Writing Indexes in Java by Using Right Collection
The author explains the main idea of indexes and how to create them in Java. Creating fast search using the right data structures.
Join the DZone community and get the full member experience.
Join For FreeWhat Index Is and How To Use It in Java
An Index is a structure that facilitates search in your data. Is a pretty general term and doesn't belong to some language or database. In order to explain it let's create a way to search users for specific criteria like name, id, birth date, etc.
Quickly Searching Among Millions of User Entries
Let's assume that we have 1 million users. As a requirement, we have to expose API to search users by specific criteria. Obviously, simple iteration will take too much time. So let's sort this problem using indexes (or simply saying by pre-generating some data that accelerate lookup during API calls). So first place let's define our User class and Search interface:

Using Only Default Java Collections
In our service, we use only default Java Collections. If you are not familiar with them and don't know what data structures they use it would be a bit difficult to read. One of the main ideas is to use only classical Java Collections in order to quickly create indexes. Meanwhile, creating your own indexes is not that difficult.
Searching Unique Users by ID
As the first API to implement we create indexes for quick access to unique users. The easiest way to do it is to keep each user id as a key and user as a value in HashMap.
On average such a solution will provide constant complexity and it's actually a perfect case.
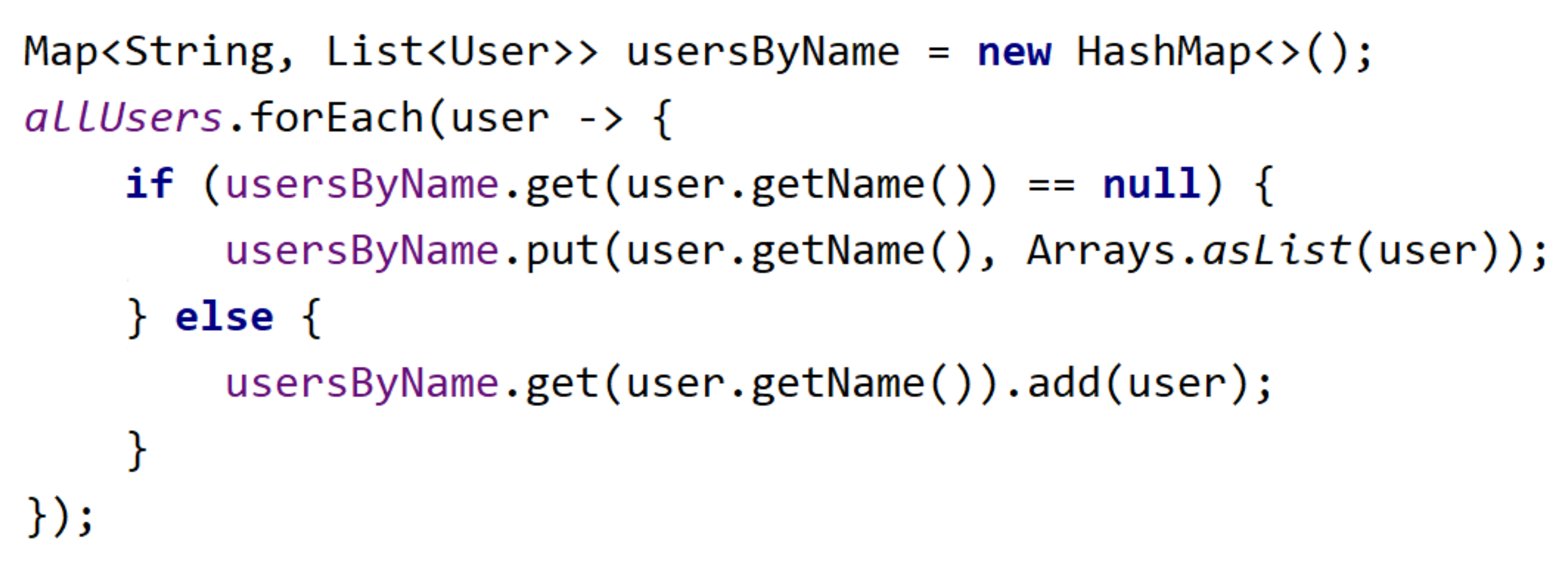
Searching Users by Non-unique Name
Now the case is more complex. The user's name is not unique and we expect to return a list of users for a specific name. The solution will be the same - a Hashmap with the user's name and a list of users with the same name. Complexity is still the same - constant
Searching Users by Age (Less Than Specified)
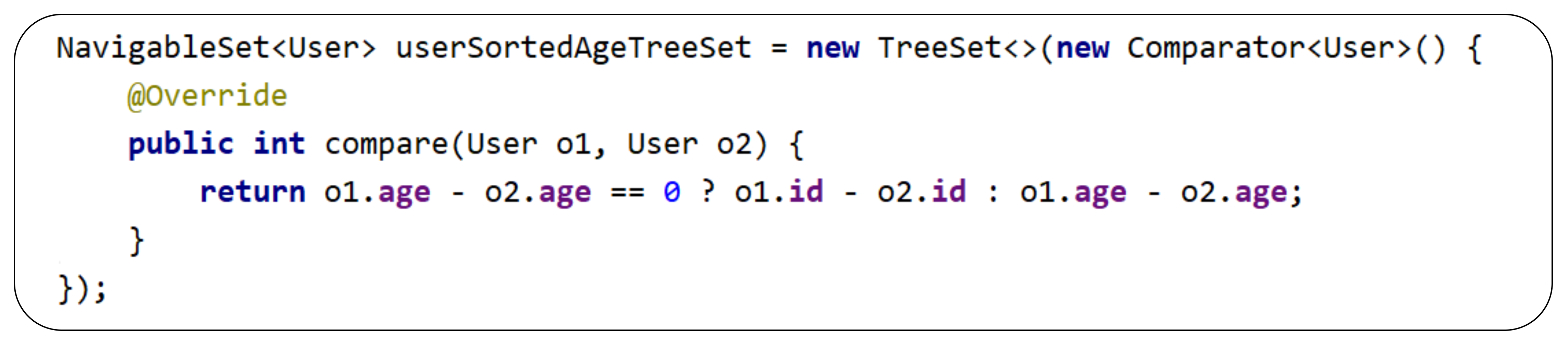
Now we create an index when the requested age is not known and we can't create a list for each key (it will cost a lot of memory e.g. 1M lists). So the classical solution for searching is a tree-based index. So for our case, we use the TreeSet collection. Having a tree search process will be slower than constant but still acceptable.
TreeSet hides inside a binary tree. This tree build tree is defined in the Comparator passed to the constructor. Basically, the comparator is only required to compare two nodes. If the comparator returns 0 it means that one of the nodes will be removed. In our case, we keep all users, so implementation will look like this:
Before we fetch all users with ages less than specified we have to review once again how this tree is built:
- We use age to decide node position (if comparator returns negative then left, if positive - right and if 0 then node is not added)
- In our case, all users have to stay in the tree. So when the age is the same comparator should return 0 and skip one user. Instead of it, we compare by id (which is unique)
To clarify internal structure let's draw a possible tree:
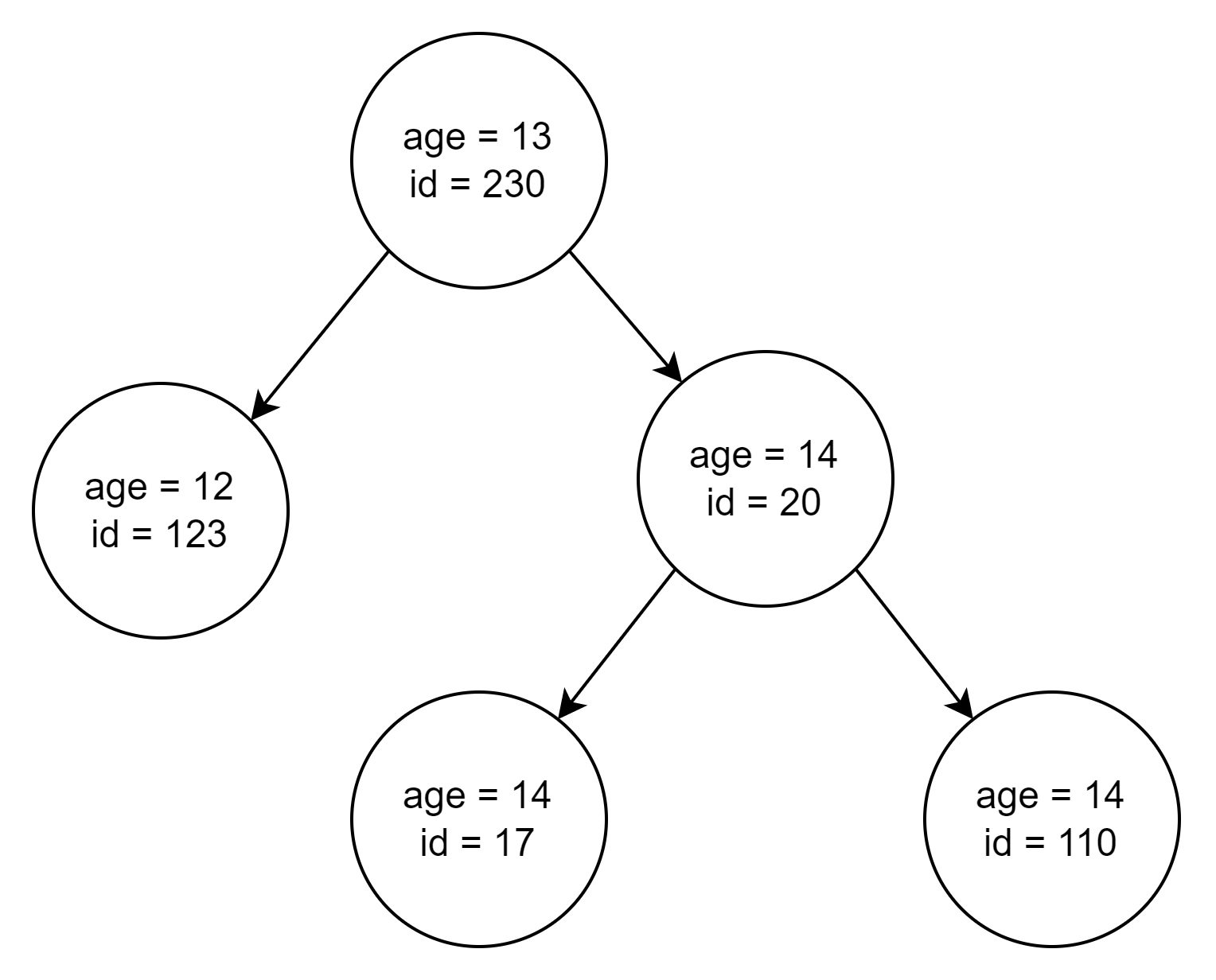
So now if we fetch users with users younger than 14 we have to find the most "right" node. From the image, you can realize that most "right" is the one with the biggest id (which is Integer.MAX). Now realizing it we can use headset method from TreeSet:
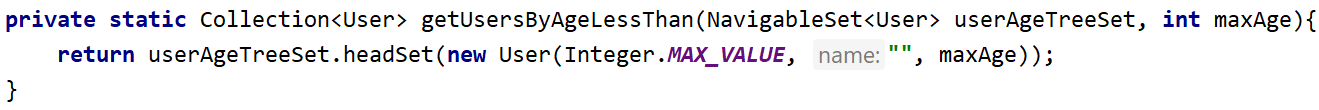
Such a method will return all users with an age less than maxAge with log complexity.
Searching Users by Age (Between Dates)
Almost in the previously shown way we can use TreeSet in order to build the age-based index. The only difference, in that case, is how to fetch a subset between dates. As in the previous example, we need to also select most "left" and "right" nodes by using integer min and max values and subsetmethod:

Some More Examples
What has been shown so far looks pretty obvious. Let's imagine a more complex case when clients need to fetch all users with names starting with 3 specified characters. Might you have seen such a feature when you start typing in google and it almost instantly shows you results?
How can it be implemented? In the same way by preparing indexes.
So shortly requirements are:
- client request 3 chars and API returns all users with names starting with it
- API response should be quick (well there is no fixed time requirement it rather means that complexity has to be constant or at least logarithmic)
Again Using HashMap we can create such indexes easily. The only thing we need is to use the first 3 chars of each name and save them:

This example is almost identical to getUsersByName but I used it to reveal how a known feature with autocomplete is working.
Custom Indexes Without Java Collection Does It Worth It?
The short answer - No. Default collections are well-known and reliable. They give you constant and log complexity from the box. And it's more than enough but in some cases, especially for real-time applications things, you might write your own index.
Indexes Disadvantages
Indexes bring performance but you have to pay for it. Among all cons there are two main:
In our example, we made the assumption that no users will be added or removed. In reality, such data changes might be costly (not for all indexes eg tree or linked-based structures don't consume much time and memory on every update). So you have to keep in mind that while the index is being recalculated your API will be on hold (or provide outdated data).
Opinions expressed by DZone contributors are their own.
Comments