Modernize Your Data Model From SQL to NoSQL
This article explores two strategies that can help transition from SQL to NoSQL more smoothly: change data capture and dual-writes.
Join the DZone community and get the full member experience.
Join For FreeThis article was authored by AWS Sr. Specialist SA Alexander Schueren and published with permission.
We all like to build new systems, but there are too many business-critical systems that need to be improved. Thus, constantly evolving system architecture remains a major challenge for engineering teams. Decomposing the monolith is not a new topic. Strategies and techniques like domain-driven design and strangler patterns shaped the industry practice of modernization. NoSQL databases became popular for modernization projects. Better performance, flexible schemas, and cost-effectiveness are key reasons for adoption. They scale better and are more resilient than traditional SQL databases. Using a managed solution and reducing operational overhead is a big plus. But moving data is different: it’s messy and there are many unknowns. How do you design the schema, keep the data consistent, handle failures, or roll back? In this article, we will discuss two strategies that can help transition from SQL to NoSQL more smoothly: change data capture and dual-writes.
Continuous Data Migration
With agile software development, we now ship small batches of features every week instead of having deployment events twice a year, followed by fragile hotfixes and rollbacks. However, with data migrations, there is a tendency to migrate all the data at once. Well, most of the data migrations are homogenous (SQL to SQL), so the data structure remains compatible. Thus, many commercial tools can convert the schema and replicate data. But migrating from SQL to NoSQL is different. It requires an in-depth analysis of the use case and the access pattern to design a new data model. Once we have it, the challenge is to migrate data continuously and catch and recover from failures. What if we can migrate a single customer record, or ten customers from a specific region, or a specific product category? To avoid downtime, we can migrate the data continuously by applying the migration mechanism to a small subset of data. Over time we gain confidence, refine the mechanism, and expand to a larger dataset. This will ensure stability and we can also capitalize on the better performance or lower cost much earlier.
Change Data Capture
Change data capture (CDC) is a well-established and widely used method. Most relational database management systems (RDBMS) have an internal storage mechanism to collect data changes, often called transaction logs. Whenever you write, update, or delete data, the system captures this information. This is useful if you want to roll back to a previous state, move back in time or replicate data. We can hook into the transaction log and forward the data changes to another system. When moving data from SQL to AWS database services, such as Amazon RDS, AWS Database Migration Service (AWS DMS) is a popular choice. In combination with the schema conversion tool, you can move from Microsoft SQL or Oracle server to an open-source database, such as PostgreSQL or MySQL. But with DMS, we can also move from SQL to NoSQL databases, such as Amazon DynamoDB, S3, Neptune, Kinesis, Kafka, OpenSearch, Redis, and many others.
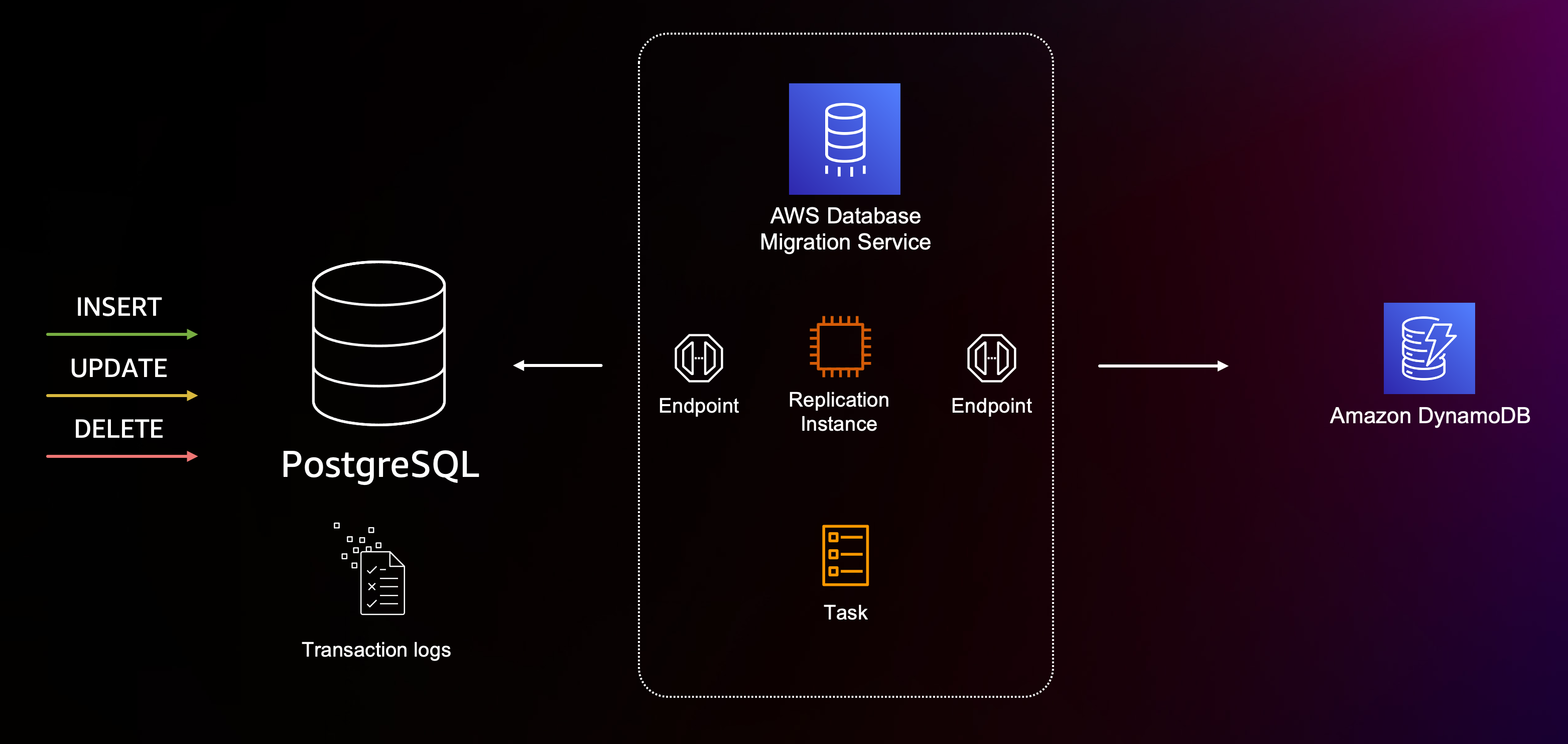
Here is how it works:
- Define the source and the target endpoints with the right set of permission for read and write operations.
- Create a task definition specifying the CDC migration process.
- Add a table mapping with the rule type
object-mappingto specify the partition key and attributes for your DynamoDB table.
Here is an example of a mapping rule in AWS DMS:
{
"rules": [
{
"rule-type": "object-mapping",
"rule-id": "1",
"rule-name": "TransformToDDB",
"object-locator": {
"schema-name": "source-schema",
"table-name": "customer"
},
"rule-action": "map-record-to-record",
"target-table-name": "customer",
"mapping-parameters": [
{
"partition-key-name": "CustomerName",
"attribute-type": "scalar",
"attribute-sub-type": "string",
"value": "${FIRST_NAME},${LAST_NAME}"
},
{
"target-attribute-name": "ContactDetails",
"attribute-type": "document",
"attribute-sub-type": "dynamodb-map",
"value": "..."
}
]
}
]
}This mapping rule will copy the data from the customer table and combine FIRST_NAME and LAST_NAME to a composite hash key, and add ContactDetails column with a DynamoDB map structure. For more information, you can see other object-mapping examples in the documentation.
One of the major advantages of using CDC is that it allows for atomic data changes. All the changes made to a database, such as inserts, updates, and deletes, are captured as a single transaction. This ensures that the data replication is consistent, and with a transaction rollback, CDC will propagate these changes to the new system as well.
Another advantage of CDC is that it does not require any application code changes. There might be situations when the engineering team can’t change the legacy code easily; for example, with a slow release process or lack of tests to ensure stability. Many database engines support CDC, including MySQL, Oracle, SQL Server, and more. This means you don’t have to write a custom solution to read the transaction logs.
Finally, with AWS DMS, you can scale your replication instances to handle more data volume, again without additional code changes.
AWS DMS and CDC are useful for database replication and migration but have some drawbacks. The major concern is the higher complexity and costs to set up and manage a replication system. You will spend some time fine-tuning the DMS configuration parameters to get the best performance. It also requires a good understanding of the underlying databases, and it’s challenging to troubleshoot errors or performance issues, especially for those who are not familiar with the subtle details of the database engine, replication mechanism, and transaction logs.
Dual Writes
Dual writes is another popular approach to migrate data continuously. The idea is to write the data to both systems in parallel in your application code. Once the data is fully replicated, we switch over to the new system entirely. This ensures that data is available in the new system before the cutover, and it also keeps the door open to fall back to the old system. With dual writes, we operate on the application level, as opposed to the database level with CDC; thus, we use more compute resources and need a robust delivery process to change and release code. Here is how it works:

- Applications continue to write data to the existing SQL-based system as they would.
- A separate process often called a “dual-writer” gets a copy of the data that has been written to the SQL-based system and writes it to the DynamoDB after the transaction.
- The dual-writer ensures we write the data to both systems in the same format and with the same constraints, such as unique key constraints.
- Once the dual-write process is complete, we switch over to read from and write to the DynamoDB system.
We can control the data migration and apply dual writes to some data by using feature flags. For example, we can toggle the data replication or apply only to a specific subset. This can be a geographical region, customer size, product type, or a single customer.
Because dual writes are instrumented on the application level we don’t run queries against the database directly. We work on the object level in our code. This allows us to have additional transformation, validation, or enrichment of the data.
But there are also downsides, code complexity, consistency, and failure handling. Using feature flags helps to control the flow, but we still need to write code, add tests, deploy changes, and have a feature flag store. If you are already using feature flags, this might be negligible; otherwise, it's a good chance to introduce feature flags to your system. Data consistency and failure handling are the primary beasts to tame. Because we copy data after the database transaction, there might be cases of rollbacks, and with dual write, you can miss this case. To counter that, you’d need to collect operational and business metrics to keep track of read and write operations to each system, which will increase confidence over time.
Conclusion
Modernization is unavoidable and improving existing systems will become more common in the future. Over the years, we have learned how to decouple monolithic systems and with many NoSQL database solutions, we can improve products with better performance and lower costs. CDC and dual-writes are solid mechanisms for migrating data models from SQL to NoSQL. While CDC is more database and infrastructure-heavy, with dual-writes we operate on a code level with more control over data segmentation, but with higher code complexity. Thus, it is crucial to understand the use case and the requirements when deciding which mechanism to implement. Moving data continuously between systems should not be difficult, so we need to invest more and learn how to adjust our data model more easily and securely. Chances are high that this is not the last re-architecting initiative you are doing, and building these capabilities will be useful in the future.
Do You Like Video Tutorials?
If you are more of a visual person who likes to follow the steps to build something with a nice recorded tutorial, then I would encourage you to subscribe to the Build On AWS YouTube channel. This is the place you should go to dive deep into code and architecture, with people from the AWS community sharing their expertise in a visual and entertaining manner.
Opinions expressed by DZone contributors are their own.
Comments