Introduction to Apache Bigtop, for Packaging and Testing Hadoop
By
 ·
·
Interview
·
·
Interview
Likes
(0)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
10.5K Views
Join the DZone community and get the full member experience.
Join For Free
Ah!! The name is everywhere, carried with the wind. Apache Hadoop!!
The BIG DATA crunching platform!
We all know how alien it can be at start too! Phew!! :o
Its my personal experience, nearly 11 months before, I was trying to install HBase, I faced few issues! The problem was version compatibility. Ex: "HBase some x.version" with "Hadoop some y.version".
This is a real issue because you will never know which package of what version blends well with the other, unless, someone has tested it. This testing again depends on the environment where they have set up and could be another issue.
There was a pressing demand for the management of distributions and then comes an open source project which attempts to create a fully integrated and tested Big Data management distribution, "Apache Bigtop".
Goals of Apache Bigtop:
-Packaging
-Deployment
-Integration Testing
of all the sub-projects of Hadoop. This project aims at system as a whole, than the individual project.
I love the way Doug Cutting quoted in the Keynote, back then, wherein he expressed the similarity between Hadoop and Linux kernel,and the corresponding similarity between the big stack of Hadoop ( Hive, Hbase, Pig, Avro, etc.) and the fully operational operating systems with its distributions (RedHat, Ubuntu, Fedora, Debian etc.). This is an awesome analogy! :)
Life is made easy with Bigtop:
Bigtop Hadoop distribution artifacts won't make you feel that you live in an alien world! After installing, you will get a chance to blend a Hadoop cluster in any mode, with the sub-projects of it. Its all for you to garnish next! :)
Setup Of Bigtop and Installing Hadoop:
It's time to welcome all your packages home. [I also mean /home/..] ;)
I've tested on Ubuntu 11.04 and here goes a quick and easy installation process.
Step 1: Installing the GNU Privacy Guard key, a key management system to access all public key directories.
wget -O- http://www.apache.org/dist/incubator/bigtop/bigtop-0.3.0-incubating/repos/GPG-KEY-bigtop | sudo apt-key add -
The BIG DATA crunching platform!
We all know how alien it can be at start too! Phew!! :o
Its my personal experience, nearly 11 months before, I was trying to install HBase, I faced few issues! The problem was version compatibility. Ex: "HBase some x.version" with "Hadoop some y.version".
This is a real issue because you will never know which package of what version blends well with the other, unless, someone has tested it. This testing again depends on the environment where they have set up and could be another issue.
There was a pressing demand for the management of distributions and then comes an open source project which attempts to create a fully integrated and tested Big Data management distribution, "Apache Bigtop".
Goals of Apache Bigtop:
-Packaging
-Deployment
-Integration Testing
of all the sub-projects of Hadoop. This project aims at system as a whole, than the individual project.
I love the way Doug Cutting quoted in the Keynote, back then, wherein he expressed the similarity between Hadoop and Linux kernel,and the corresponding similarity between the big stack of Hadoop ( Hive, Hbase, Pig, Avro, etc.) and the fully operational operating systems with its distributions (RedHat, Ubuntu, Fedora, Debian etc.). This is an awesome analogy! :)
Life is made easy with Bigtop:
Bigtop Hadoop distribution artifacts won't make you feel that you live in an alien world! After installing, you will get a chance to blend a Hadoop cluster in any mode, with the sub-projects of it. Its all for you to garnish next! :)
Setup Of Bigtop and Installing Hadoop:
It's time to welcome all your packages home. [I also mean /home/..] ;)
I've tested on Ubuntu 11.04 and here goes a quick and easy installation process.
Step 1: Installing the GNU Privacy Guard key, a key management system to access all public key directories.
wget -O- http://www.apache.org/dist/incubator/bigtop/bigtop-0.3.0-incubating/repos/GPG-KEY-bigtop | sudo apt-key add -
Step 2: Get the repo file from the link http://www.apache.org/dist/incubator/bigtop/bigtop-0.3.0-incubating/repos/ubuntu/bigtop.list
- sudo wget -O /etc/apt/sources.list.d/bigtop.listhttp://www.apache.org/dist/incubator/bigtop/bigtop-0.3.0-incubating/repos/ubuntu/bigtop.list
- sudo gedit /etc/apt/sources.list.d/bigtop.list
uncomment the mirror link near by. The first link worked for me.
deb http://apache.01link.hk/incubator/bigtop/stable/repos/ubuntu/ bigtop contrib
Step 3: Updating the apt cache
sudo apt-get update
sudo apt-get update
Step 4: Checking in the artifacts
sudo apt-cache search hadoop
Image:
sudo apt-cache search hadoop
Image:
 |
| Search in the apt cache |
Step 5: Set your JAVA_HOME
export JAVA_HOME=path_to_your_Java
export $JAVA_HOME in ~/.bashrc
export JAVA_HOME=path_to_your_Java
export $JAVA_HOME in ~/.bashrc
Step 6: Installing the complete Hadoop stack
sudo apt-get install hadoop\*
Image: (above)
sudo apt-get install hadoop\*
Image: (above)
Running Hadoop:
Step 1: Formatting the namendoe
sudo -u hdfs hadoop namenode -format
Image :
Step 1: Formatting the namendoe
sudo -u hdfs hadoop namenode -format
Image :
 |
| Formatting the namenode |
Step 2: Starting the Namenode, Datanode, Jobtracker, Tasktracker of Hadoop
for i in hadoop-namenode hadoop-datanode hadoop-jobtracker hadoop-tasktracker ; do sudo service $i start ; done
Now, the cluster is up and running.
Image :
 |
| Start all the services |
Step 3: Creating a new directory in hdfs
sudo -u hdfs hadoop fs -mkdir /user/bigtop
bigtop is the directory name in the user $USER
sudo -u hdfs hadoop fs -chown $USER /user/bigtop
Image :
sudo -u hdfs hadoop fs -mkdir /user/bigtop
bigtop is the directory name in the user $USER
sudo -u hdfs hadoop fs -chown $USER /user/bigtop
Image :
 |
| Create a directory in HDFS |
Step 4: List the directories in file system
hadoop fs -lsr /
Image :
hadoop fs -lsr /
Image :
 |
| HDFS directories |
Step 5: Running a sample pi example
hadoop jar /usr/lib/hadoop/hadoop-examples.jar pi 10 1000
Image :
hadoop jar /usr/lib/hadoop/hadoop-examples.jar pi 10 1000
Image :
 |
| Running a sample program |
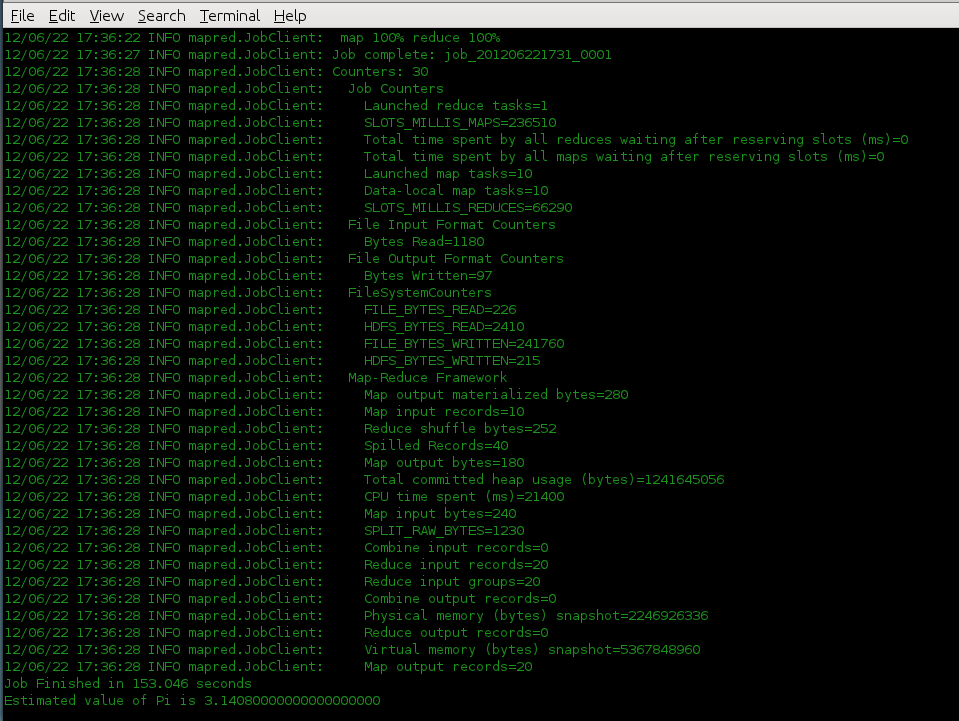 |
| Job Completed! |
Enjoy with your cluster! :)
We shall see what more blending could be done with Hadoop (with Hive, Hbase, etc.) in the next post!
Until then,
Happy Learning!! :):)
hadoop
Published at DZone with permission of Swathi Venkatachala, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments