Kafka: Navigating GDPR Compliance
The challenges posed by GDPR’s “Right to be Forgotten” in the context of Apache Kafka and three strategies for overcoming them.
Join the DZone community and get the full member experience.
Join For FreeNavigating the General Data Protection Regulation (GDPR) maze might be daunting. If you’re using Kafka for your data storage and processing, you might be wondering if you’re GDPR compliant, particularly with respect to the Right to Erasure or “Right to be Forgotten” (RTBF). In this post, we’ll delve into what this means for your Kafka deployment and explore potential solutions.
Understanding GDPR and Kafka’s Challenge
The GDPR is a regulation put in place to safeguard the privacy of individuals in the European Union (EU). It impacts anyone collecting or processing personal data within the EU, irrespective of their geographical location.
Following Brexit, the UK adopted its own version of GDPR, known as UK GDPR. The UK GDPR mirrors the EU’s regulation, and thus, essentially, the same rules apply to data collection and processing within the UK.
One of its key stipulations is the Right to Erasure. This means individuals can request the removal of their personal data (also known as Personally Identifiable Information or PII), and organizations must comply with that request within one month. Notably, to comply with the Right to Erasure, personal data only needs to be “put beyond use,” so this does not necessarily require the data to be deleted, as we will explore later.
With Kafka’s core principle of immutable logs, the Right to Erasure becomes a considerable challenge as Kafka messages cannot be deleted. Furthermore, the growing trend of using Kafka as a central data repository, often coupled with the need for backing up Kafka cluster messages to cold storage, further complicates the issue.
Let’s examine some potential solutions to ensure your Kafka operations align with GDPR requirements:
Option 1: Shortened Retention Period
A straightforward approach to comply with the Right to Erasure is setting the retention period for all topics to a maximum of 28 days. This guarantees that any PI data will have been removed automatically from Kafka within the one-month time limit for responding to a data subject’s erasure request.
The challenge of implementing the Right to Erasure then shifts away from the Kafka cluster and to the backup solution, if there is one.
The advantages of a shortened retention period include the following:
- Automatic GDPR compliance across the live Kafka cluster
- Easiest to implement
The disadvantages of a shortened retention period include the following:
- Compliance remains an issue for topic backups
- Unsuitable for topics needing longer or infinite retention periods
Option 2: Log Compaction
Log compaction is another method to comply with the Right to Erasure. It involves enabling log compaction across all topics and leveraging a Kafka feature called “tombstoning." This involves writing a “user-ID(key):null(value)” message to the topic, which, when the segment is compacted, deletes all previous messages with the same key.
In our case, if all messages in a topic containing PII data are keyed with a customerID, we can easily use tombstoning to remove all of a customer’s messages in that topic.
This method necessitates that topic messages are keyed by a value that is unique and identifiable to each user, for example, a customer ID. Additionally, log compaction must be enabled across all topics that contain PII data.
Advantages of log compaction include:
- Its simplicity
- Compatible with topics with longer or infinite retention periods
- Log compaction can be configured on a per-topic basis, so only PII topics need to have this enabled
Disadvantages of log compaction include:
- The need for messages to be keyed by a customer ID
- Deletes the entire message, not just the PII contents
- Log compaction must be enabled on all topics handling PII
- Topic backups will still contain old PII data
- The tiered-storage feature in both Confluent Cloud and Amazon MSK does not support compacted topics
Option 3: Crypto-Shredding
Crypto-shredding is a method of ensuring that personal data is “put beyond use” without actually deleting it. This is achieved by encrypting all messages containing PII with a key that is at least partly determined by the user’s ID. The keys used to encrypt each message are then stored in a key-value database that maps a user’s ID to the key used to encrypt their messages.
If a user requests PII erasure, this can be done simply by deleting the key associated with the user’s ID. This renders their PII undecryptable and, thus, “put beyond use.”
An example of such an architecture using Single Message Transforms with Kafka Connect to encrypt and decrypt the PII fields upon entry and exit from the Kafka cluster. Keys can then be stored in a Key Management solution, such as AWS KMS. Baffle is one solution that enables this kind of architecture.
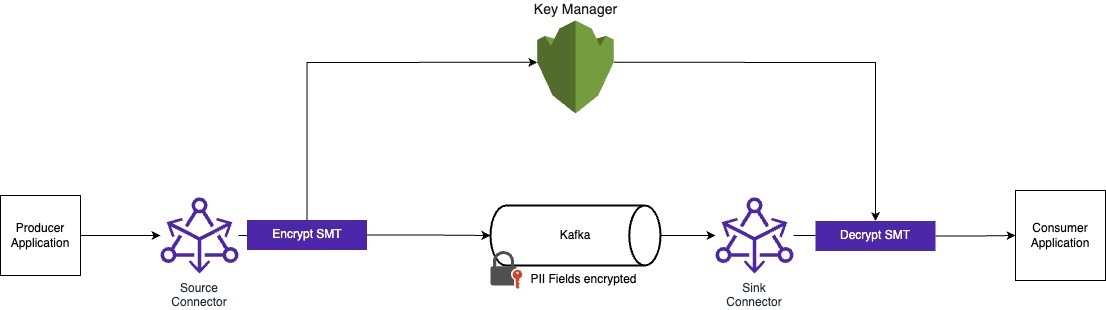
Advantages of crypto-shredding include:
- The ability to make backups of the topic while maintaining compliance with the Right to Erasure
- Infinite topic retention periods
- The ability to use tiered storage as a fully-managed backup option
- Can encrypt individual fields within a message, so non-PII fields can be preserved after shredding
- This is becoming an increasingly common way of approaching this problem in the industry. Notably, Spotify follows this approach for all of its PI user data with its “Padlock” global key database.
Disadvantages of crypto-shredding include:
- Technically challenging to implement in a complex production environment
- Encrypting non-string fields can cause schema issues with formats such as Avro
- Potential latency issues for certain applications due to the need to encrypt before producing messages to a topic and decrypt when consuming
- The need to store user keys safely and make them highly available, as it creates a single point of failure for all PI data processing applications
- Need to be able to guarantee that a key has been deleted and there are no copies to be compliant
- The risk of data breaches exposing the keys
Conclusion
Navigating GDPR compliance in Kafka is challenging but essential to protect the privacy of individuals in the UK and EU and avoid potential penalties for noncompliance. The Right to Erasure poses a particular challenge due to Kafka’s immutable logs, but with careful planning and the right strategies, it is possible to meet this requirement.
Before choosing a solution, ensure you understand your Kafka deployment well, along with the requirements of your producer and consumer applications. If it is possible, Option 1, a shortened retention period, is usually the best way to go. If you need to hold on to information for longer than 28 days, you should consider storing this data outside of Kafka, for example, in a mutable database, where the Right To Be Forgotten can be more easily enforced.
If this is not possible, you should be aware that the other two options have significant drawbacks and should be implemented with great care to ensure that they actually provide GDPR compliance.
Remember, the solutions discussed in this post are not exhaustive. You may need to combine several strategies or devise innovative solutions to fully comply with GDPR regulations. Good luck on your GDPR compliance journey! If you still find it a bit overwhelming, don’t hesitate to reach out to OpenCredo for assistance!
Published at DZone with permission of Greg Nuttall. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments