Manage Hierarchical Data in MongoDB With Spring
In this article, we show CRUD operations on hierarchical data stored in MongoDB by taking advantage of the "$graphLookup" operation and build a Spring Boot app.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Modeling Tree Structures is one of the most common requirements often met in software applications. Depending on the size of the data, the information each node keeps, the type of queries performed, and the database storage engines available (or allowed), there are plenty of options to evaluate and choose from.
MongoDB allows various ways to use tree data structures to model large hierarchical or nested data relationships such as [1]:
- Model Tree Structures with Parent or Child References.
- Model Tree Structures with an Array of Ancestors.
- Model Tree Structures with Materialized Paths.
- Model Tree Structures with Nested Sets.
Each of these approaches has its trade-offs. Usually, a more complex structure results in better performance and simplicity when querying data and the opposite when inserting or updating nodes.
Since MongoDB version 3.4, a new capability was added: recursive graph traversal with the usage of $graphLookup operation as part of the Aggregation pipeline stage.
A graph, in general, is based on the following key concepts:
- Vertices (Nodes)
- Edges (Relationships)
- Nodes have properties.
- Relationships have a name and direction.
In graph theory, a tree is an undirected graph in which any two vertices are connected by exactly one path, or equivalently a connected acyclic undirected graph. Moreover, the information needed to depict a graph or tree is possible to be stored in Document-style (like MongoDB supports).
The $graphLookup operation performs a recursive search on a collection, with options for restricting the search by recursion depth and query filter. This capability allows to opt-in for the simplest of the tree structure models listed above, which is to simply store in each document (node) only the identifier of the immediate parent or child node.
In the following sections, we will demonstrate:
- The usage of
$graphLookupfor fetching tree data, along with insert/delete/update operations by leveraging Spring Data MongoDB to build a Spring Boot app exposing a REST API. - On top of these, we will show-off another more recent feature of MongoDB that may be needed, especially when we need to perform deletes and updates: MongoDB Transactions.
The Data Model
As explained above, we will adopt the Parent References data model for our tree-like structure throughout this demonstration. We will manage a sample dataset containing a number of trees of arbitrary depth. Each individual tree will be identified by a unique tree id. Each tree node will have some properties i.e will store some information. We will keep this generic in order to focus on how we can store, retrieve, and update this type of data in MongoDB using Java and Spring framework. In practice, such datasets could represent an enterprise product catalog, genealogies, various organizational structures, hierarchical location data, computer network topologies (physical/virtual/application layer), etc.
The Parent References pattern stores each tree node in a document. In addition to the tree node, the document stores the id of the node’s parent, plus some extra attributes. Let's see a sample document for our given dataset:
xxxxxxxxxx
{
"nodeId": 25499489,
"versionId": 25499490,
"name": "PRODUCTION",
"type": "Node",
"treeId": 25080022,
"parentId": [
23978786
]
}
This document holds some information like name, type, and version Id. It also has a custom unique ID named node Id and an array named parent Id, which holds the node Id of the node's parent. Note that the field parent Id can actually be an array in case we need to cover the possibility of a node having multiple parents. Although not demonstrated here, this is supported by $graphLookup.
Sample Dataset
We provide a sample generated dataset for testing purposes with the following characteristics:
- The number of trees: 5
- The number of nodes: 439674
- The total size in MB: 84
- The size of trees in nodes vary from 44237 to 171354
- The depth of trees vary from 40 to 42
A partial schematic representation can be seen below:
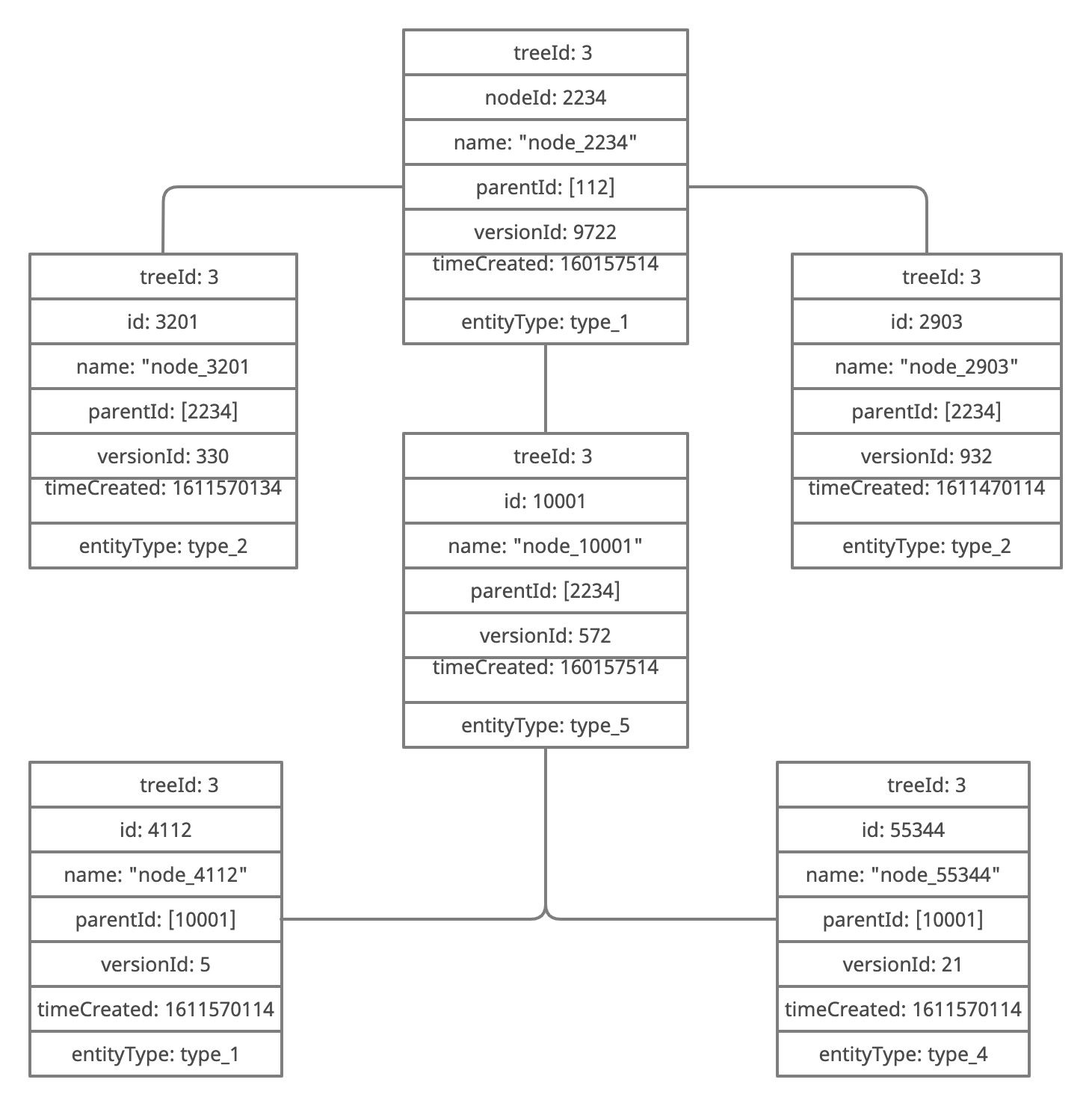
Instructions for importing the dataset in MongoDB are provided in the project's GitHub.
Implementation
Our sample application is a typical Maven-based Spring Boot application.
The dependencies we will need in our pom.xml file are the following:
xxxxxxxxxx
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
We will be following the Controller-Service-Repository pattern. The main components are:
- NodeController: Straightforward Spring RestController responsible for exposing the REST endpoints. It invokes the NodeService and returns the results in JSON format.
- NodeService: It invokes the NodeRepository to delegate various CRUD operations. In the case of data retrieval, it performs transformations of data from a flat structure to a hierarchical one. Some methods are marked as
@Transactional, since we will be using Transactions withMongoTransactionManager - NodeRepository: It executes the CRUD operations. We use Spring's built-in
MongoTemplateto execute an aggregation command and Spring Data's defaultMongoRepositoryfor the rest actions. Multiple inheritances by Interface is applied at this point.
The domain object identified to be persisted to MongoDB is Node.java:
xxxxxxxxxx
(collection = "nodes")
public class Node {
private String id;
private int nodeId;
private int versionId;
private String name;
private EntityType type;
private int treeId;
private List<Integer> parentId;
// transient field
private List<Node> descendants;
}
Within the @Document annotation is the declaration of the name of the collection the document representing the entity is supposed to be stored in. In this case, we call it "trees".
Another thing to point out is that we need to add the @EnableMongoRepositories annotation to our main class like so:
xxxxxxxxxx
(basePackages = "com.github.kmandalas.mongodb.repository")
public class Application {
public static void main(final String[] args) {
SpringApplication.run(Application.class, args);
}
}
We will utilize Docker and docker-compose to spin-up a MongoDB replica set (we will explain later on why we need a cluster topology and not just a standalone server). The connectivity with MongoDB is achieved via Spring Boot auto-configuration, as can be seen in the application-*.yml files below:
x
spring
data
mongodb
urimongodb//mongo127017,mongo227018,mongo327019/test?replicaSet=rs0
The sample application source code is available on GitHub in the repository spring-mongodb-graphlookup. In the README file, you will find information on how to build, test, and run the application.
Let's move on with more implementation details starting from Read operations.
Read Operations
We have 2 kinds of reading operations:
- Get a full tree by a given
tree Id. - Get a sub-tree starting from a branch node with a given node Id.
In order to combine this functionality into a single Repository interface, we apply multiple inheritances:
xxxxxxxxxx
public interface NodeRepository extends MongoRepository<Node, Object>, NodeGraphLookupRepository {
Optional<List<Node>> findDistinctByTreeId(int treeId);
}
For the first operation, no implementation is required, since we take advantage of the derived query by method name capability of Spring Data MongoRepository. The method findDistinctByTreeId will return a list of all the nodes belonging to the specific tree we are looking for.
For the second operation, we need to use the MongoDB's Aggregation Pipeline Stages and provide an implementation of the interface NodeGraphLookupRepository , which is the following:
xxxxxxxxxx
public class NodeRepositoryImpl implements NodeGraphLookupRepository {
private final MongoTemplate mongoTemplate;
public NodeRepositoryImpl(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
public Optional<List<Node>> getSubTree(int treeId, int nodeId, Long maxDepth) throws Exception {
final Criteria byNodeId = new Criteria("nodeId").is(nodeId);
final Criteria byTreeId = new Criteria("treeId").is(treeId);
final MatchOperation matchStage = Aggregation.match(byTreeId.andOperator(byNodeId));
GraphLookupOperation graphLookupOperation = GraphLookupOperation.builder()
.from("node")
.startWith("$nodeId")
.connectFrom("nodeId")
.connectTo("parentId")
.restrict(new Criteria("treeId").is(treeId))
.maxDepth(maxDepth != null ? maxDepth : MAX_DEPTH_SUPPORTED)
.as("children");
Aggregation aggregation = Aggregation.newAggregation(matchStage, graphLookupOperation);
List<Node> results = mongoTemplate.aggregate(aggregation, "node", Node.class).getMappedResults();
return CollectionUtils.isEmpty(results) ? Optional.empty() : Optional.of(results);
}
}
The above implementation is the equivalent of the following command executed via the Mongo Shell:
xxxxxxxxxx
db.nodes.aggregate([
{ $match: { treeId: 1001, $and: [ { nodeId: 100 } ] } },
{
$graphLookup: {
from: "nodes",
startWith: "$nodeId",
connectFromField: "nodeId",
connectToField: "parentId",
restrictSearchWithMatch: {"treeId": 1001},
maxDepth: 10000
as: "descendants"
}
}
]);
As can be seen above, we have built an Aggregation Pipeline consisting of 2 stages: a $match stage and the $graphLookup stage.
We need the $match stage in order to filter the documents and pass only the documents that match the specified condition(s) to the next pipeline stage. In our case, we need to match a single document identified by its node Id and the tree it belongs to (identified by the tree Id). This is the document/node from which the $graphLookup stage will begin the recursion from.
For a full list of options and the internals of the $graphLookup operation, it is highly recommended to check the official documentation here. Make sure you pay attention to the following noteworthy limitations including the following:
- The collection specified in
fromfield cannot be shared. This is an important consideration, due to the fact that lack of sharding means lack of horizontal scalability. On the other hand, if we are dealing with a very large dataset dynamically increasing, then perhaps other storage engines should be considered for heavy graph-like operations. - The
$graphLookupstage must stay within the 100 megabyte memory limit.
Results Format: Flat vs Nested
The results we get back from the pipeline execution are flat and no order is guaranteed. For various reasons, we may need to present them in a nested format. We can achieve this with one of the following ways:
- Process them at the application level and convert them. This is the approach implemented in our demo app. More specifically, we do this via the static Interface method
com.github.kmandalas.mongodb.service.NodeService#assembleTree - We can create MongoDB views and execute the
$graphLookupon the view instead of the original collection. However, this way we cannot get a full-depth hierarchy. For limited use-cases though, we cloud create a new view for each level of embedding that we may need. You may get more precise information from our answered Stack Overflow discussion here.
Indexing and Performance
Adding the proper indexes is essential to achieve better performance. Spring Data MongoDB provides the @Indexed and @CompoundIndexes annotations, which can be added on field-level or class-level within a @Document annotated object. However, we have not added any index in advance in order to demonstrate the difference in response times.
Let's check the performance on sub-trees retrieval by executing the following:
xxxxxxxxxx
curl --location --request GET 'http://localhost:8080/app/1001/st/100'
Without indexes in place, an indicative response time is ~546ms.
If we proceed with adding indexes on fields: node Id, parent Id, and tree Id and we run similar sub-tree retrievals, the response time drops to ~15ms!
Depending on your use-case and your dataset attributes, proper indexing is a must for speeding up the $graphLookup operations.
Delete Node
Let's see now how we can modify data, starting with node deletion. We assume no "pruning " will be made i.e. we will simply locate the node under deletion and remove it from the collection. If the node is not a leaf, however, we will need to perform an additional action: update the parent Id fields of its children to point to the nodes under deletion parent. This way, we need to perform multi-document updates or in other words multi-document transactions.
MongoDB Transactions
In MongoDB, an operation on a single document is atomic. This covers many use-cases because you can use embedded documents and arrays to capture relationships between data. Starting from version 4.x, ACID transactions have arrived in the Document store, enforcing all-or-nothing execution and maintaining data integrity.
Spring Data MongoDB provides a number of ways to work with MongoDB transactions, including Reactive support. In our case, we will go with the MongoTransactionManager, since it is the gateway to the well-known Spring transaction support, and it lets applications use the managed transaction features of Spring.
Now, if you attempt to run the application against a standalone MongoDB server and you try to execute a @Transactional service method, you will get the following exception:
xxxxxxxxxx
com.mongodb.MongoClientException: Sessions are not supported by the MongoDB cluster to which this client is connected
This is because MongoDB multi-document transactions require the existence of at least a single replica set. Of course, a production MongoDB should be deployed in a replica set of no less than three (3) replicas. One (1) Mongo node is the primary (accepting writes from the application) and the writes are replicated to the other two (2) Mongo nodes, which serve as secondaries. If the primary fails, one of the secondaries is elected to take its place as the primary, while continuing to replicate data to the other secondary for redundancy. For our project, we define and run a replica set via docker-compose.
Implementation
Taking into consideration all the above, the implementation is rather straightforward:
xxxxxxxxxx
(rollbackFor = Exception.class)
public void deleteNodes(int treeId, int nodeId) throws Exception {
// ... perform your validations etc.
List <Node> nodes = nodeRepository.getSubTree(treeId, nodeId, 1L).orElseThrow(NotFoundException::new);
var target = nodes.get(0);
if (!CollectionUtils.isEmpty(target.getDescendants())) {
target.getDescendants().forEach(n -> n.setParentId(target.getParentId()));
nodeRepository.saveAll(target.getDescendants());
}
nodeRepository.delete(target);
}
Notice that we invoke the getSubTree() method with maxDepth = 1. This is because we want to limit the depth of the recursion to only the immediate descendants of the node to be deleted. You can try to delete a node by executing:
xxxxxxxxxx
curl --location --request DELETE 'http://localhost:8080/app/1001/100'
Check the response times, but also, the simplicity of maintaining the data model versus more complex solutions.
Insert and Update Node
Insert node is rather straightforward. Depending on your use cases, the user interfaces you supply to a user, etc. you may pass a single node or a hierarchy of nodes to be inserted under an existing parent with a given node Id or even to introduce a new tree. By having only to maintain the parent Id, it all comes to validation logic before saving and bulk-inserting multiple documents in the end. A skeleton implementation can be seen here, which you can extend and measure its performance according to your needs.
For updating the node, let's say we just want to move a node to a different parent. Then, we don't even need recursion, the implementation can be as simple as the following:
x
(rollbackFor = Exception.class)
public void move(int treeId, int nodeId, int newParentNodeId) throws Exception {
// ... perform validations etc.
var node = nodeRepository.findDistinctByTreeIdAndNodeId(treeId, nodeId).orElseThrow(NotFoundException::new);
node.setParentId(List.of(newParentNodeId));
nodeRepository.save(node);
}
You can try to move a node by executing this code:
xxxxxxxxxx
curl --location --request PUT 'http://localhost:8080/app/1001/100?newParentNodeId=104'
Integration Tests
In order to be able to run Integration Tests as close as possible to a real environment, we avoid using an Embedded MongoDB. Instead, we combine the following maven plugins:
- The maven-failsafe-plugin: So, we run integration tests at the maven-verify step.
- The docker-compose-maven-plugin: To utilize docker-compose and instantiate a MongoDB replica set at maven-verify step. When the tests are completed, the plugin takes care of the necessary cleanup actions.
To run integration tests, simply execute from your terminal this code:
xxxxxxxxxx
mvn clean verify
Note that this is a fixed port approach that may not be suitable when you run multiple CI pipelines on a build server. For more flexibility, you might want to check for any developments on the Testcontainers MongoDB Module and the MongoDB-replica-set project.
Conclusion
There are many ways out there to deal with hierarchical data and graphs in general such as:
- Relational databases like Oracle, MySQL, and PostgreSQL offer recursive SQL clauses. Moreover, there are relational models like Adjastency list, Path enumeration, Nested sets, and Closure tables to choose from, based on your needs and access patterns
- On the other hand, there are Native Graph databases like Neo4j, where relationships are first-class citizens, nodes point directly to other nodes and there is efficient relationship traversal. In this case, however, the query language may be more complex, there may be consistency concerns and increased operational complexity
- NoSQL databases like MongoDB lack relationships but with the addition of
$graphLookupoperation and simple document design, many use-cases can be covered
As a common rule of thumb what you should avoid by all means is to perform recursion at the application level. The more "static" your dataset is the more flexibility you have to select its data model. In this article, we demonstrated how you can perform efficient, index-based recursive queries using Java and Spring. If you already have MongoDB in place then it may be worthwhile to investigate this approach before introducing another dependency in your infrastructure.
Opinions expressed by DZone contributors are their own.
Comments