Knowledge Graph With ChatGPT
Analysis of the OpenAI engine to produce meaningful output from the text in the form of a knowledge graph.
Join the DZone community and get the full member experience.
Join For FreeGPT fascinates. I was keen to evaluate my fascination firsthand. This is an extension of some custom code I had written to convert natural language into a "meaningful" representation in a graph but with relatively simple text, which was about the use of natural plants for the treatment of common ailments. To set some context, I did my share of nltk/ NLP learning when I labored and converted the contents of a book to a graph took more than a few weekends and loads of stackoverflow/d3.js threads to fix my errors and clean up code.
With that experience, I set out this evening to 'test drive' the GPT engine. I took up two relatively simple use cases, with one being an attempt at summarizing the NIST 800 sp 53 control catalog in a simple graph, while the other was relatively more human imagination-driven, with me wanting to narrate a simple story of the "boy who cried wolf" using Neo4j.
The simpler use case 1 was driven by information from NIST, with the control families clearly called out. With an intent to explain this to any reader, I first requested a means to divide these families across people/ process/ technology.
Dividing the NIST 800-53 control families into categories of people, process, and technology can be a useful way to understand how different aspects of information security are related to each other. Here is one way that the control families could be divided into these categories:
People:
Awareness and Training
Personnel Security
Process:
Access Control
Audit and Accountability
Security Assessment and Authorization
Configuration Management
Contingency Planning
Identification and Authentication
Incident Response
Maintenance
Media Protection
Planning
Risk Assessment
System and Services Acquisition
Program Management
Technology:
Physical and Environmental Protection
System and Communication Protection
System and Information Integrity
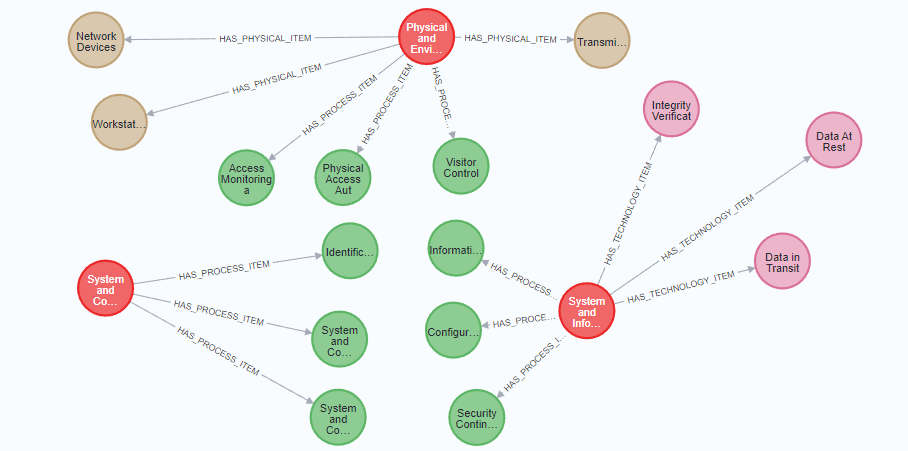
It's worth noting that this division is somewhat subjective, and there may be other ways to categorize the control families based on different criteria or perspectives. However, I hope that this provides a useful starting point for thinking about how the different control families relate to each other.Having done this classification, I wanted to drill down only within the Technology controls (for keeping this relatively bound) to represent them in a graph. With no more than 5 to 7 iterations, I was able to get in sync with the GPT engine to drive a distinction between physical, technology, and process items, leading to the following code/graph.
MATCH (n:ControlFamily {name:'Physical and Environmental Protection'})
SET n.description = 'Physical and environmental protections for devices and equipment that have the capability to store, process, or transmit sensitive data.'
MATCH (m:ControlFamily {name:'System and Communications Protection'})
SET m.description = 'Protection measures for information systems, networks, and communications channels.'
MATCH (o:ControlFamily {name:'System and Information Integrity'})
SET o.description = 'Measures to ensure the integrity, availability, and confidentiality of information on systems and networks.'
MATCH (n:ControlFamily {name:'Physical and Environmental Protection'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Visitor Control'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Physical Access Authorizations'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Access Monitoring and Accountability'})
MATCH (n:ControlFamily {name:'Physical and Environmental Protection'})
MERGE (n)-[:HAS_PHYSICAL_ITEM]->(:PhysicalItem {name:'Transmission Media'})
MERGE (n)-[:HAS_PHYSICAL_ITEM]->(:PhysicalItem {name:'Workstations and Servers'})
MERGE (n)-[:HAS_PHYSICAL_ITEM]->(:PhysicalItem {name:'Network Devices'})
MATCH (n:ControlFamily {name:'System and Communications Protection'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'System and Communications Protection Policies and Procedures'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Identification and Authentication'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'System and Communications Protection Mechanisms'})
MATCH (n:ControlFamily {name:'System and Information Integrity'})
MERGE (n)-[:HAS_TECHNOLOGY_ITEM]->(:TechnologyItem {name:'Data At Rest'})
MERGE (n)-[:HAS_TECHNOLOGY_ITEM]->(:TechnologyItem {name:'Data in Transit'})
MERGE (n)-[:HAS_TECHNOLOGY_ITEM]->(:TechnologyItem {name:'Integrity Verification'})
MATCH (n:ControlFamily {name:'System and Information Integrity'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Security Continuous Monitoring'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Configuration Management'})
MERGE (n)-[:HAS_PROCESS_ITEM]->(:ProcessItem {name:'Information Integrity Program'})
Basic as it is, gives you a perspective on how easy it is to get a story going for 'this' data.
Consider that the easier task. Now, if we move onto the slightly harder next level with OpenAI, here is an interesting example.
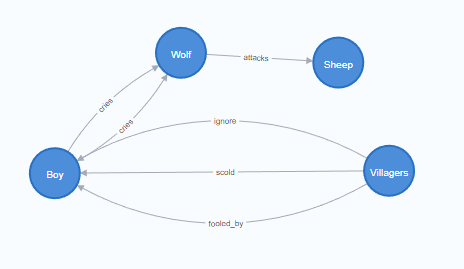
Use case 2, a nice little story called The boy who cried, Wolf! The story is about a boy who cries wolf and loses credibility with the villagers when he tries to fool them before an actual wolf attacks his sheep, only for his cries to go unheeded.
With no specific context, if you ask for the engine to generate a graph for the story, here is how it goes.

Let us assume we need something better. I wanted to narrate the actors separately and call out the actions as well separately, but more importantly, narrate the sequence in a manner that's easier to consume (for a typical audience). For all the sophistication and speed this offers, I had to go through some 15 iterations before the below code came through. Maybe this is why we need to learn "prompt engineering" and context setting better, but this was definitely a level above the previous example.
CREATE (:Character {name: 'Boy', gender: 'Male', age: 10})
CREATE (:Character {name: 'Villagers', count: 35})
CREATE (:Character {name: 'Sheep', species: 'Ovis aries'})
CREATE (:Character {name: 'Wolf', species: 'Canis lupus'})
MATCH (b:Character {name: 'Boy'}),
(v:Character {name: 'Villagers'}),
(s:Character {name: 'Sheep'}),
(w:Character {name: 'Wolf'})
CREATE (b)-[:cries {timestamp: 1}]->(w)
CREATE (v)-[:fooled_by {timestamp: 2}]->(b)
CREATE (v)-[:scold {timestamp: 3}]->(b)
CREATE (w)-[:attacks {timestamp: 4}]->(s)
CREATE (b)-[:cries {timestamp: 5}]->(w)
CREATE (v)-[:ignore {timestamp: 6}]->(b)
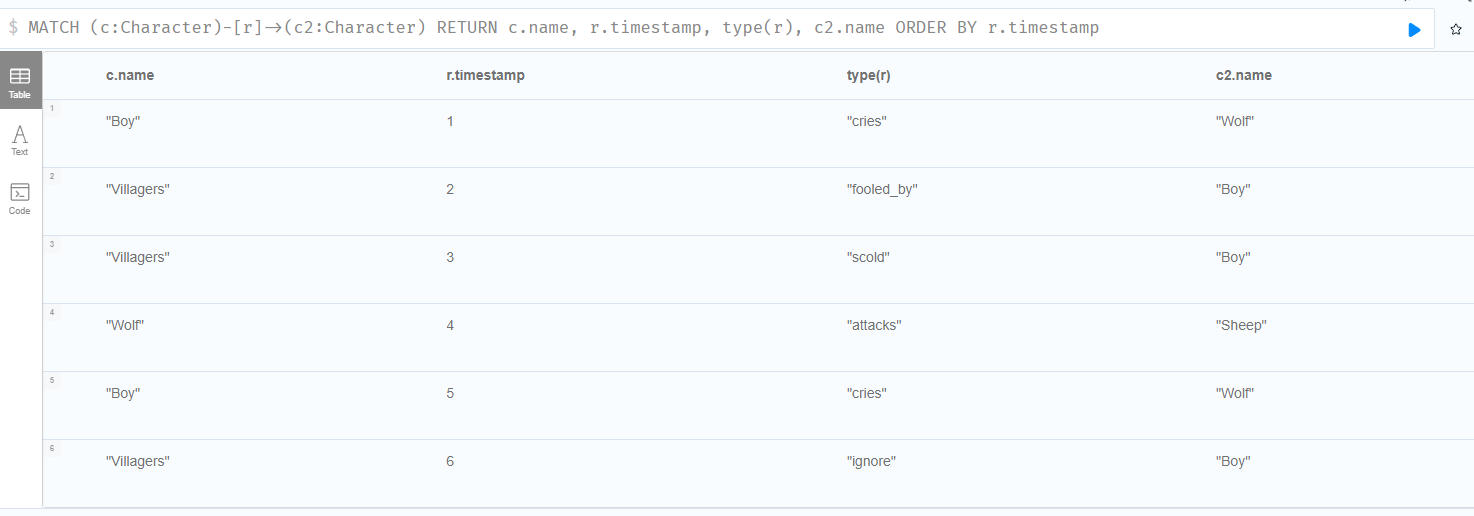
MATCH (c:Character)-[r]->(c2:Character)
RETURN c.name, r.timestamp, type(r), c2.name
ORDER BY r.timestamp
Gives you a graph that looks like this, and maybe Neo4j bloom can help show the sequence as well better. For now, I went with a simple table to explain the order. The 'concept' of wanting information as a sequence (which explains the timestamp above) took the bulk of iterations.
To Summarize
- Large language models continue to fascinate. The GPT engine is not just humbling for the speed and acceptable accuracy of code it produces but also for this uncanny ability to latch onto context. I haven't played around with GPT4 to compare, but I am told that's just exponentially better as well.
- When we move away from relatively plain text comprehension (Use case 1) to something that's more "human" by way of storytelling, the iterations do increase, but then I am just hoping that that distinction remains! Just my hope :-)
- Lastly, you should know what you want out of the model. This is like carrying a Transformers bot at the back of your car or being inside one.
Opinions expressed by DZone contributors are their own.
Comments