Demystifying the Magic: A Look Inside the Algorithms of Speech Recognition
Discover the mechanics that make speech recognition possible. Understanding the increasingly common voice-user interface (VUI) for applied AI could give you an edge.
Join the DZone community and get the full member experience.
Join For FreeIt seems every commercial device now features some implementation of, or an attempt at, speech recognition. From cross-platform voice assistants to transcription services and accessibility tools, and more recently a differentiator for LLMs — dictation has become an everyday user interface. With the market size of voice-user interfaces (VUI) projected to grow at a CAGR of 23.39% from 2023 to 2028, we can expect many more tech-first companies to adopt it. But how well do you understand the technology?
Let's start by dissecting and defining the most common technologies that go into making speech recognition possible.
The Mechanics of Speech Recognition: How Does It Work?
Feature Extraction
Before any "recognition" can take place, machines must convert the sound waves we produce into a format they can understand. This process is called pre-processing and feature extraction. The two most common feature extraction techniques are Mel-Frequency Cepstral Coefficients (MFCCs) and Perceptual Linear Predictive (PLP) coefficients.
Mel-Frequency Cepstral Coefficients (MFCCs)
MFCCs capture the power spectrum of audio signals, essentially identifying what makes each sound unique. The technique starts by amplifying high frequencies to balance the signal and make it more legible. The signal is then divided into short frames, or snippets of sound, lasting anywhere between 20 to 40 milliseconds. Those frames are then analyzed to understand their frequency components. By applying a series of filters that mimic how the human ear perceives audio, MFCCs capture the key, identifiable features of the speech signal. The final step converts these features into a data format that an acoustic model can use.
Perceptual Linear Predictive (PLP) Coefficients
PLP coefficients aim to mimic the human auditory system's response as closely as possible. Similarly to MFCCs, PLP filters sound frequencies to simulate the human ear. After filtering, the dynamic range — the sample's range of "loudness" — is compressed to reflect how our hearing responds differently to various volumes. In the final step, PLP estimates the "spectral envelope," which is a way of capturing the most essential characteristics of the speech signal. This process increases the reliability of speech recognition systems, especially in noisy environments.
Acoustic Modeling
Acoustic modeling is the heart of speech recognition systems. It forms the statistical relationship between the audio signals (sound) and phonetic units of speech (the distinct sounds that make up a language). The most widely used techniques include Hidden Markov Models (HMM) and, more recently, Deep Neural Networks (DNN).
Hidden Markov Models (HMM)
HMMs have been a cornerstone of pattern recognition engineering since the late 1960s. They are particularly effective for speech processing because they break down spoken words into smaller, more manageable parts known as phonemes. Each extracted phoneme is associated with a state in the HMM, and the model computes the probability of transitioning from one state to another. This probabilistic approach allows the system to infer words from the acoustic signals, even in the presence of noise and different individuals' variances in speech.
Deep Neural Networks (DNN)
In recent years, closely paralleling the growth and interest in AI and machine learning, DNNs have become the first choice for natural language processing (NLP). Unlike HMMs, which rely on predefined states and transitions, DNNs learn directly from the data. They consist of multiple layers of interconnected neurons which progressively extract higher-level representations of the data. By focusing on context and the relationships between certain words and sounds, DNNs can capture much more complex patterns in speech. This enables them to perform better in terms of accuracy and robustness compared to HMMs, with additional training to adapt to accents, dialects, and speaking styles—a huge advantage in an increasingly multilingual world.
Looking Ahead: Challenges and Innovation
Speech recognition technology has made great strides but, as any user will recognize, is still far from perfect. Background noise, multiple speakers, accents, and latency are yet unsolved challenges. As engineers have grown to recognize the potential in networked models, one promising innovation is the use of hybrid solutions that leverage the strengths of both HMMs and DNNs. An additional benefit of expanding AI research is the application of deep learning across domains, with Convolutional Neural Networks (CNN), traditionally used in image analysis, showing promising results for speech processing. Another exciting development is the use of transfer learning, where models trained on large datasets can be fine-tuned for specific tasks and languages with relatively smaller companion datasets. This reduces the time and resources required to develop performant speech recognition for new applications, allowing for a greener approach to repeat model deployments.
Bringing It All Together: Real-World Applications
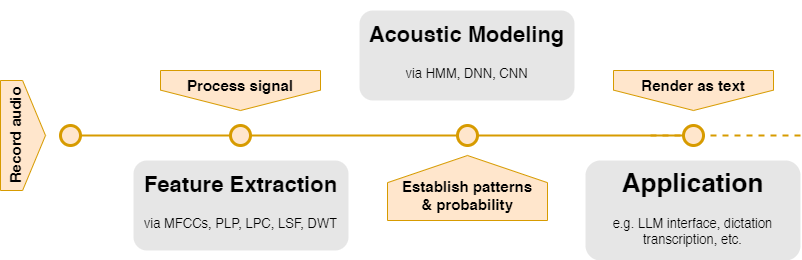
To recap, feature extraction and acoustic modeling work in tandem to form what is known as a speech recognition system. The process begins with the conversion of sound waves into manageable data using pre-processing and feature recognition. These data points, or features, are then fed into acoustic models, which interpret them and convert the inputs into text. From there, other applications can readily engage with the speech input.
From the noisiest, most time-sensitive environments, like car interfaces to accessibility alternatives on personal devices, we are steadily trusting this technology with more critical functions. As someone deeply engaged in improving this technology, I believe understanding these mechanics is not just academic; it should inspire technologists to appreciate these tools and their potential to improve accessibility, usability, and efficiency in users’ experiences. As VUI becomes increasingly associated with large language models (LLM), engineers and designers should familiarize themselves with what may become the most common interface for real-world applications of generative AI.
Opinions expressed by DZone contributors are their own.
Comments