Let’s Use AI To Fix Bugs and Write Documentation
AI Coding assistants can produce code from written intent. What if it handled the reverse route too and produced useable documentation for legacy systems?
Join the DZone community and get the full member experience.
Join For FreeLast month I shared my first experience using ChatGPT and GitHub Copilot. I was impressed, but not overwhelmed. AI suggestions can be accurate, but only to the extent that your question is specific and to the point. It can’t read your mind, but it can find solutions to well-defined tasks that have been solved before – and for which there may already exist a perfectly good library solution. Knowing what to build remains the hardest part of all and we are nowhere near automating the entire journey from idea to code.
I have two more points to make on the topic. First, since we as programmers are required to stay in the driver’s seat for a while, we had better stay sharp. Secondly, I believe the focus should be less on solutions that convert ideas to code. I personally can’t wait for useable AI that can do the reverse: scan an undocumented tangle of eighty microservices and explain to me in clear English what it is all about, because nobody bothered to keep documentation up to date.
The Holy Grail: From Idea to Code
New programming languages move ever further away from the hard math of moving bytes. They free up head space to deal with the challenge of modelling the real world in executable code at an ever-higher level of abstraction. But even no-code solutions or graphical workflow engines are still programming languages. They only take a different form of coding skills, which is bad news for math talents. Eventually, you start a dialogue with the AI, explain the task you want to be automated, and it will do it, without you the ‘programmer’ seeing (or caring about) how it is implemented.
That perfect stage is the equivalent of a fully autonomous self-driving car. You tell it where you want to go and it takes you there. It’s so reliable you don’t need a steering wheel or accelerator. In fact, it’s only right you can no longer interfere. You wouldn’t know how to anymore. We’re not there yet. The legal minefield surrounding liability is a bigger hurdle than the state-of-the-art, which does a better job than many drivers. Until we can command our own robot chauffeur, we will get increasingly sophisticated assistance that yet requires a fully competent driver. Paradoxically, this doesn’t make driving safer. The more trustworthy the AI, the more tempted you are to disconnect from surrounding traffic. The rare moment that you need to spring into action, you’ll find your skills have atrophied (if you were paying attention at all).
The analogy with AI-assisted software writing is obvious. As humans, we can only confidently surrender control if the process is flawless and predictable, like a compilation. The idea as expressed in human language and translated into executable software should be like Java code as it is converted into byte code by the compiler. Few programmers know in detail how that works. Most don’t have a clue. They can afford not to know because it’s a robust, predictable process.
Neither Co-Pilot nor Autopilot
Not to be pedantic, but GitHub Copilot is really an autopilot. In aviation, a co-pilot is a fully capable human being. The plane’s autopilot is a collection of advanced tools that help but don’t replace the pilot. But they do have the power to make you lazy. Like the driver and pilot, the programmer cannot afford to lose her sharpness. She must have good judgment over the suggestions offered.
Traditional autocomplete has made us lazy. New AI flavours will make us even more so. If you are not aware of thread safety and don’t know what a re-entrant lock, concurrent collection or atomic integer is, you can’t instruct the AI to create one or recognize that you need one. I’m still preparing for the OCP-17 exam. I’m thrown between my conviction that as a self-respecting senior developer, you should know this stuff, and my annoyance over the subject matter and line of questioning. What do I learn by poring over convoluted snippets to spot a missing throws declaration? Why should I know the exact signatures of the major static methods in the Files class? You use it, or you lose it, and I know I’ll quickly forget much of it. My brain has a weird efficiency. What really sticks are movie quotes and song lyrics. Maybe I should set the NIO API to music.
But the folks at Oracle do have a point with their carefully confusing little train wrecks. It hones your powers of perception, and it’s a recognition of the sobering fact that you spend many hours of your career reading terrible code, some of it your own. Too many books and courses teach you how to write new code. Not many appreciate the value of learning good maintenance skills: making piecemeal improvements and bug fixes that don’t crash the system. Nobody likes doing it, so let the AI have a crack at it. If it’s so smart, let it plough through stack traces in server logs and come back with the root cause for that outage. That would be impressive.
From Implementation Back to Intent
How many rewrites of legacy systems could have been prevented if we hadn’t lost the overview of how the parts fit together? But nobody bothered to keep the documentation up to scratch. (If you think the documentation for large enterprise systems is expensive, try a full rewrite). The same applies to the regular chore of updating libraries and migrating sources to newer runtime versions. Don’t do it by hand, use an initiative like OpenRewrite.
Getting from implementation back to intent (i.e., the documentation) is the next big win. We don’t need more code. We need to better understand what’s already there, with the help of AI. I’m not talking about auto-generated API docs for methods that are already self-documenting. That never conveys the intent of the big picture. I’m talking about user-friendly manuals for large enterprise systems at multiple levels of complexity. Let AI distil the intent of such a web of interconnected services from the code of its constituent parts. Turn it into understandable diagrams and explain it in plain English. Don’t cram everything into one sequence or activity diagram. Use a divide-and-conquer fashion, branching out from the big picture to individual details. I feed it a data model like this:
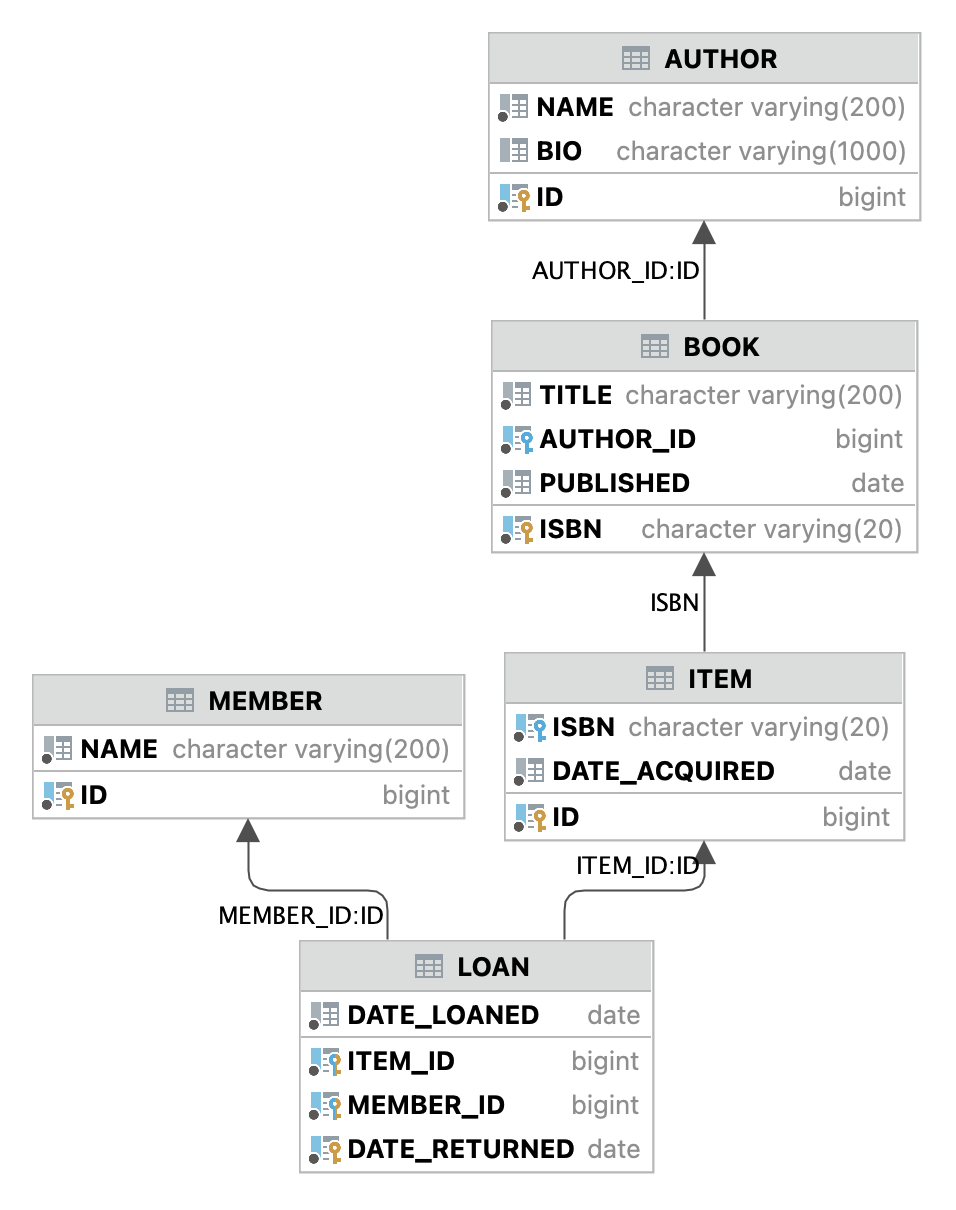
... and it returns something like this:
This data model represents a lending library for books. It stores book titles identified by their ISBN and keeps biographical data on each author. A book title can have zero or more physical copies. A book loan is registered with the id of the member, the book copy, the current date, and the date returned.
Trivial, of course. But now imagine it a thousand times more complicated and the human brain is no longer equipped to create a bird's eye view.
They say developers love to code and hate writing documentation. Maybe Microsoft should realign priorities with future versions of GitHub Copilot.
Opinions expressed by DZone contributors are their own.
Comments