Improving Sentiment Score Accuracy With FinBERT and Embracing SOLID Principles
In this lab, I've improved market news sentiment analysis accuracy with a popular FinBERT ML algorithm using Python Jupyter Notebook.
Join the DZone community and get the full member experience.
Join For FreeIn a previous lab titled “Building News Sentiment and Stock Price Performance Analysis NLP Application With Python,” I briefly touched upon the concept of algorithmic trading using automated market news sentiment analysis and its correlation with stock price performance. Market movements, especially in the short term, are often influenced by investors’’ sentiment. One of the main components of sentiment analysis trading strategies is the algorithmic computation of a sentiment score from raw text and then incorporating the sentiment score into the trading strategy. The more accurate the sentiment score, the better the likelihood of algorithmic trading predicting potential stock price movements.
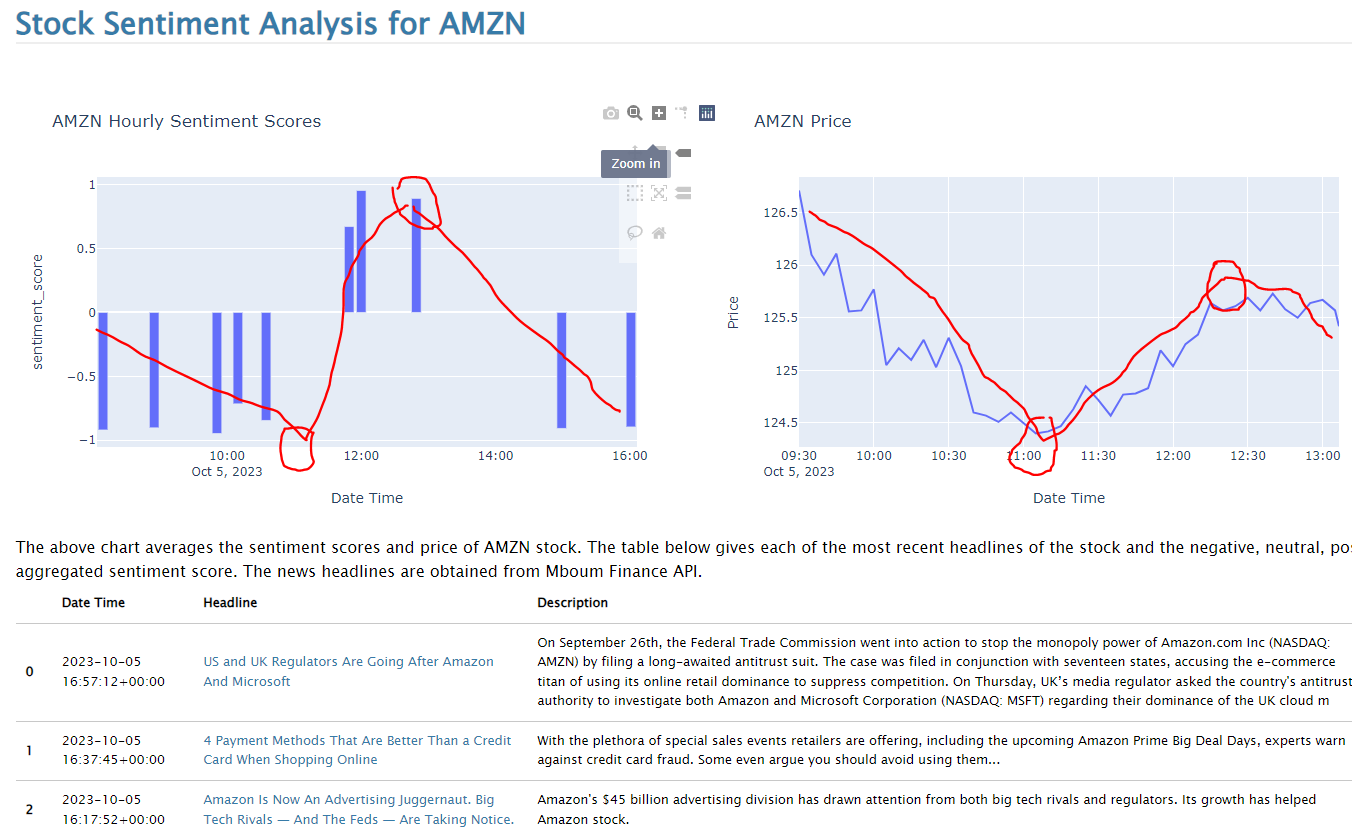
In that previous lab, I used the vaderSentiment library. This time, I’ve decided to explore another NLP contender, the FinBERT NLP algorithm, and compare it against Vader's sentiment score accuracy with the intent of improving trading strategy returns.
The primary data source remains unchanged. Leveraging the Yahoo Finance API available on RapidAPI Hub, I’ve sourced the news data for our sentiment analysis exercise.
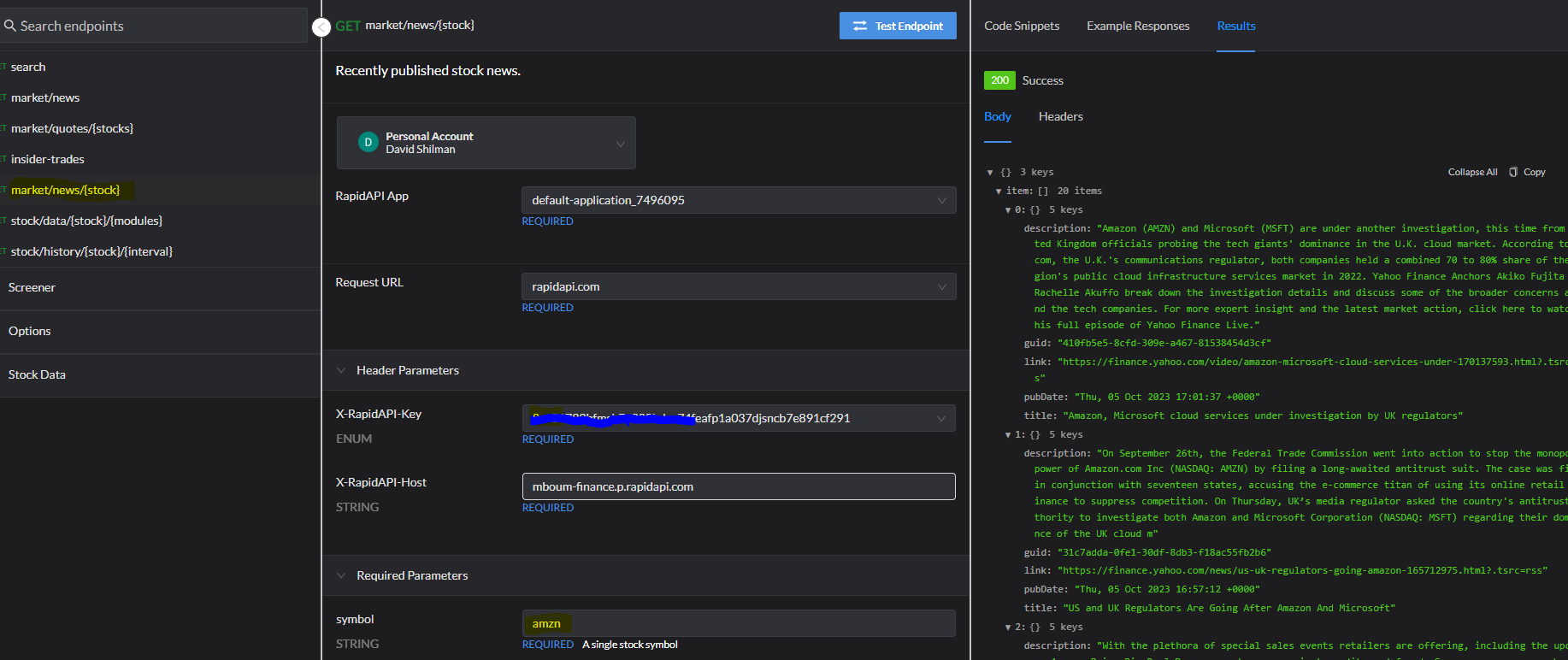
I used a Python Jupyter Notebook as the development playground for this experiment. In my Jupyter notebook, I first call the API class that retrieves market data from Yahoo and converts the JSON response into a Pandas data frame. You can find this code in my previous lab or the GitHub repo. I then apply the Vader and FinBERT ML algorithms against the "Headline" column in the data frame to compute corresponding sentiment scores and add them in a new sentiment score column for each NLP ML algorithm.

A manual comparison of these scores shows that the FinBERT ML algorithm is more accurate.

I have also introduced a significant code restructure by incorporating the following SOLID principles.
- Single responsibility principle: Market news preparation logic has been consolidated into the API class
- Open/closed principle: Both, Vader and FinBERT-specific logic reside in the subclasses of SentimentAnalysisBase
import plotly.express as px
import plotly.graph_objects as go
class SentimentAnalysisBase():
def calc_sentiment_score(self):
pass
def plot_sentiment(self) -> go.Figure:
column = 'sentiment_score'
df_plot = self.df.drop(
self.df[self.df[f'{column}'] == 0].index)
fig = px.bar(data_frame=df_plot, x=df_plot['Date Time'], y=f'{column}',
title=f"{self.symbol} Hourly Sentiment Scores")
return fig
class FinbertSentiment (SentimentAnalysisBase):
def __init__(self):
self._sentiment_analysis = pipeline(
"sentiment-analysis", model="ProsusAI/finbert")
super().__init__()
def calc_sentiment_score(self):
self.df['sentiment'] = self.df['Headline'].apply(
self._sentiment_analysis)
self.df['sentiment_score'] = self.df['sentiment'].apply(
lambda x: {x[0]['label'] == 'negative': -1, x[0]['label'] == 'positive': 1}.get(True, 0) * x[0]['score'])
super().calc_sentiment_score()
class VaderSentiment (SentimentAnalysisBase):
nltk.downloader.download('vader_lexicon')
def __init__(self) -> None:
self.vader = SentimentIntensityAnalyzer()
super().__init__()
def calc_sentiment_score(self):
self.df['sentiment'] = self.df['Headline'].apply(
self.vader.polarity_scores)
self.df['sentiment_score'] = self.df['sentiment'].apply(
lambda x: x['compound'])
super().calc_sentiment_score()I hope this article was worth your time. You can find the code in this GitHub repo.
Happy coding!!!
Opinions expressed by DZone contributors are their own.
Comments