Install and Configuration of Apache Hive-3.1.2 on Multi-Node
The Apache Hive is a data warehouse system built on top of the Apache Hadoop. Hive can be utilized for easy data summarization, and more!
Join the DZone community and get the full member experience.
Join For FreeThe Apache Hive is a data warehouse system built on top of the Apache Hadoop. Hive can be utilized for easy data summarization, ad-hoc queries, analysis of large datasets stores in various databases or file systems integrated with Hadoop. Ideally, we use Hive to apply structure (tables) on persisted a large amount of unstructured data in HDFS and subsequently query those data for analysis.

The objective of this article is to provide step by step procedure in sequence to install and configure the latest version of Apache Hive (3.1.2) on top of the existing multi-node Hadoop cluster. In a future post, I will detail how we can use Kibana for data visualization by integrating Elastic Search with Hive. Apache Hadoop — 3.2.0 was deployed and running successfully in the cluster. Here is the list of environment and required components.
- Existing up and running Hadoop cluster where Hadoop-3.2.0 deployed and configured with 4 DataNodes. Please go through the link if you wish to create a multi-node cluster to deploy Hadoop-3.2.0.
- Apache Hive-3.1.2. Tarball. It can be downloaded from the Apache mirror.
- MySQL. Installed and used Server version: 5.5.62
Step 1: Untar Apache-Hive-3.1.2-bin.tar.gz and Set up Hive Environment
1. Select a healthy DataNode with high hardware resource configuration in the cluster if we wish to install Hive and MySQL together. Here, the used DataNode has 16GB RAM and 1 TB HD for both Hive and MySQL.
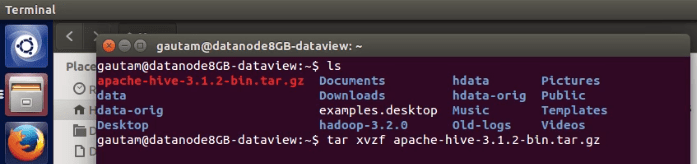
2. Extract the previously downloaded apache-hive-3.1.2-bin.tar.gz from the terminal and rename it as a hive.
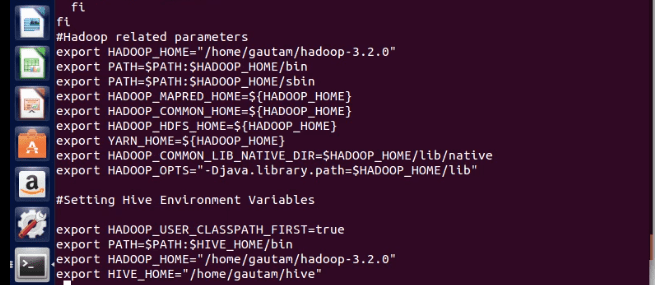
3. Update the ~/.bashrc file to accommodate the hive environment variables.
4. Please re-login and try below to check the environment variable.
echo $HIVE_HOME
echo $HIVE_CONF_DIR
5. Copy hive-env.sh.template to hive-env.sh and update with all read-write access


6. Update hive-env.sh available inside conf dir with the HADOOP_HOME and HIVE_CONF_DIR

Step 2: MySQL Database Installation for Hive Metastore Persistence and MySQL Java Connector
As said above, both Hive and MySQL database has installed in the same DataNode in the cluster. Here are the steps to install the MySQL database, create a schema named as metastore and subsequently update the schema by executing hive-schema-2.3.0.mysql.sql. This SQL script has all the table creation, update, etc., commands specifically provided by Apache Hive for MySQL database.
1. Download MySQL through the terminal.

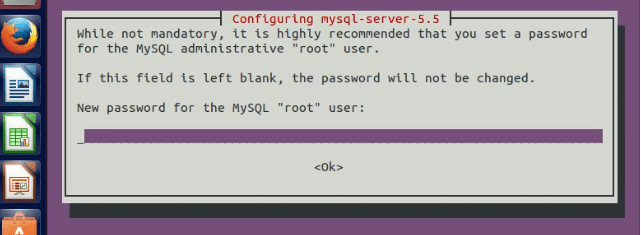
2. During installation, it will ask to set the database user “root” and its password. Set it and note it down.
3. Download and copy MySQL java connector (MySQL-connector-java-5.1.28.jar) to the lib folder of Hive.
By default, mysql-connector-java-5.1.28.jar will be download under /usr/share/java folder.

4. Start MySQL service. Ideally, MySQL service starts automatically after successful installation.
sudo service mysql startsudo service mysql status
5. Create a metastore database for Hive here by executing the MySQL command prompt's following commands.
mysql -u root -p<password>
mysql> CREATE DATABASE metastore;
mysql> USE metastore;
mysql> SOURCE /home/<<ubuntu>>/hive/scripts/metastore/upgrade/mysql/
hive-schema-3.1.0.mysql.sql
mysql> GRANT all on *.* to ‘root’@localhost;
mysql> flush privileges;
You can create a separate user in MySQL if you don’t wish to continue as a ‘root’ user.
6. Rename hive-default.xml.template to hive-site.xml available under conf directory.
Step 3: Update Hive-site.xml
In hive-site.xml, we can mention what execution engine to be used by hive when we fire the HQL query. Map Reduce has been depreciated now because of a performance issue. Based on the stored data volume in HDFS and the type of queries, either we can use tez or spark as a default execution engine of Hive to boost performance for query data. Here are properties in hive-site.xml that need to be mentioned with name and value to accommodate current cluster settings.
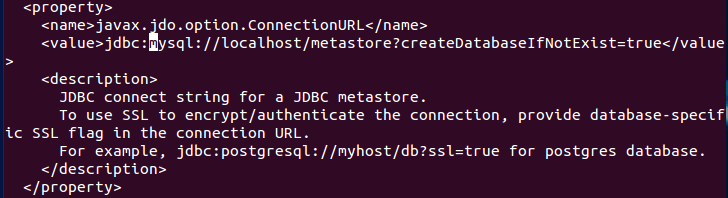
1. MySQL Database Connection URL
2. User name to connect with MySQL Database

3. Password to login with the created user in MySQL

4. Execution engine name, which Hive internally uses to execute queries. Can use Spark or Tez for better performance.
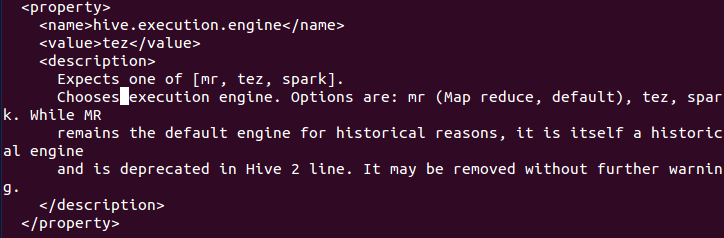
5. Scratch dir location

Step 4: Work on HDFS
Since Hive will run on top HDFS, we need to make sure Hadoop multi-node cluster is started, and all daemons are running without any issue. To verify, browse the Hadoop web admin page. Create a Hive directory on the HDFS using the following commands with subsequent permissions using terminal on the NameNode or MasterNode in the cluster.
hadoop-3.2.0/bin >./hdfs dfs -mkdir /user/
hadoop-3.2.0/bin >./hdfs dfs -mkdir /user/hive
hadoop-3.2.0/bin >./hdfs dfs -mkdir /user/hive/warehouse
hadoop-3.2.0/bin >./hdfs dfs -mkdir /tmp
hadoop-3.2.0/bin >./hdfs dfs -chmod -R a+rwx /user/hive/warehouse
hadoop-3.2.0/bin >./hdfs dfs -chmod g+w /tmp
Step 5: Access Hive CLI
Execute the hive command inside the bin directory of Hive using the terminal of the DataNode where Hive is installed and configured. We should see the “hive>” prompt for a successful installation.

There are multiple options available to connect with Hive to execute HQL queries, data loading, etc. Hive CLI can be used by default, but Hive should be installed on the same machine or the cluster's DataNode. It connects directly to the Hive Driver. Hive CLI won’t be used in a real-time/ production environment. since it’s depreciated from Hive 2.0 onwards. HiveServer2 (HS2) is a service that enables clients to execute queries against the Hive. HS2 supports multi-client concurrency and authentication. We don’t need any separate configuration for HiveServer2. If we can access Hive CLI from the terminal without any issue, the HiveServer2 service can be started by executing the following command in a separate terminal.
/hive/bin$ ./hive –service hiveserver2
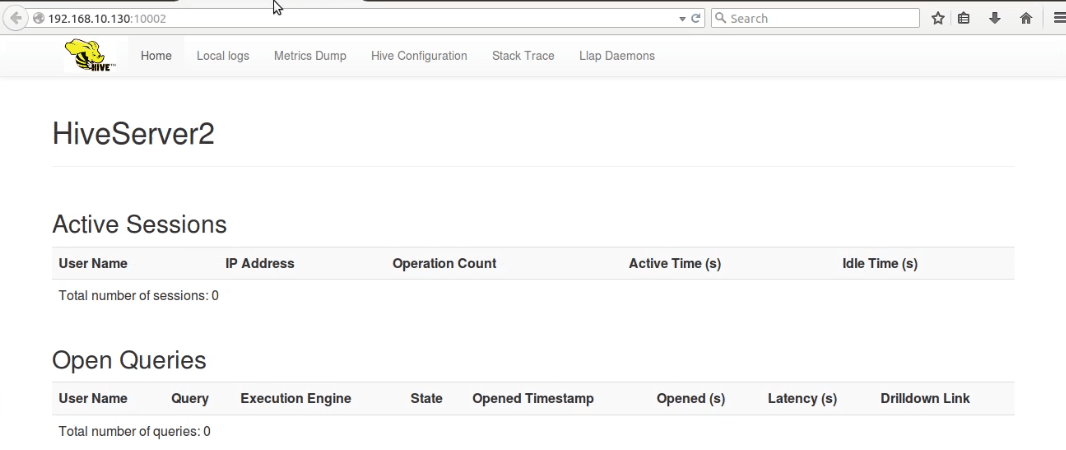
And access the web UI of HiverServer2 from the browser at default port 10002.
Beeline is another thin client CLI to execute queries via HiveServer2, which supports concurrent client connection and authentication. Beeline can be leveraged by multiple users from multiple nodes in the cluster to execute queries. We can use Hive Web Interface (HWI) as a client to communicate with existing Hive deployment besides CLI. Please go through the link if you want to use HWI.
References:
- https://hive.apache.org/index.html
- https://cwiki.apache.org/confluence/display/Hive/Setting+up+HiveServer2
- https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-Beeline–CommandLineShell
Published at DZone with permission of Gautam Goswami, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments