Microservices Orchestration
Learn how to get the most out of your services in this article as you take a look at patterns and strategies for microservices communication.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Does your organization use a microservices-style architecture to implement its business functionality? What approaches to microservices communication and orchestration do you use? Microservices have been a fairly dominant application architecture for the last few years and are usually coupled with the adoption of a cloud platform (e.g., containers, Kubernetes, FaaS, ephemeral cloud services). Communication patterns between these types of services vary quite a bit.
Microservices architectures stress independence and the ability to change frequently, but these services often need to share data and initiate complex interactions between themselves to accomplish their functionality. In this article, we'll take a look at patterns and strategies for microservices communication.
Problems in the Network
Communicating over the network introduces reliability concerns. Packets can be dropped, delayed, or duplicated, and all of this can contribute to misbehaving and unreliable service-to-service communication. In the most basic case — service A opening a connection to service B — we put a lot of trust in the application libraries and the network itself to open a connection and send a request to the target service (service B in this case).

Figure 1: Simple example of service A calling service B
But what happens if that connection takes too long to open? What if that connection times out and cannot be open? What if that connection succeeds but then later gets shut down after processing a request, but before a response?
We need a way to quickly detect connection or request issues and decide what to do. Maybe if service A cannot communicate with service B, there is some reasonable fallback (e.g., return an error message, static response, respond with a cached value).
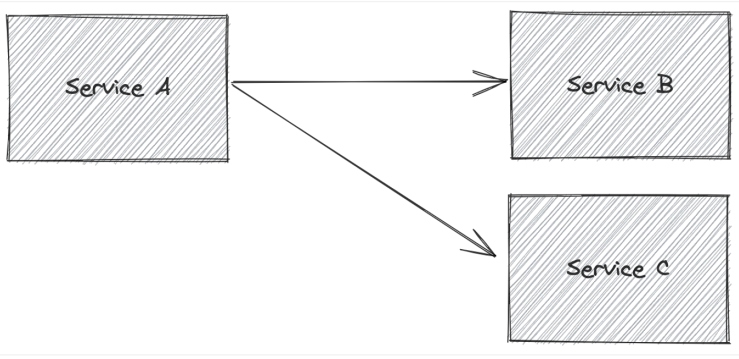
Figure 2: More complicated example of calling multiple services
In a slightly more complicated case, service A might need to call service B, retrieve some values from the service B response, and use it to call service C. If the call to service B succeeds but the call to service C fails, the fallback option may be a bit more complicated.
Maybe we can fall back to a predefined response, retry the request, pull from a cache based on some of the data from the service B response, or maybe call a different service?
Problems within the network that cause connection or request failures can, and do, happen intermittently and must be dealt with by the applications. These problems become more likely and more complicated with the more service calls orchestrated from a given service, as is seen in Figure 3.
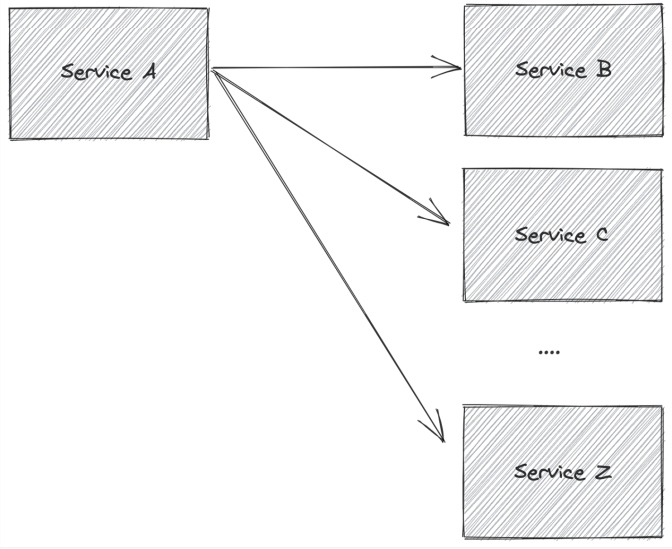
Figure 3: Trying to orchestrate multiple service calls across read/write APIs
These problems become even more troubling when these calls between services aren't just "read" calls.
For example, if service A calls service B, which performs some kind of data mutation that must be coordinated with the next call to service C (e.g., service A tells service B that customer Joe’s address is updated but must also tell service C to change the shipping because of the address change), then these failed calls are significant.
This can result in inconsistent data and an inconsistent state across services.
Network errors like this impact resilience, data consistency, and likely service-level objectives (SLOs) and service-level agreements (SLAs). We need a way to deal with these network issues while taking into account other issues that crop up when trying to account for failures.
Helpful Network Resilience Patterns
Building APIs and services to be resilient to network unreliability is not always easy. Services (including the frameworks and libraries used to build a service) can fail due to the network in sometimes unpredictable ways. A few patterns that go a long way to building resilient service communication are presented here but are certainly not the only ones.
These three patterns can be used as needed or together to improve communication reliability (but each has its own drawbacks):
- Retry/backoff retry – if a call fails, send the request again, possibly waiting a period of time before trying again
- Idempotent request handling – the ability to handle a request multiple times with the same result (can involve de-duplication handling for write operations)
- Asynchronous request handling – eliminating the temporal coupling between two services for request passing to succeed
Let’s take a closer look at each of these patterns.
Retries With Backoff Handling
Network unreliability can strike at any time and if a request fails or a connection cannot be established, one of the easiest things to do is retry. Typically, we need some kind of bounded number of retries (e.g., "retry two times" vs. just retry indefinitely) and potentially a way to backoff the retries. With backoffs, we can stagger the time we spend between a call that fails and how long to retry.
One quick note about retries: We cannot just retry forever, and we cannot configure every service to retry the same number of times. Retries can contribute negatively to "retry storm" events where services are degrading and the calling services are retrying so much that it puts pressure on, and eventually takes down, a degraded service (or keeps it down as it tries to come back up). A starting point could be to use a small, fixed number of retries (say, two) higher up in a call chain and don’t retry the deeper you get into a call chain.
Idempotent Request Handling
Idempotent request handling is implemented on the service provider for services that make changes to data based on an incoming request. A simple example would be a counter service that keeps a running total count and increments the count based on requests that come in. For example, a request may come in with the value "5," and the counter service would increment the current count by 5. But what if the service processes the request (increments of 5), but somehow the response back to the client gets lost (network drops the packets, connection fails, etc.)?
The client may retry the request, but this would then increment the count by 5 again, and this may not be the desired state. What we want is the service to know that it’s seen a particular request already and either disregard it or apply a "no-op." If a service is built to handle requests idempotently, a client can feel safe to retry the failed request with the service able to filter out those duplicate requests.
Asynchronous Request Handling
For the service interactions in the previous examples, we've assumed some kind of request/response interaction, but we can alleviate some of the pains of the network by relying on some kind of queue or log mechanism that persists a message in flight and delivers it to consumers. In this model, we remove the temporal aspect of both a sender and a receiver of a request being available at the same time.
We can trust the message log or queue to persist and deliver the message at some point in the future. Retry and idempotent request handling are also applicable in the asynchronous scenario. If a message consumer can correctly apply changes that may occur in an "at-least once delivery" guarantee, then we don't need more complicated transaction coordination.
Essential Tools and Considerations for Service-to-Service Communication
To build resilience into service-to-service communication, teams may rely on additional platform infrastructure, for example, an asynchronous message log like Kafka or a microservices resilience framework like Istio service mesh. Handling tasks like retries, circuit breaking, and timeouts can be configured and enforced transparently to an application with a service mesh.
Since you can externally control and configure the behavior, these behaviors can be applied to any/all of your applications — regardless of the programming language they've been written in. Additionally, changes can be made quickly to these resilience policies without forcing code changes.
Another tool that helps with service orchestration in a microservices architecture is a GraphQL engine. GraphQL engines allow teams to fan out and orchestrate service calls across multiple services while taking care of authentication, authorization, caching, and other access mechanisms. GraphQL also allows teams to focus more on the data elements of a particular client or service call. GraphQL started primarily for presentation layer clients (web, mobile, etc.) but is being used more and more in service-to-service API calls as well.
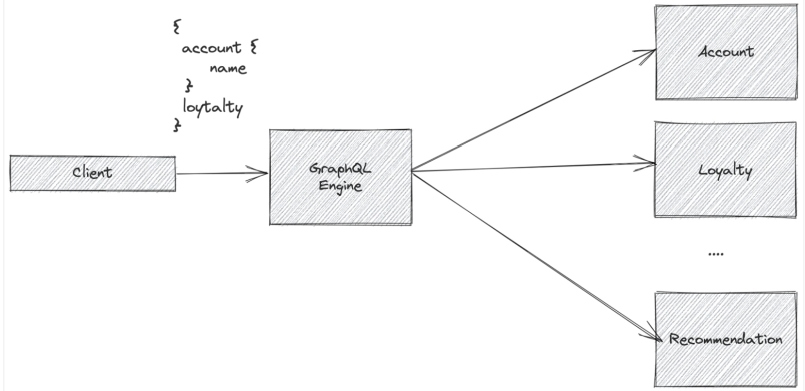
Figure 4: Orchestrating service calls across multiple services with a GraphQL engine
GraphQL can also be combined with API Gateway technology or even service mesh technology, as described above. Combining these provides a common and consistent resilience policy layer — regardless of what protocols are being used to communicate between services (REST, gRPC, GraphQL, etc.).
Conclusion
Most teams expect a cloud infrastructure and microservices architecture to deliver big promises around service delivery and scale. We can set up CI/CD, container platforms, and a strong service architecture, but if we don’t account for runtime microservices orchestration and the resilience challenges that come with it, then microservices are really just an overly complex deployment architecture with all of the drawbacks and none of the benefits. If you’re going down a microservices journey (or already well down the path), make sure service communication, orchestration, security, and observability are at front of mind and consistently implemented across your services.
This is an article from DZone's 2022 Microservices and Containerization Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments