Kubernetes: Beyond Container Orchestration
Explore how Kubernetes is becoming a new server for serverless architecture as we look at a few of its established enterprise patterns and buzzing use cases.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Kubernetes in the Enterprise Trend Report.
For more:
Read the Report
Kubernetes today is the most prominent and prevailing container orchestration engine. Kubernetes became central to cloud-native computing because it is open source and has a rapidly growing ecosystem. If we observe its evolution and adoption trend in the last few years, especially around the cloud-native world, it is more than "just" a container orchestration tool. It has outgrown being a container orchestration engine and is now a frontline building block of a next-generation cloud-native ecosystem.
Developers are experimenting with Kubernetes by reimagining and reestablishing it as much more than just a container manager. We will discuss a few of its established enterprise patterns and buzzing use cases in the open-source community.
Kubernetes as a Server of Serverless Computing
Enterprises with exposure and experience around Kubernetes have identified the full potential of Kubernetes as the platform that is the "server of the serverless." Serverless is now reimagined with Kubernetes, and Knative (kn) was recently launched by CNCF (the parent of Kubernetes) to abstract Kubernetes as Serverless computing. At its core, Knative consists of three modules:
- Build – build images from source
- Serving – deploys functions (image build) on Kubernetes clusters and maps scaling, routing, etc.
- Eventing – maps events and messaging ingestion with servicing
Like kubectl for Kubernetes, kn is the new, hot command on the terminal for enabling Function as a Service (FaaS) on top of Kubernetes. It takes a container image as a building block and handles everything on top of Kubernetes. Kubernetes is serverless for containers and is similar to what AWS Lambda is to function. Kubernetes as a serverless platform is accelerating its adoption across the enterprise; however, its peers like AWS Lambda, Cloud Functions, and Azure Functions are still dependent on vendor lock-in (i.e., they only work if you deploy on their cloud).
Unlike its peers, Kubernetes addresses some of the existing challenges like constraint in size of the artifact, compliances and regulations, data sovereignty, and granular control within an enterprise. The main architecture differences between serverless Knative on Kubernetes versus conventional Kubernetes come from an additional layer of abstraction. Kubernetes as Serverless eliminates repetitive configuration and build tasks.
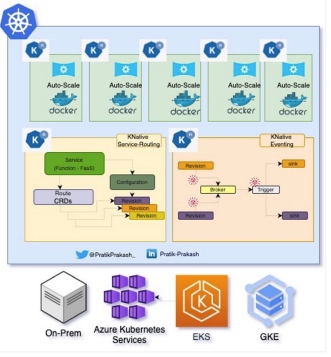
Figure 1: Serverless on top of Kubernetes
Overview of Kubernetes cluster with Knative as a serverless and event-driven platform
Knative is a new addition to the Kubernetes ecosystem, and it holds the potential to disrupt on-premises serverless options to build event-based architecture. Features like "scale to zero," "scale from zero," and in-cluster build makes Kubernetes a complete serverless platform.
Kubernetes as a Big Data and Machine Learning Platform
Kubernetes is being seen and widely adopted as a platform for big data processing and stateful data services among data science and machine learning (ML) tech stacks. It abstracts underlying infrastructure and optimizes the provisioning of elastic compute, which combines GPU and CPU under the hood. Kubernetes is great for machine learning as it natively has all the scheduling and scalability that ML requires.
Containers and Kubernetes combined are powerful and flexible for building big data software as compared to conventional data cluster setups, which have the complexity of distributed cluster management and compute scale overhead. Kubernetes leverages on-demand GPU and CPU computing to enhance big data and ML processing. Kubernetes can deliver GPU-accelerated computing and network solutions for running ML and NLP processing on the edge. Kubernetes running on a co-processor is becoming an important part of future computing. Its dynamic resource utilization is beneficial for data science workloads, while training models or feature engineering demands can scale up and down very quickly.
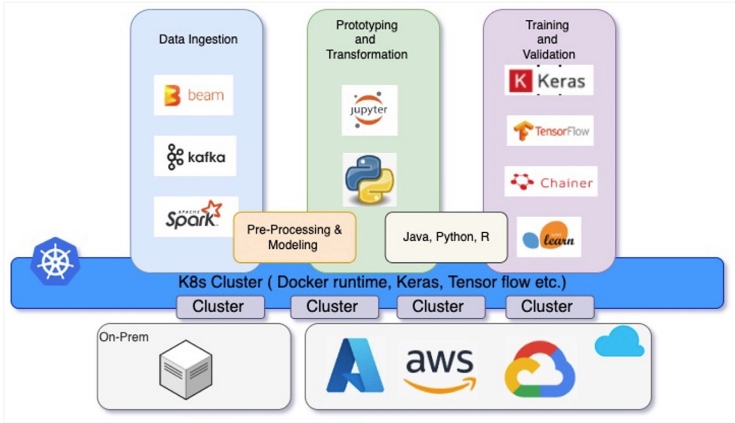
Figure 2: Kubernetes-powered big data and ML cluster
On-demand scalable coprocessor for ML processing
Frameworks like KubeFlow, Spark, Hadoop, PyTorch, TensorFlow, and more are now adopting containers. Stateful MLOps are widely adopting containers and Kubernetes for spinning multiple clusters, processing large training and test sets, and storing learned models. To simplify handling data modeling frameworks, one option is Kubeflow, an open-source ML toolkit for Kubernetes to run declarative, configurable jobs to execute.
Kubeflow abstracts and orchestrates complicated big data and machine learning pipelines that are running on top of Kubernetes. Kubernetes under the hood of ML pipelines is a staple for MLOps. It makes it easy for data scientists and machine learning engineers to leverage hybrid cloud (public or on-premises) for processing elasticity and scalability. Kubernetes enables building a neutral big data platform to avoid vendor lock-ins of cloud-managed services.
Kubernetes as a Federation for Hybrid and Multi-Cloud Cluster for the Enterprise
Kubernetes is infrastructure agnostic and is leveraged by enterprises for sophisticated container-based cluster federation. Kubernetes helps to combine a hybrid or multi-cloud setup into a single platform lump for obvious benefits.
Managed services are not the solution for everything. There is always a struggle between balancing the convenience of a public cloud versus a private sovereign cloud. Kubernetes is seen as an answer for this, as it enables multi-cloud access for seamless application delivery across the industry-standard API (Kubernetes interface). It helps to achieve regulatory compliance for enterprises with Kubernetes by abstracting private and public cloud integration as a single federated platform.
Enterprises leverage Kubernetes to avoid vendor lock-in by providing flexibility around hybrid and multi-cloud clusters. It's interesting to observe how current cloud-based architecture patterns have adopted Kubernetes. Cloud-based enterprises along with the open-source community have realized that Kubernetes is not just a container management tool. It is now evident that Kubernetes is a complete platform to host lifecycles for running an application on a hybrid or multi-cloud paradigm.
Kubernetes has been widely adopted as a Platform as a Service (PaaS). However, during early days, Kubernetes official documentation mentioned it as Container as a Service (CaaS). Recently, it is observed that Kubernetes adoption patterns and usage are way beyond CaaS, hence the updated documentation of Kubernetes as next-generation PaaS.
Kubernetes is new age PaaS, meaning:
- Kubernetes in conjunction with hyper-converged infrastructure (HCI) is a new private or hybrid cloud alternative. It gives enterprises full control of their services and regulatory sanctity.
- Kubernetes enables enterprises to achieve a single abstracted and simplified* platform to operate SRE, DevOps, and DevSecOps on top of a hybrid and multi-cloud span. (*That's debatable for sure.)
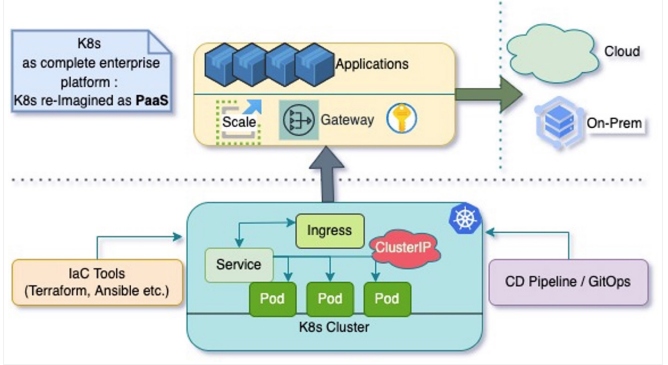
Figure 3: Kubernetes as new generation PaaS
Hybrid and multi-cloud containers federations as new generation PaaS
Conclusion
Generally, large organizations are not comfortable giving up platform controls to AWS Lambda, AWS Fargate, or Azure Functions. Kubernetes has become a de facto choice that provides the best of both worlds — control and on-prem sanity along with cloud-native compute elasticity, scalability, and resiliency that comes from a declarative containerized ecosystem. Kubernetes with open-source tools like Helm (IaC), Grafana (telemetry dashboard and alerting), and Prometheus (metric ingester) is making it a perfect recipe for a DevOps-enabled and SRE-friendly ecosystem for the enterprise.
Data science and machine learning enterprises are accelerating Kubernetes adoption as a big data processing platform. Lately, ML and big data frameworks are becoming containerized, which makes Kubernetes a preferred choice for a data clustering and modeling ecosystem under the hood. This preference also includes Kubernetes' abstracting elastic GPUs and CPUs plus its on-demand scalability with statefulness.
Kubernetes abstraction frameworks like Knative are taking Kubernetes to another level. Kubernetes is becoming a new server for serverless architecture, and it is gaining momentum. It is providing open-source alternatives for AWS Fargate and OpenShift. Kubernetes is "the wolf in sheep's cloth"; it has been reimagined into many shapes and forms beyond being "just" a container orchestration tool.
This is an article from DZone's 2022 Kubernetes in the Enterprise Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments