Inspecting Joins in PostgreSQL
Postgres uses different algorithms for JOINs depending on the query. We can inspect the query plan to find which type in the article below.
Join the DZone community and get the full member experience.
Join For Free
Introduction
Relational databases distribute their data across many tables by normalization or according to business entities. This makes maintaining a growing database schema easier. Real-world queries often span across multiple tables, and hence joining these tables is inevitable.
PostgreSQL uses many algorithms to join tables. In this article, we will see how joins work behind the scenes from a planner perspective and understand how to optimize them.
A Recap of Query Planning
Before we dive in, a little bit of preliminary reading is in order. This post is the third in a series of posts to help you understand different parts of a query plan. You may find the articles listed below to be helpful. This post covers the JOIN node and the different algorithms Postgres uses to perform joins.
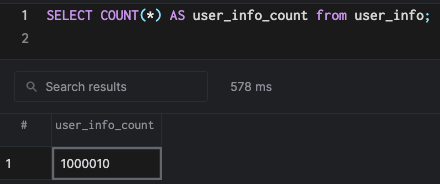
Data Setup
To understand how PostgreSQL prepares the plans for join queries, we need to set up data for experimentation.
Schema
Let's have two tables in our data that have the following structure:
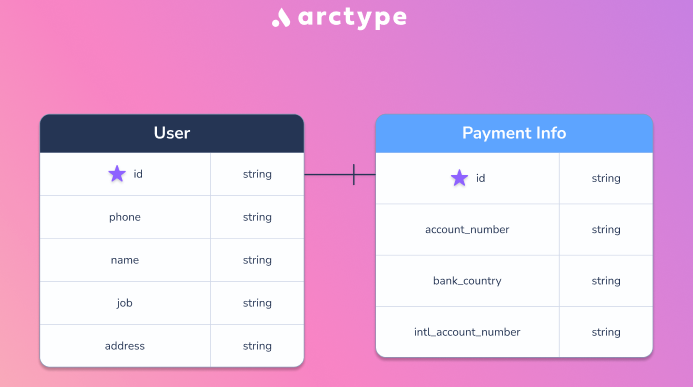
These tables are primarily for testing and self-explanatory in what they store. The id column connects them, and they have a one-to-one relationship. Queries for CREATE TABLE are given below:
CREATE TABLE IF NOT EXISTS user_info(
id text,
phone text,
name text,
job text,
address text
);CREATE TABLE IF NOT EXISTS payment_info(
id text,
account_number text,
intl_account_number text,
bank_country text
);Data Generation
We are going to use the faker library in Python to generate some fake user data. Below is the code used to generate the CSV files for data:
from faker import Faker
import uuid
faker = Faker()
# Change this range to whatever value you like
ROW_COUNT = 1000000
u_info = open('user_info.csv', 'w')
acc_info = open('account_info.csv', 'w')
for i in range(0, ROW_COUNT):
user_id = uuid.uuid4()
phone_number = faker.phone_number()
name = faker.name()
job = faker.job().replace(',', '')
address = faker.address().replace(',', '').replace('\n', '')
bank_country = faker.bank_country()
account_number = faker.bban()
intl_account_number = faker.iban()
user_info = f"'{user_id}','{phone_number}','{name}','{job}','{address}' \n"
account_info = f"'{user_id}','{account_number}','{bank_country}','{intl_account_number}' \n"
u_info.write(user_info)
acc_info.write(account_info)
u_info.close()
acc_info.close()Data Loading
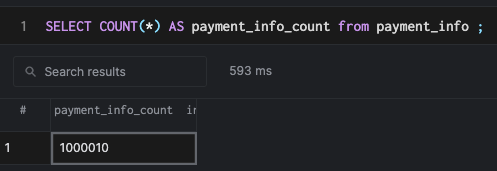
I created a million rows using the above script and loaded the data into PostgreSQL using the below commands:
COPY user_info(id, phone, name, job, address) FROM '/path/to/csv' DELIMITER ',';
COPY payment_info(id, account_number, bank_country, intl_account_number) FROM '/path/to/csv' DELIMITER ',';
sql-joins
JOIN Algorithms
Let's start querying the table where we have created and loaded the data. We will run several queries and use EXPLAIN to inspect their query plan. Similar to the article on scan nodes, we will set max workers to zero to make our plans look simpler.
SET max_parallel_workers_per_gather = 0;Finally, we will look at parallelization in joins in the dedicated section.
Hash Join
Let's run a simple query that combines the data from two tables.
SELECT
*
from
user_info
JOIN payment_info on user_info.id = payment_info.id
LIMIT
10Running an explain for this query would generate a hash join.
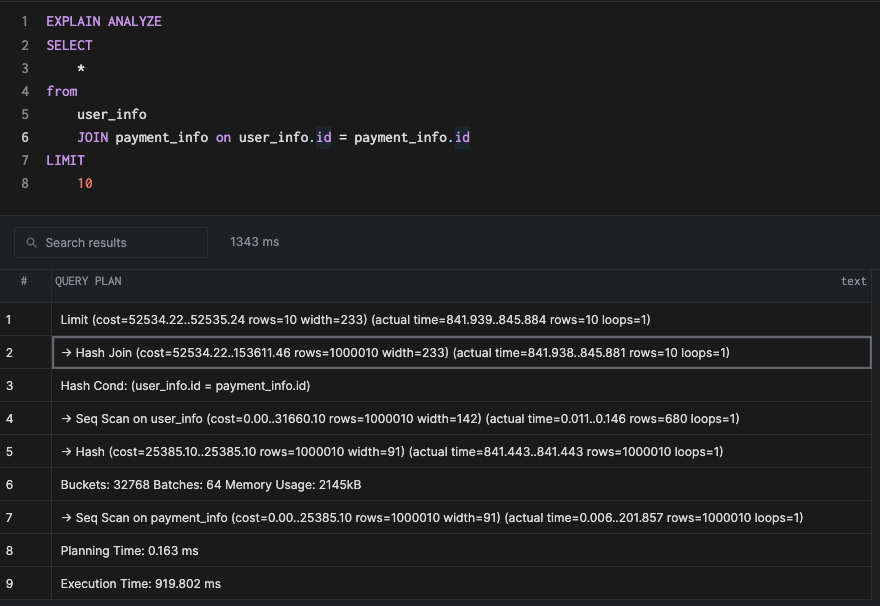
As the name suggests, a hash join builds a hash table based on the join key. In our example, we will create the hash table on the column id of the table user_info. We'll then use this table to scan the outer table, payment_info. Building the hash table is an added cost, but remember that the lookup (based on a good hash function) is effective as O(1) in terms of asymptotic complexity. A planner usually decides to do a hash join when the tables are more or less the same size and the hash table can fit in memory. An index cannot really help much in this case, since the building of the hash table involves a sequential scan (a scan of all the rows present in the table).
Nested Loop
Let's do a query where we want to select all data from both tables on the condition that the ID of the user_info table is lesser than the payment_info table. This query might not make sense in the real world, but you can draw parallels where you might join based on this condition. This is typically called a "cartesian product."
SELECT
*
from
user_info, payment_info
WHERE user_info.id < payment_info.id
LIMIT
10
OFFSET 200This would result in a nested loop join.
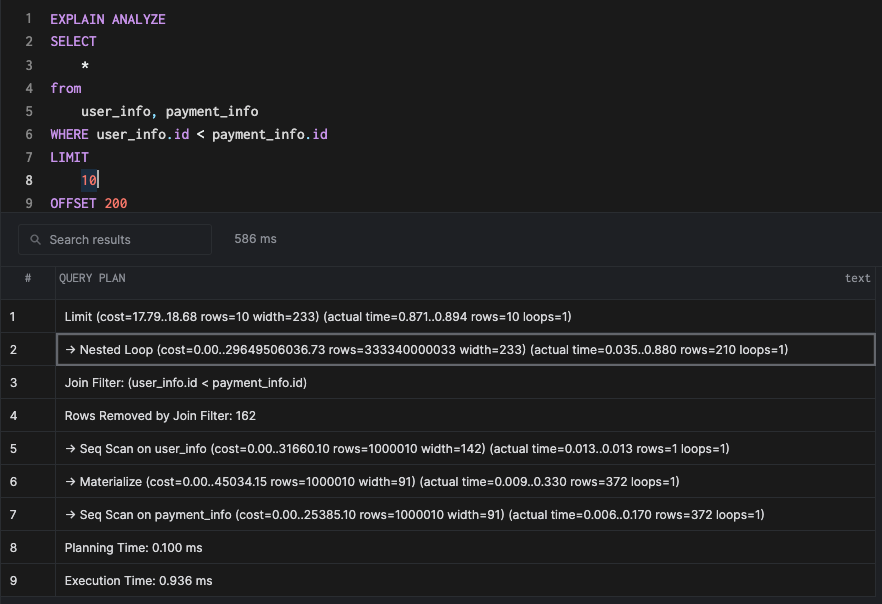
A nested loop is one of the simplest and hence the most naive of joins possible. It simply takes the join key from one table and runs through all of the join keys in the secondary table in a nested loop. In other words, a for loop inside a for loop:
for id as id_outer in user_info:
for id as id_inner in payment_info:
if id_outer == id_inner:
return true
else
return falseA nested loop is chosen by the planner under the following conditions,
- The join condition does not use the
=operator. - The outer table to be joined is smaller than the inner table.
These scenarios can typically come up when relations are many-to-one and the inner loop iterations are small.
Merge Join
Let's create indexes on both the tables for the join key.
CREATE index id_idx_usr on user_info using btree(id);
CREATE index id_idx_payment on payment_info using btree(id);If we run the same query we used in the hash join example, we have the following:
SELECT
*
from
user_info
JOIN payment_info on user_info.id = payment_info.id
LIMIT
10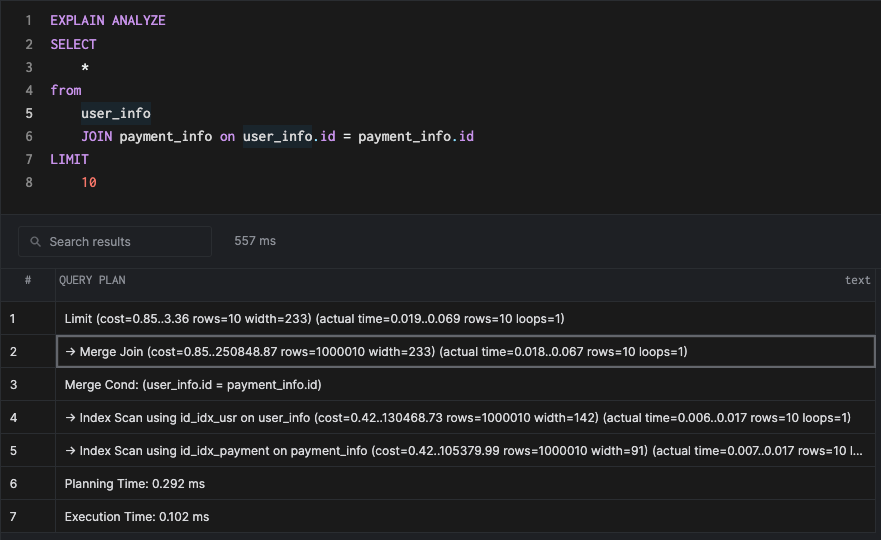
The plan might look familiar if you had read the scans blog linked earlier since it uses something called an index scan, but let's focus on the join algorithm. Since we have indexes on both the tables and the BTree index is sorted by default, the planner can fetch the rows in the sorted order from the index and do a merge as indicated in the Merge Cond node in the plan. It is significantly faster than any of the other join methods because of the index.
Parallel Joins
Let's disconnect the database session (to unset the max_parallel_workers_per_gather setting) and then drop all the indexes to run our original query. This will result in a parallel hash join which is a parallel version of the original hash join.
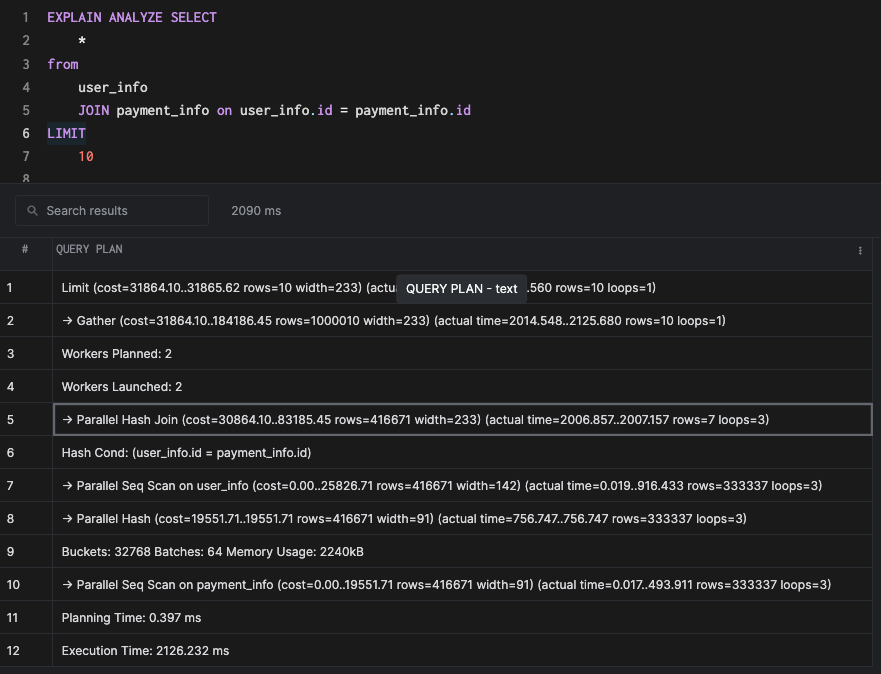
Similar to parallel scans, parallel joins make use of multiple cores to speed up execution. In the real world, the parallel joins/scans can be faster or even slower depending on a variety of factors. Parallel queries require a dedicated article in order for them to be explained in depth.
Understanding the Worker Memory Setting
The is the memory space used by PostgreSQL for joins, sorting, and other aggregate operations. By default, this uses 4 MB of memory, and each join operation can use up to 4 MB. We have to be careful in setting this since there could be multiple concurrent joins and each of them can use the set amount in a production database. If this setting is higher than what is required, it can cause performance problems and can also bring down the database itself. As always, performance testing is recommended before setting this value.
There are other settings like hash_mem_multiplier and logical_decoding_work_mem which can impact join performance, but in a typical production setting all join key/columns should be indexed and the work_mem setting should be set to a proper value to handle application workloads.
Conclusion
The data setup we did was extensive, so I highly encourage readers to take the time to understand the join nodes mentioned in this article. You should also feel free to experiment with different query patterns and see how the planner behaves for combinations of such queries. Joins are a critical piece of functionality for any relational database and it is important to understand how the planner works behind the scenes. To summarize:
- You should create
BTreeindexes for join keys to speed up to join operations. - If indexing is not possible, then try to optimize the
work_memsetting so that hash joins can happen completely in memory and not spill to the disk. - Nested loop joins should be the last resort and typically involve comparisons like
<,>on the join key. - The planner can combine indexes for other operations like
Scansand significantly speed up queries.BTreeindexes are very powerful and have a wide range of applications.
Hopefully, this article helped you understand more about joins. Stay tuned for more articles on PostgreSQL node types!
Published at DZone with permission of Everett Berry. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments