Automatic Snapshots Using Snapshot Manager
For AWS Kinesis Data Analytics (KDA), use the Flink Snapshot Manager to automatically snapshot applications, delete old snapshots, and more.
Join the DZone community and get the full member experience.
Join For FreeOverview
AWS has a Lambda function that can be leveraged to take automatic snapshots of the KDA (Kinesis Data Analytics) applications that are running in a specific region. Refer the Lambda function source code here. Users can modify the Lambda function to their needs.
Note: As of August 30, 2023, Amazon Kinesis Data Analytics (KDA) has been renamed to Amazon Managed Service for Apache Flink.
What Does It Do?
- Takes snapshots of all the running KDA applications.
- Get a list of the number of snapshots each KDA application has.
- Check if the number of snapshots is greater than the threshold number specified.
- Delete any old snapshots if they exceed the threshold number.
Resources Used
- Lambda Functions
- CloudWatch events (Amazon EventBridge)
- SNS topic
- AWS KDA (Kinesis Data Analytics)
- AWS DynamoDB table (optional)
IAM Roles/Policies Required
"Resources": "*"
CloudWatch Logs Policies
"logs:CreateLogStream"
"logs:CreateLogGroup"
"logs:PutLogEvents"
Kinesis Analytics Policies
"kinesisanalytics:ListApplicationSnapsots"
"kinesisanalytics:DescribeApplicationSnapshot"
"kinesisanalytics:DescribeApplication"
"kinesisanalytics:DeleteApplicationSnapshot"
"kinesisanalytics:ListApplications"
"kinesisanalytics:CreateApplicationSnapshot"
Amazon SNS Policies
"sns:Publish"
Architecture
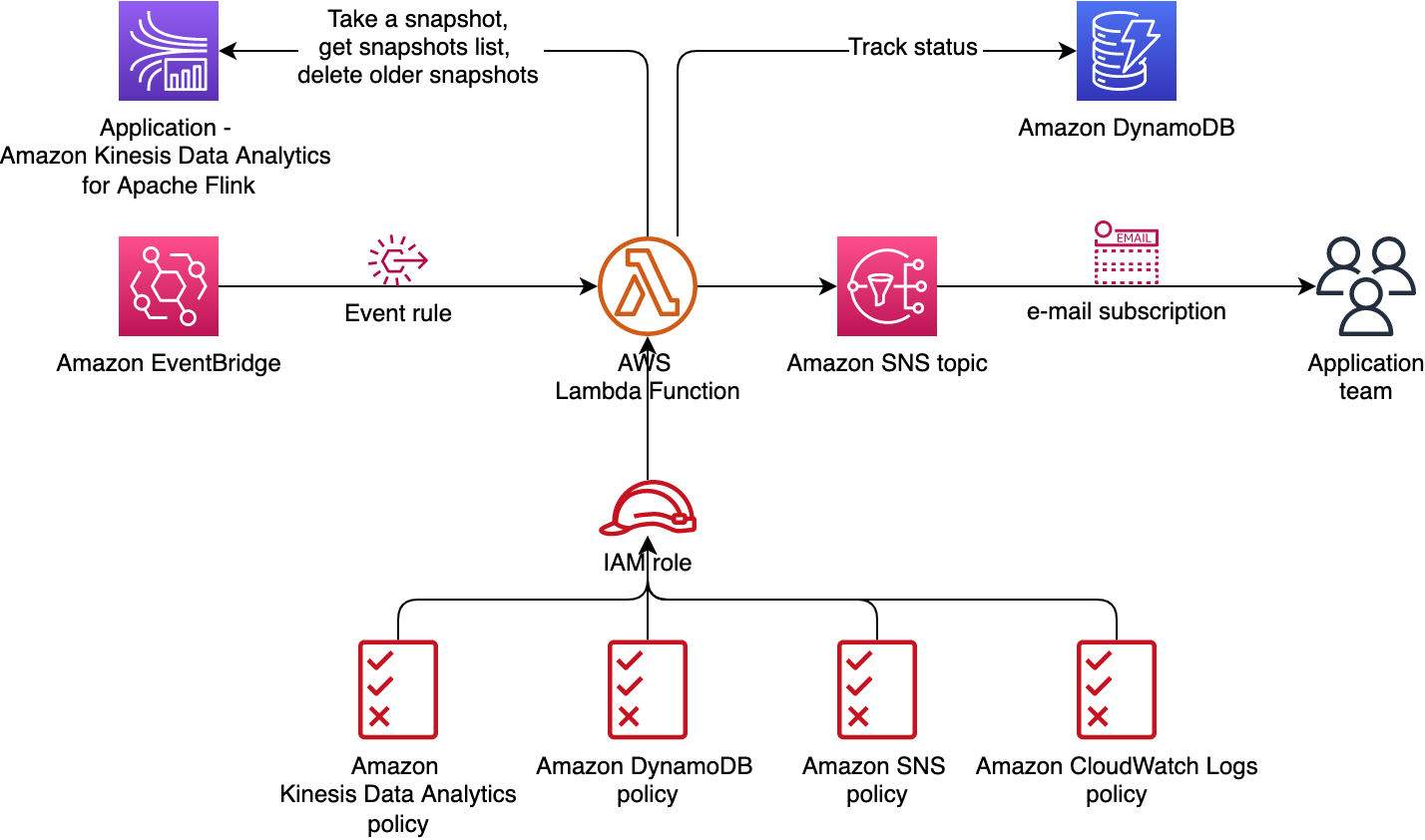
When a schedule is being created, each time a CloudWatch event is run, it triggers the Snapshot Manager lambda function which will perform the snapshotting and then send out the notification on to the SNS topic.
Note: DynamoDB might not be used in most cases (but it's shown in the diagram if it's required to store metadata about snapshots in some cases).
What Happens Inside the Lambda Function?
- When the Lambda function is invoked, it first reads all the environment variables.
- Then, a call is made to retrieve a list of all running KDA applications.
- Next, it iterates through the list to check if each KDA application is in a running state. If not, or if it's not currently healthy, it throws an error and sends a notification to the specified SNS topic.
- If the KDA application is running, a snapshot is taken for it.
- The snapshot creation process is initiated. If it times out, it throws an error and sends a notification to the SNS topic.
- Upon successful completion of the snapshot, the deletion of the older snapshots is initiated.
- It retrieves a list of all snapshots and checks whether the application's snapshot count exceeds the maximum number configured as an environment variable.
- If the number exceeds the maximum, the oldest snapshot is deleted.
Resource Creation
SNS Topic
- Create an SNS topic to send out emails/any other notifications on failed snapshots.
- Once that is done, we also need to create a subscription to that topic.
- Both success and failure snapshots are sent to the topic.
- That can be changed to only send notifications on failures rather than every successful one.
- Once the failures we need to send out notifications
- We might need an email to get the notifications
- Configure the message to also send out the failure messages
- Alternatively, you can also send a notification to Slack
Lambda
- Firstly, we need to create a Lambda function. Select Python as the language and x86_64 as the architecture.
- Once done, we need to paste the Snapshot Manager Python code into the editor. We'll also need to make a few config changes as mentioned below.
- Change the timeout to be around "X" minutes (configurable) to make sure that all the KDA application snapshots are completed.
- Add a few environment variables:
- aws_region: To get a list of all the applications running in that region
- number_of_older_snapshots_to_retain: To retain the number of old snapshots
- snapshot_creation_wait_time_seconds: Wait for this before you check whether the snapshot has been completed or not. We perform a check for 4 times and then fail if it doesn't get completed after 4 retries.
- agents: Number of parallel snapshots that can be taken at a single time.
- realm: Get a list of pipelines in which the realm name
- sns_topic_arn: The ARN of the SNS topic on which we send out the email notification in case of a failure.
Amazon EventBridge
- CloudWatch events have been renamed to Amazon EventBridge.
- We can create a rule that executes as specified.
- When creating a rule, we can specify a schedule for when the expression should run. This can be a cron job expression or a fixed rate.
- We need to determine how often this rule needs to be invoked, whether it's every "X" days, hours, or minutes.
- Once the schedule is defined, we need to select the Lambda function that was previously created.
Sample Settings
- Number of old snapshot retentions: 100 (to keep at least 2 days of snapshots)
- Frequency: 30 minutes
- Number of parallel runs to take snapshots (parallelism): 5
Failure Scenarios
Here are some failure scenarios and how snapshots help or not:
Scenario 1
- A KDA pipeline has restarted due to an error in the Flink.
- In this scenario, the KDA pipeline automatically restarts. However, it does not take periodic snapshots to recover from failures.
- Checkpointing, a feature in Flink that runs approximately every 30 seconds to 1 minute, comes into play here. The pipeline will recover from the latest checkpoint.
Scenario 2
- A KDA pipeline is stuck in a restart loop due to changes, such as bad configurations or source/sync changes.
- When attempting to update the KDA application, the update fails because the application tries to take a snapshot before the update is performed.
- Since the KDA pipeline is stuck in a restart loop, taking a snapshot fails. In such cases, the snapshot manager's periodic snapshots become essential.
- First, we need to stop the pipeline from running, perform the required changes/updates, and then restart the application from the latest snapshot.
- No data will be lost, but there might be duplicates because the pipeline will reprocess all messages from the last snapshot. A dedupe functionality can be added to de-duplicate messages.
Scenario 3
- In some cases, even a single snapshot cannot be taken because the application is stuck in a restart loop.
- In such situations, we adjust the configuration and restart the pipeline without any snapshots since none were taken.
- In this particular case, there will be a loss of data.
Opinions expressed by DZone contributors are their own.
Comments