Leveraging Change Data Capture for Fraud Detection using Arcion Cloud
Still relying on overnight processes to drive your decision making? Maybe it’s time to consider an evaluation of the CDC pattern.
Join the DZone community and get the full member experience.
Join For FreeDuring the height of the business intelligence (BI) craze earlier in my career, I worked with an internal reporting team to expose data for extract, transform, and load (ETL) processes that leveraged data structures inspired by Ralph Kimball. It was a new and exciting time in my life to understand how to optimize data for reporting and analysis. Honestly, the schema looked upside down to me, based on my experience with transaction-driven designs.
In the end, there were many moving parts and even some dependencies for the existence of a flat file to make sure everything worked properly. The reports ran quickly, but one key factor always bothered me: I was always looking at yesterday’s data.
Due to the increase in size, velocity, and types of data being produced in modern tech stacks, real-time data has become the holy grail for enabling up-to-date and proactive analysis and data-driven business decisions. When we use the common batch style approach to data ingestion, the data is always stale, and it can’t answer the pressing questions.
To enable these real-time use cases, the data must be available in the storage layer and processing layers currently implemented at an organization.
For many years—and this is still true today—transactional (OLTP) systems like Oracle, Postgres, and SQLServer are at the core of most businesses, and they’re central to downstream analytics and processing. This work is typically done by a team of data engineers who spend months building pipelines that pull and transform data from those OLTP systems into analytics data lakes and warehouses (OLAP).
Over the past decade, organizations of all sizes have spent billions of dollars with the goal of improving their capacity to process data and extract business value from it. However, only 26.5% of organizations believe they have achieved the vision of becoming a data-driven company. One of their biggest hurdles to achieving the “Data Utopia” state is gaining that ability to build reliable data pipelines that extract data from OLTP systems while ensuring data consistency and ease of scale as the data grows.
This made me wonder if there was a better way to accomplish the same results without a hefty overnight process. My first thought was to explore the change data capture (CDC) pattern to meet those needs.
Why Change Data Capture (CDC) Matters
Extracting data from OLTP systems can be cumbersome, for reasons that include:
Unlike SaaS tools, enterprise databases don’t have flexible APIs that you can leverage to react to data changes.
Building and maintaining pipelines to extract data from OLTP systems, especially as a business scale, is complex and costly to ensure data consistency.
On the other hand, CDC is a software design pattern that determines and tracks database updates as they occur. This allows third-party consumers to react to database changes, vastly simplifying the process of retrieving data changes in the OLTP system. CDC events can be sourced through several different approaches:
Time-based: uses required timestamp column as a source for data
Checksum: leverages checksum on tables in source/target, using differences as a source for data
Log-based: reads database logs as a source for data
For this publication, we will focus on the log approach. Log-based CDC is commonly accepted as the best option for real-time use cases because of its lightweight approach to producing data changes. Time-based and checksum approaches require more overhead and CPU, often using queries against the database to find the newest changes to a dataset. CDC using log-based reads can shortcut these expensive and time-consuming queries, capturing changes by going straight to the source: the logs.
Using the log approach, database writes are handled via transaction logs, often referred to as changelogs. CDC solutions listen to those same logs and will generate events where established conditions apply. By using the logs, the CDC service gains access to the same data without waiting for the transaction to commit and then making a request to the database for that data.
By implementing a CDC solution, third-party data consumers have quicker access to the database changes. Additionally, data consumers do not require access to the actual database since they are only interested in updates in those changelogs. Not only does CDC allow near instant data replication, but it also has minimal impact on the performance of production databases. Because CDC only accesses the logs and doesn’t pose any security threat, the IT teams love it too. The unique characteristics of CDC made it widely adopted by many tech leaders that real-time use cases are key to their business models (e.g., Shopify, Uber, CapitalOne).
To understand CDC more, let’s consider a use case related to the financial industry.
Detecting Fraud Using CDC
Fraudulent transactions are a major concern for the financial industry. In fact, this report noted credit card fraud increased 44.7% in 2020 over prior-year values.
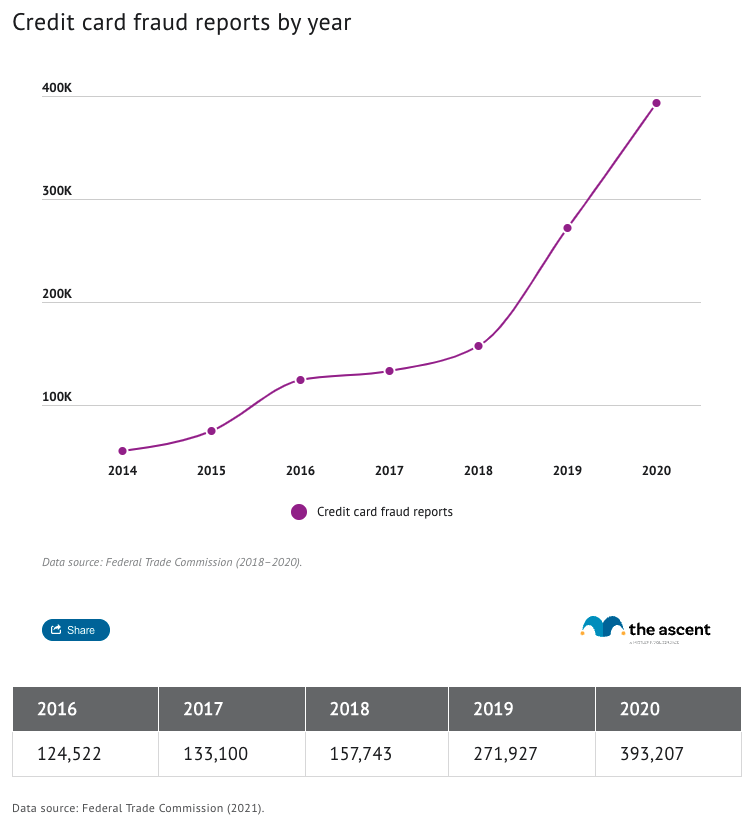
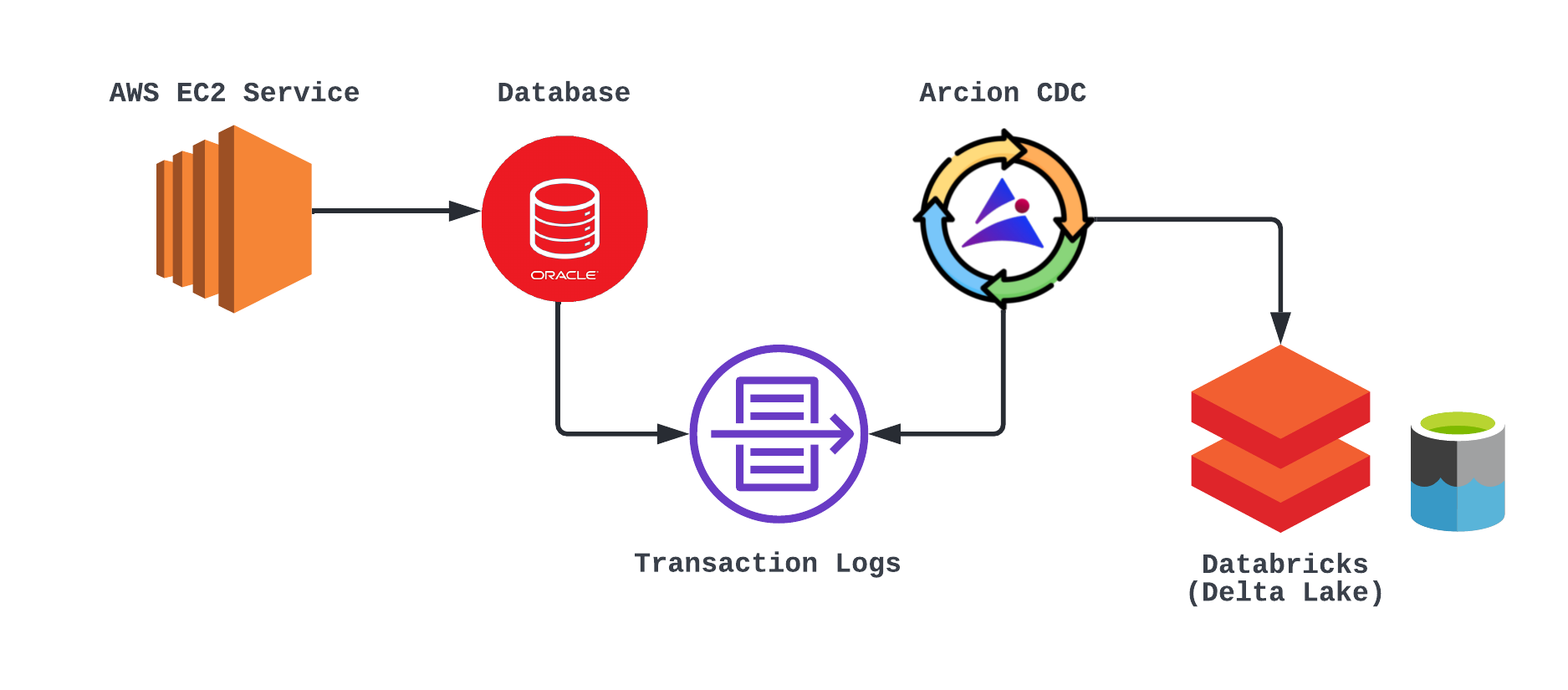
Let’s assume WorldWide Bank, a fictional financial institution, wants to improve the speed at which they recognize fraud. Their current approach relies on an ETL process to query against their Oracle database and generate reports. They would like to explore using Arcion CDC in order to process against the Oracle database changelogs to generate events that will feed their Databricks Delta Lake prototype. Like many organizations, WorldWide Bank has a variety of transactional systems, including a large subset of data in an Oracle database. They have a growing need to provide more machine learning (ML) capabilities as well as combine various datasets in an easy-to-use environment for analysis, which has led to their adoption of Databricks for a data lake.
The relational data model of Oracle, along with the hassle of bringing other ancillary data sources into Oracle and the lack of support to run ML directly on Oracle, makes Databricks an easy choice. But, this approach leads to another challenge: how to source the Oracle transactions into Databricks in a timely manner. To improve the speed at which they can detect fraud, it is critical to their operation to be able to source CDC events from Oracle quickly, depositing them into their Databricks data lake for further processing and detection.
Regarding their decision to use Arcion CDC, why might WorldWideBank choose Arcion and not another option, even open source? The answers are simple. Debezium, for example, is an open-source option, but it requires the installation and running of Zookeeper, Kakfa, and MySQL—all before you can even begin to use or install the tool. This alone would require a large team of engineers to simply install and maintain the tech stack.
While other tools—like Fivetran’s HVR for CDC—might also offer free trials, Arcion has two free options to choose from: a 30-day trial with a download or a 14-day trial on the cloud. This is convenient for testing, so it made Arcion an easy choice when selecting a CDC solution.
At a high level, the Arcion CDC architecture can be illustrated as follows:

If this approach goes well, WorldWide Bank will expand the design to replace other source databases in Oracle, Microsoft SQL Server, and MySQL.
Prototyping Arcion CDC
In order to simulate the WorldWide Bank scenario, let’s assume inbound transactions are being written to an Oracle database table called TRANSACTIONS, which has the following design:
![]()
An example record in the TRANSACTIONS table would appear as shown below using JSON format:
{
"id" : "0d0d6c35-80d0-4303-b9d6-50f0af04beb3",
"post_date" : 1501828517,
"trans_date" : 1501828517,
"type" : 1017,
"card_number" : "4532394417264260",
"account_number" : "001-234-56789",
"amount" : 27.67,
"vendor_number" : 20150307,
"vendor_location_latitude" : 42.3465698,
"vendor_location_longitude" : -71.0895284,
"vendor_name" : "Berklee College of Music Bookstore"
}In order to leverage the power of Databricks and Delta Lake for fraud prevention, we need to set up a CDC service to act as middleware between the two systems. The TRANSACTIONS table design and data in Oracle need to exist as a Bronze (Ingestion) layer within Delta Lake. Once the existing data has been ingested, all future transactions will leverage the CDC stream included in the Arcion solution.
Getting started with CDC begins with establishing a free Arcion Cloud account and obtaining the connection/login information for the Oracle database and Databricks system.
After gathering this information, I started a new replication in the Arcion Cloud application and defined the replication and write modes between the source and target database:
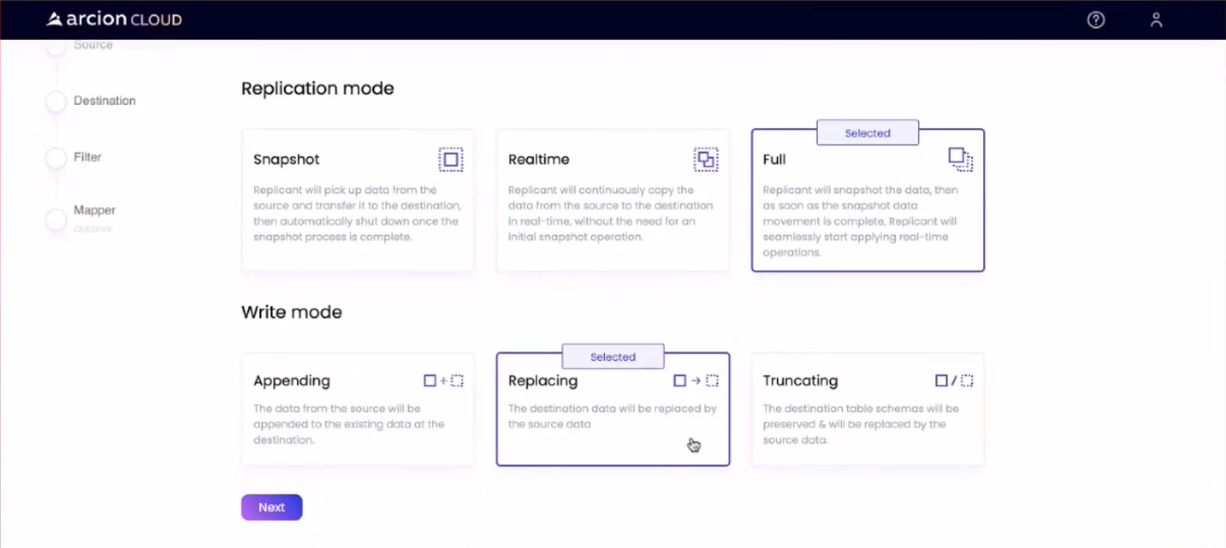
In this case, I selected the Full replication mode. This lets me replicate a full snapshot of the database and enables real-time operations for all future updates. I chose the Replacing write mode option to fully replace any existing database design and data on the target host.
Next, I established a connection to the Oracle database, similar to what is shown below:
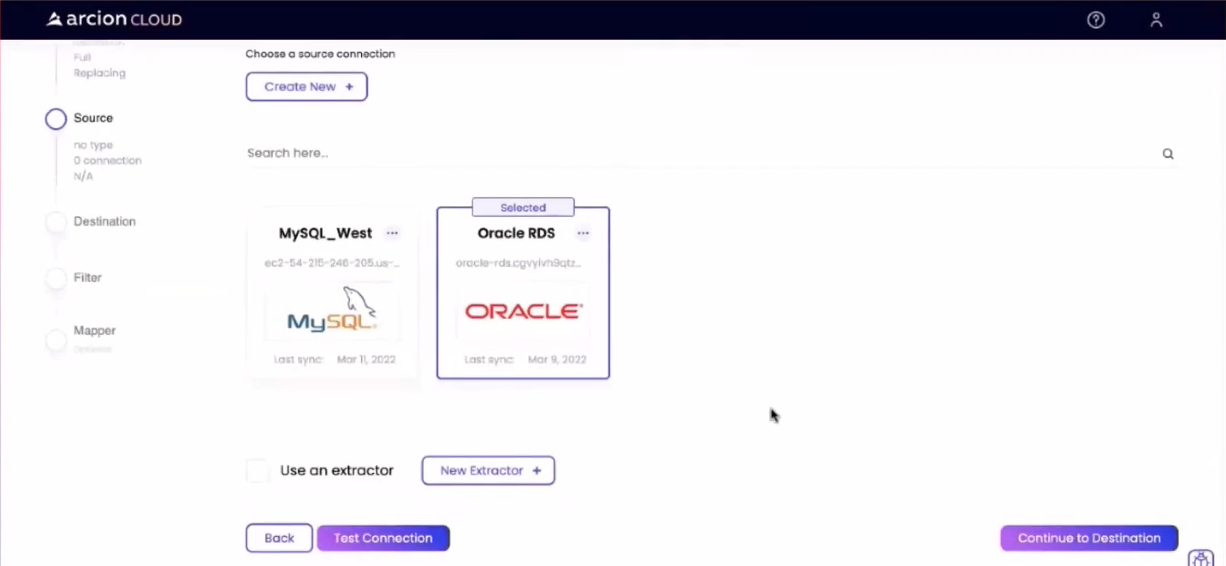
We can validate the connection by using the Test Connection button. Once ready, the Continue to Destination button moves the progress to the next step.
On the Destination screen, I can add a connection to the Databricks service and select it as the target for the replication being created:
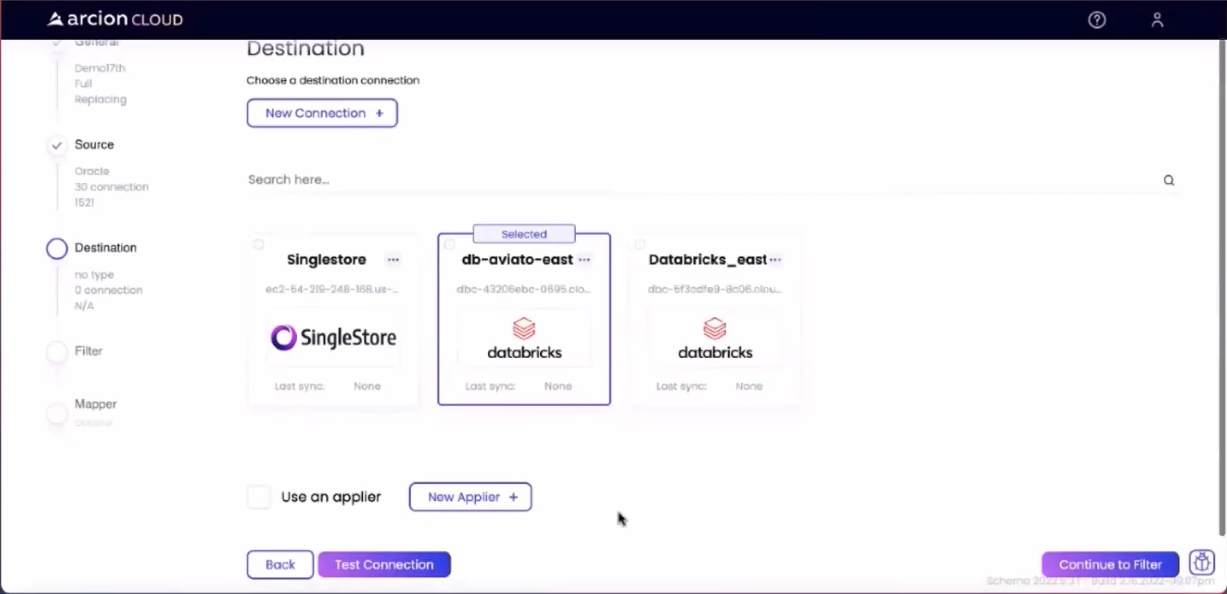
Using the Continue to Filter button, I was able to proceed ahead to the filter screen shown below:
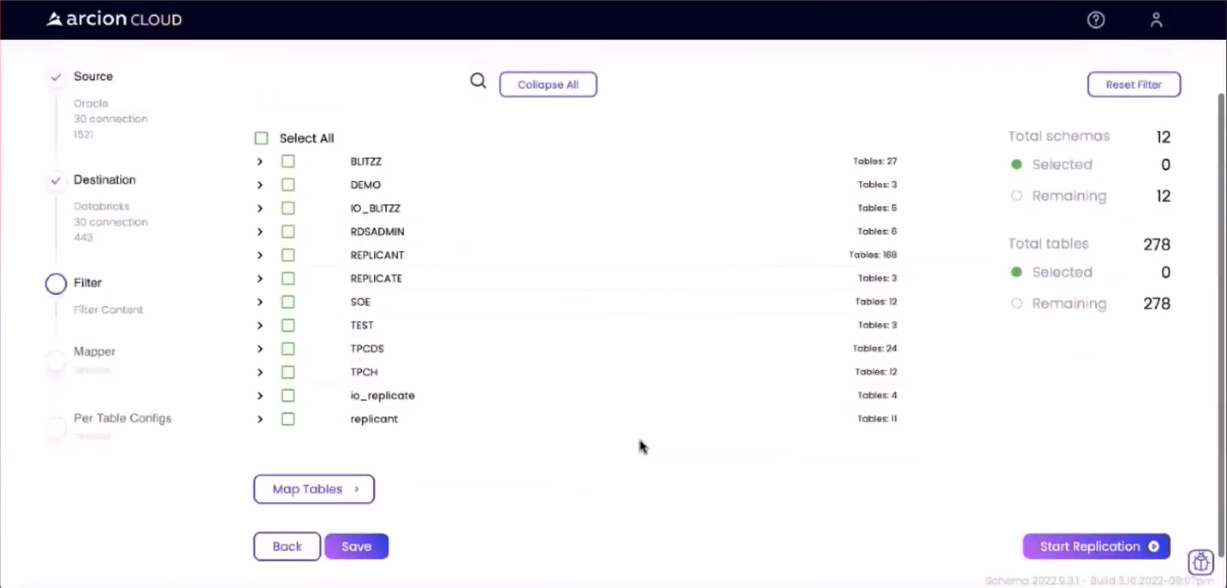
I selected the source database and tables on the Filter screen. Once ready, all I had to do was click the Start Replication button to complete the following tasks:
Remove any existing databases in Databricks that match the current replication request
Establish new databases in the Databricks environment
Perform a snapshot replication of all existing data that matches the filters provided in the replication request
Establish a CDC stream between Oracle’s changelogs and Databricks for all future transactions.
I completed all of this with zero code.
Once the replication started, I could monitor the process in the Arcion Cloud user interface:
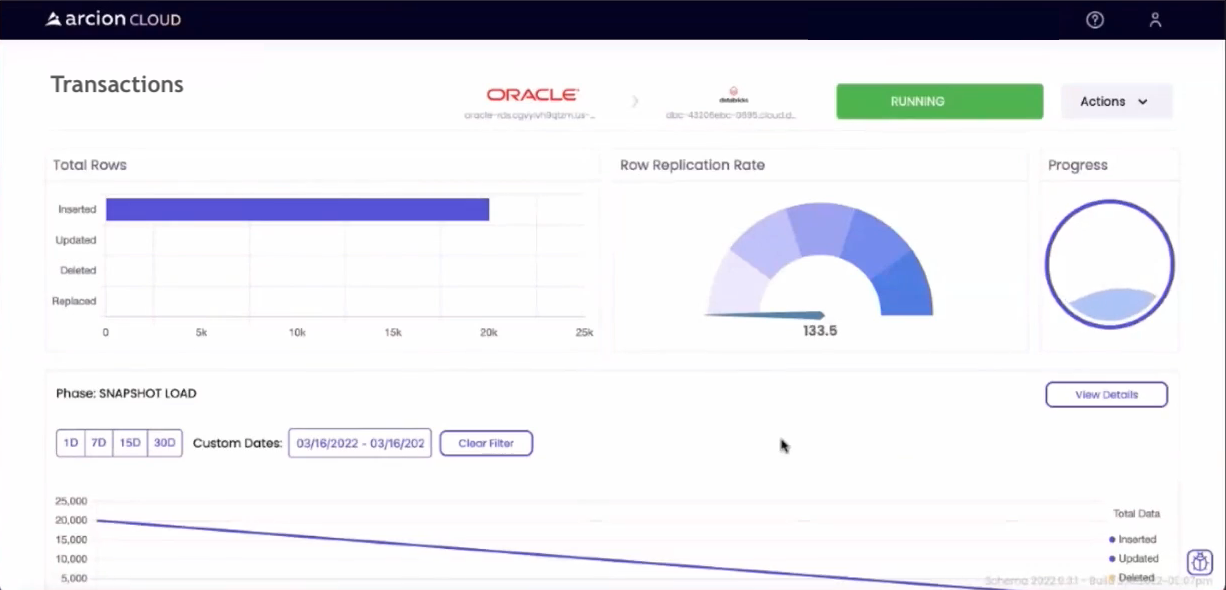
As noted above, the snapshot will be performed first, then any future updates will arrive via the CDC stream. Once completed, the user interface is updated as shown below:
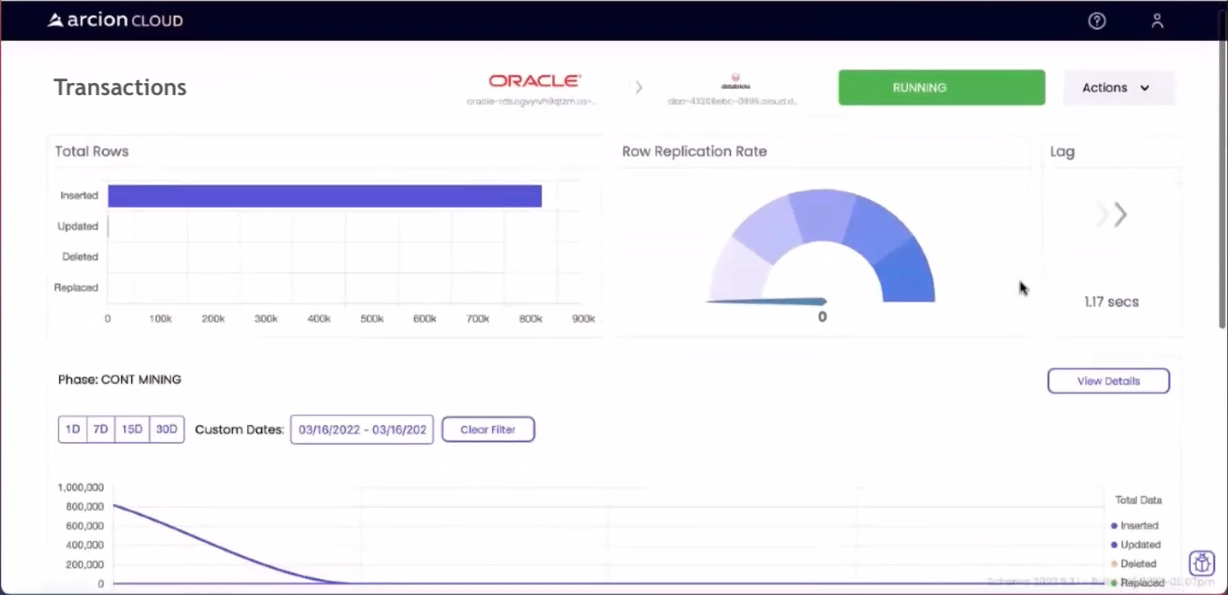
At this point, the Bronze (Ingestion) layer of Delta Lake is ready for use.
The ingested data can be transformed into Silver (Redefined Tables) and Gold (Feature/Agg Datastore) layers, allowing us to leverage the benefits of Delta Lake functionality to detect and mitigate fraud. Going forward, the expectation will be that all data from the Oracle TRANSACTIONS table will automatically find its way into Databricks.
We have one final step of our CDC ingestion into the data lake. Prior to running the ML fraud model for prediction output, we would run pre-built dbt tests or Great Expectations checkpoints to ensure we have received new records since our last fraud detection run. This would give WorldWide Bank confidence that full end-to-end CDC from Oracle is flowing into Databricks as expected.
I find it very impressive that I can establish this level of design by merely following a series of steps within the Arcion Cloud user interface without writing a single line of program code. For the WorldWide Bank use case, establishing similar replications for their other databases should be just as easy, allowing all fraud detection to be processed in one single system.
Conclusion
Since 2021, I have been trying to live by the following mission statement, which I feel can apply to any IT professional:
“Focus your time on delivering features/functionality which extends the value of your intellectual property. Leverage frameworks, products, and services for everything else.”
- J. Vester
Arcion provides CDC functionality without reinventing the wheel. Their platform allows feature teams to utilize a no-code approach to establishing source and target data sources, plus everything needed to route inbound database transactions to a secondary source before they are written to the database.
In addition, Arcion can be deployed in multiple ways. Financial or health care enterprises, for example, maybe have security or compliance requirements. They can deploy self-hosted Arcion on-prem or in a virtual private cloud. For companies without the DevOps resources to manage their own deployments, fully-managed Arcion Cloud would be a good option.
Furthermore, the ease at which snapshot and CDC streaming replications can be established allows for additional data sources to leverage the same processing logic found in the Databricks Delta Lake implementation. This ultimately provides a “don’t repeat yourself” (DRY) approach by allowing one source of logic to focus on fraud detection.
The Arcion team is certainly adhering to my personal mission statement and allowing their customers to remain focused on meeting corporate priorities.
If I were working with that same BI team that I mentioned in the introduction, I would certainly recommend exploring Arcion Cloud to meet their needs. This would provide the opportunity for real-time data rather than relying on day-old data to make decisions.
Have a really great day!
Opinions expressed by DZone contributors are their own.
Comments