Introduction to Kubernetes Event-Driven Auto-Scaling (KEDA)
Explore KEDA (Kubernetes Event-Driven Autoscaling), an effective autoscaling solution for Kubernetes workloads, and learn KEDA architecture and its benefits.
Join the DZone community and get the full member experience.
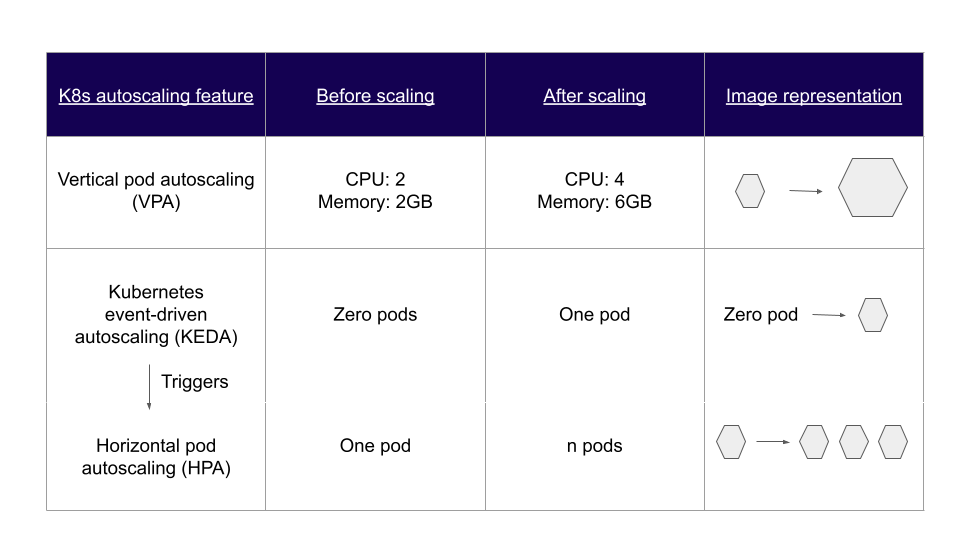
Join For FreeManual scaling is slowly becoming a thing of the past. Currently, autoscaling is the norm, and organizations that deploy into Kubernetes clusters get built-in autoscaling features like HPA (Horizontal Pod Autoscaling) and VPA (Vertical Pod Autoscaling). But these solutions have limitations. For example, it's difficult for HPA to scale back the number of pods to zero or (de)scale pods based on metrics other than memory or CPU usage. As a result, KEDA (Kubernetes Event-Driven Autoscaling) was introduced to address some of these challenges in autoscaling K8s workloads.
In this blog, we will delve into KEDA and discuss the following points:
What is KEDA?
KEDA architecture and components
KEDA installation and demo
Integrate KEDA in CI/CD pipelines
What Is KEDA?
KEDA is a lightweight, open-source Kubernetes event-driven autoscaler that DevOps, SRE, and Ops teams use to scale pods horizontally based on external events or triggers. KEDA helps to extend the capability of native Kubernetes autoscaling solutions, which rely on standard resource metrics such as CPU or memory. You can deploy KEDA into a Kubernetes cluster and manage the scaling of pods using custom resource definitions (CRDs).
What Problems Does KEDA Solve?
KEDA helps SREs and DevOps teams with a few significant issues they have:
Freeing Up Resources and Reducing Cloud Cost
KEDA scales down the number of pods to zero in case there are no events to process. This is harder to do using the standard HPA, and it helps ensure effective resource utilization and cost optimization, ultimately bringing down the cloud bills.
Interoperability With DevOps Toolchain
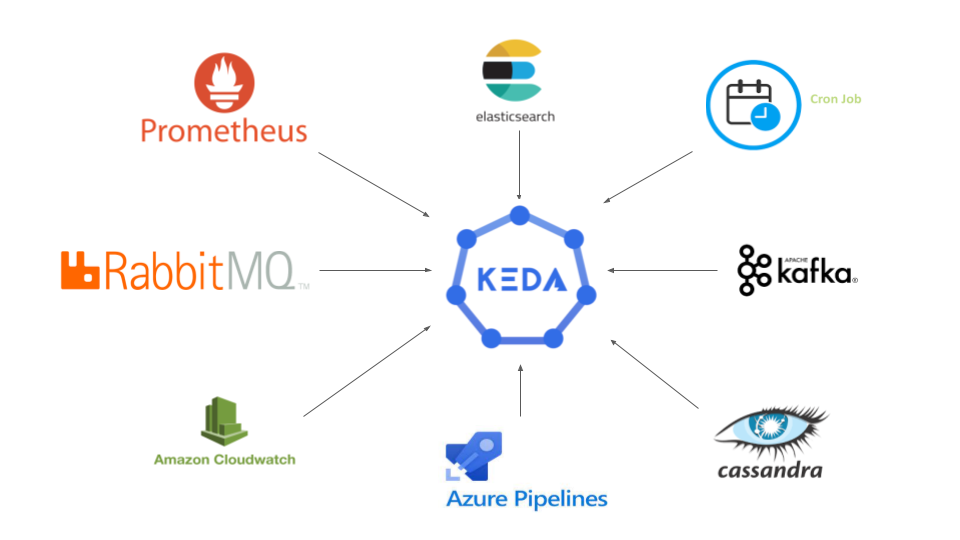
As of now, KEDA supports 59 built-in scalers and four external scalers. External scalers include KEDA HTTP, KEDA Scaler for Oracle DB, etc. Using external events as triggers aids efficient autoscaling, especially for message-driven microservices like payment gateways or order systems. Furthermore, since KEDA can be extended by developing integrations with any data source, it can easily fit into any DevOps toolchain.
KEDA Architecture and Components
As mentioned in the beginning, KEDA and HPA work together to achieve autoscaling. Because of that, KEDA needs only a few components to get started.
KEDA Components
Refer to Fig. A and let us explore some of the components of KEDA.
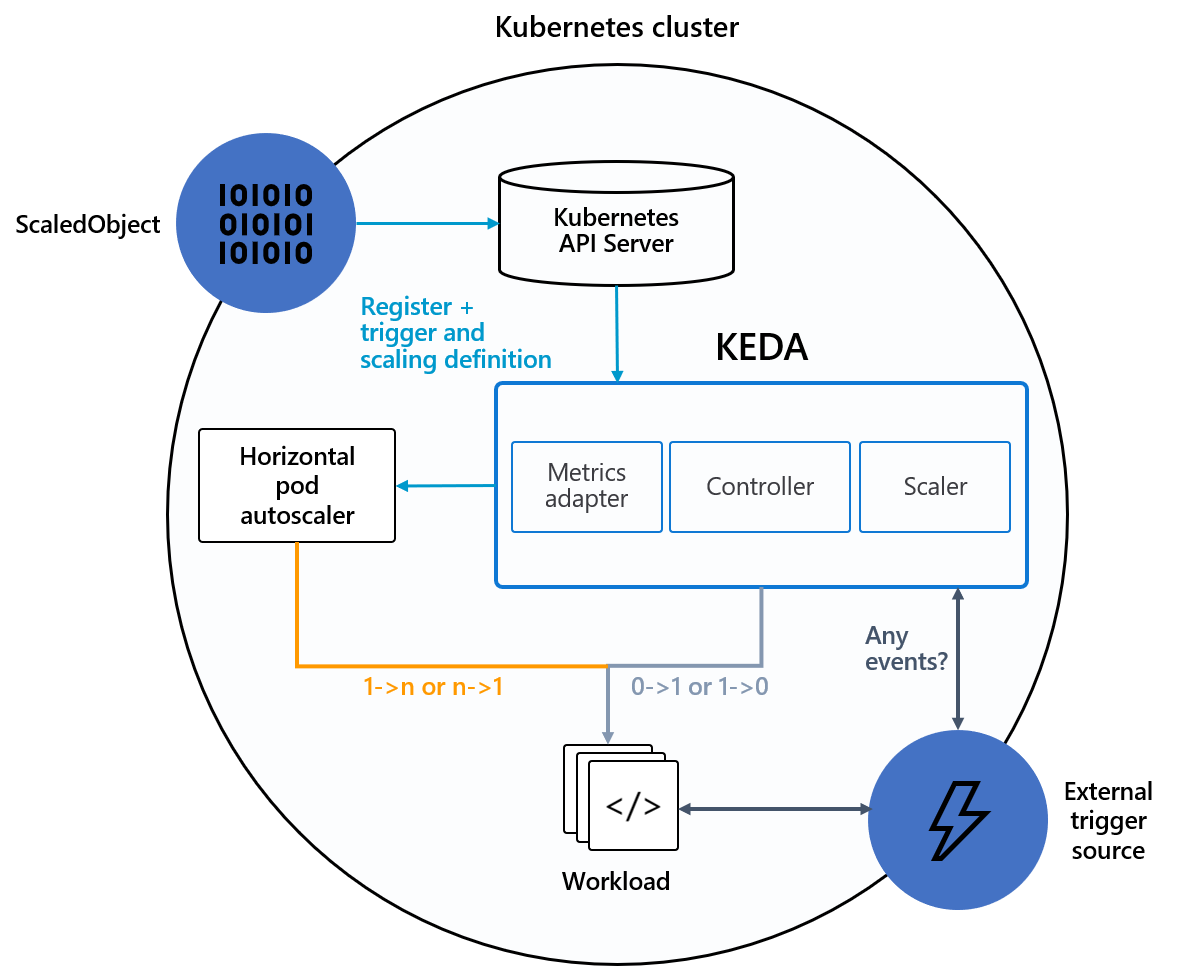
Event Sources
These are the external event/trigger sources by which KEDA changes the number of pods. Prometheus, RabbitMQ, and Apache Pulsar are some examples of event sources.
Scalers
Event sources are monitored using scalers, which fetch metrics and trigger the scaling of Deployments or Jobs based on the events.
Metrics Adapter
The metrics adapter takes metrics from scalers and translates or adapts them into a form that HPA/controller component can understand.
Controller
The controller/operator acts upon the metrics provided by the adapter and brings about the desired deployment state specified in the ScaledObject (refer below).
KEDA CRDs
KEDA offers four custom resources to carry out the auto-scaling functions- ScaledObject, ScaledJob, TriggerAuthentication, and ClusterTriggerAuthentication.
ScaledObject and ScaledJob
ScaledObject represents the mapping between event sources and objects and specifies the scaling rules for a Deployment, StatefulSet, Jobs, or any Custom Resource in a K8s cluster. Similarly, ScaledJob is used to specify scaling rules for Kubernetes Jobs.
Below is an example of a ScaledObject which configures KEDA autoscaling based on Prometheus metrics. Here, the deployment object 'keda-test-demo3' is scaled based on the trigger threshold (50) from Prometheus metrics. KEDA will scale the number of replicas between a minimum of 1 and a maximum of 10 and scale down to 0 replicas if the metric value drops below the threshold.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: demo3
spec:
scaleTargetRef:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
name: keda-test-demo3
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="300-0", container="envoy", namespace="demo3", response_code="200" }
threshold: "50"
idleReplicaCount: 0
minReplicaCount: 1
maxReplicaCount: 10TriggerAuthentication and ClusterTriggerAuthentication
They manage authentication or secrets to monitor event sources.
Now let us see how all these KEDA components work together and scale K8s workloads.
How Do KEDA Components Work?
It is easy to deploy KEDA on any Kubernetes cluster, as it doesn't need overwriting or duplication of existing functionalities. Once deployed and the components are ready, the event-based scaling starts with the external event source (refer to Fig. A). The scaler will continuously monitor for events based on the source set in ScaledObject and pass the metrics to the metrics adapter in case of any trigger events. The metrics adapter then adapts the metrics and provides them to the controller component, which then scales up or down the deployment based on the scaling rules set in ScaledObject.
Note that KEDA activates or deactivates a deployment by scaling the number of replicas to zero or one. It then triggers HPA to scale the number of workloads from one to n based on the cluster resources.
KEDA Deployment and Demo
KEDA can be deployed in a Kubernetes cluster through Helm charts, operator hub, or YAML declarations. For example, the following method uses Helm to deploy KEDA.
#Adding the Helm repo
helm repo add kedacore https://kedacore.github.io/charts
#Update the Helm repo
helm repo update
#Install Keda helm chart
kubectl create namespace keda
helm install keda kedacore/keda --namespace kedaTo check if KEDA Operator and Metrics API server are up or not after the deployment, you can use the following command:
kubectl get pod -n kedaNow, watch the below video to see a hands-on demo of autoscaling using KEDA. The demo uses a small application called TechTalks and uses RabbitMQ as the message broker.
Integrate KEDA in CI/CD Pipelines
KEDA makes autoscaling of K8s workloads very easy and efficient. In addition, the vendor-agnostic approach of KEDA ensures flexibility regarding event sources. As a result, it can help DevOps and SRE teams optimize the cost and resource utilization of their Kubernetes cluster by scaling up or down based on event sources and metrics of their choice.
Integrating KEDA in CI/CD pipelines enables DevOps teams to quickly respond to trigger events in their application's resource requirements, further streamlining the continuous delivery process. And KEDA supports events generated by different workloads such as StatefulSet, Job, Custom Resource, and Job. All these help reduce downtime and improve the applications' efficiency and user experience.
Published at DZone with permission of Jyoti Sahoo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments