoDB indexes are local to the data. Mongo supports one or more fields as the shard key for hash strategy.
Sharding is called partitioning in Couchbase. The collections in Couchbase are always hash-partitioned based on the document key. There is no range partitioning of the collection itself. The indexes in Couchbase can use a different strategy than the collection. Indexes can be partitioned or not. Indexes can be partitioned using hash on any field or expression or any complicated expression. The expressions for creating the index provide the flexibility to create indexes for a subset of the data (partial index).
Time to Live (TTL) is supported by creating an index on a date field within the collection.
Couchbase supports TTL natively on the collections without the need for a separate index.
Modeling 1:1 relationships with embedding documents
For 1:1 relationships, you use the exact same approach.
Modeling 1:n relationships with embedding documents. This comes naturally with BSON arrays. Supporting storing an array of objects and or object of arrays is easy. The important thing is the support for querying and speeding them up using indexes. MongoDB supports querying data based on any of the values or fields in an array. The queries can be accelerated using array indexes. While MongoDB does not support indexing multiple arrays in a single index, it allows creating an array key with keys from multiple arrays and creating a single index on it.
You can use the exact same approach on Couchbase. Arrays are a fundamental type in JSON and can be nested easily. Couchbase supports querying arrays, indexing arrays, and expressions on the index. The query support both nesting and unnesting of arrays easily in the FROM clause of the statement. Array indexes support indexing on one or more keys or expressions. Couchbase also supports indexing multiple arrays in a single index in FTS and using them in a direct search query or N1QL query. See additional details here.
Modeling 1:n relationship with references. Simply store the n references as an array of document _id list. Within the query, simply do the $lookup to join the documents. Also, you can sequence many $lookup operations in a single aggregate() query. $lookup is fine as long as you avoid joining a sharded collection to another sharded collection. You have to be careful about joining two humongous collections. The second limitation is $lookup only supports nested loop join. When the amount of data increases, you need other join implementations like hash joins, which Mongo does not have.
You can use the exact same approach on Couchbase. Instead of $lookup, use JOIN operations. See details here and here. The collections and the indexes used for the JOIN operations can be partitioned (Couchbase term for sharding). Couchbase support both nested loop and hash joins in both query and analytics service. If you’re using the Couchbase cost-based optimizer in 7.0, it chooses the join method based on the lowest cost estimates. The rule-based optimizer uses NL join by default and can use hash join when you specify the hash join hint.
Mongo DB |
Couchbase |
|---|---|
Data Modeling Guides at this introduction, this video tutorial, and this additional video tutorial. Additional examples |
Data Modeling Guides: in this Couchbase documentation, this JSON Data Modeling Guide, and this video. More examples at this blog. |
Flexible document model based on BSON (binary JSON) |
Flexible document model based on JSON and binary objects |
Supports embedding and loose references (no foreign key reference enforcement) |
Supports embedding and loose references (no foreign key reference enforcement) |
Atomic Write operations: Single document atomicity by default; Multi-document writes are supported as well as single-document atomicity. Multi-document atomicity and full ACID for MQL operations is supported via transactions in 4.2 and above. |
Atomic Write operations: Single document atomicity by default; Multi-document writes are supported as well as single-document atomicity. The operations can be done via direct KV SDK or N1QL. Multi-document atomicity has been supported since 6.5. Full ACID for N1QL statements is supported via N1QL transactions in 7.0 and above. |
Performance Advisor: Index advisor built into MongoDB ops manager |
Performance Advisor: Has index advisor built into the product (via ADVISE statement and ADVISOR function) as well as an open service. |
Schema Validation is optionally done synchronously. |
Synchronous schema validation is unavailable. Schema validation can be done asynchronously. |
Embedded data model |
Exactly the same thing on JSON and Couchbase |
Normalized data model: References to other documents are stored as ObjectId(). Example: “product”: ObjectId("Lego.US.beatles123”) “friends”: [ObjectId("fred.123”), objectId(“joe.234”), objectId(“john.345”)] In a normalized schema, queries typically end up joining the data using the $lookupoperator. $lookup implements left outer join against an unsharded collection. Joining between two sharded collections has to be implemented by the application/user.$graphlookup mimics recursion using Oracle’s CONNECT BY feature by querying the same object based on the previous result. |
Normalized data model: References to other documents are simply stored as a string representing the document key of the references. Example: “product”:"Lego.US.beatles123” “friends”: ["fred.123”, “joe.234”, “john.345”] In a normalized schema, queries can issue INNER JOIN, LEFT OUTER JOIN, and RIGHT OUTER JOIN to manage the data. Collections in Couchbase are always automatically sharded (hash partitioned). All joins are supported partitioned collections. See details here and here.Couchbase doesn’t have the equivalent recursive querying capability. There are some workarounds: See here; The JavaScript UDF feature in 7.1 will help you write a loop or recursion easily. |
Sharding Collections The collections are not sharded by default. You’d need to add the config servers and mongos to shard a collection. Mongo supports hash and range-based strategies for collection and index sharding. Indexes follow the collections shard strategy since the MongoDB indexes are local to the data. Mongo supports one or more fields as the shard key for hash strategy. |
Sharding is called partitioning in Couchbase. The collections in Couchbase are always hash-partitioned based on the document key. There is no range partitioning of the collection itself. The indexes in Couchbase can use a different strategy than the collection. Indexes can be partitioned or not. Indexes can be partitioned using hash on any field or expression or any complicated expression. The expressions for creating the index provide the flexibility to create indexes for a subset of the data (partial index). |
Time to Live (TTL) is supported by creating an index on a date field within the collection. |
Couchbase supports TTL natively on the collections without the need for a separate index. |
Modeling 1:1 relationships with embedding documents |
For 1:1 relationships, you use the exact same approach. |
Modeling 1:n relationships with embedding documents. This comes naturally with BSON arrays. Supporting storing an array of objects and or object of arrays is easy. The important thing is the support for querying and speeding them up using indexes. MongoDB supports querying data based on any of the values or fields in an array. The queries can be accelerated using array indexes. While MongoDB does not support indexing multiple arrays in a single index, it allows creating an array key with keys from multiple arrays and creating a single index on it. |
You can use the exact same approach on Couchbase. Arrays are a fundamental type in JSON and can be nested easily. Couchbase supports querying arrays, indexing arrays, and expressions on the index. The query support both nesting and unnesting of arrays easily in the FROM clause of the statement. Array indexes support indexing on one or more keys or expressions. Couchbase also supports indexing multiple arrays in a single index in FTS and using them in a direct search query or N1QL query. See additional details here. |
Modeling 1:n relationship with references. Simply store the n references as an array of document _id list. Within the query, simply do the $lookup to join the documents. Also, you can sequence many $lookup operations in a single aggregate() query. $lookup is fine as long as you avoid joining a sharded collection to another sharded collection. You have to be careful about joining two humongous collections. The second limitation is $lookup only supports nested loop join. When the amount of data increases, you need other join implementations like hash joins, which Mongo does not have. |
You can use the exact same approach on Couchbase. Instead of $lookup, use JOIN operations. See details here and here. The collections and the indexes used for the JOIN operations can be partitioned (Couchbase term for sharding). Couchbase support both nested loop and hash joins in both query and analytics service. If you’re using the Couchbase cost-based optimizer in 7.0, it chooses the join method based on the lowest cost estimates. The rule-based optimizer uses NL join by default and can use hash join when you specify the hash join hint. |
Published at DZone with permission of Keshav Murthy, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments