Improving Efficiency: LinkedIn’s Transition From JSON to Protocol Buffers
LinkedIn reportedly improved its latency by 60% by migrating to Protocol Buffers. Let's understand what protocol buffers are and how they help LinkedIn.
Join the DZone community and get the full member experience.
Join For FreePrograms usually work with data in at least two different representations:
- In memory representation: In memory, data is kept in objects, structs, lists, arrays, hash tables, trees, and so on. These data structures are optimized for efficient access and manipulation by the CPU.
- Data on file and data over the network: When you want to write data to a file or send it over the network, you need to convert it as a self-contained sequence of bytes.
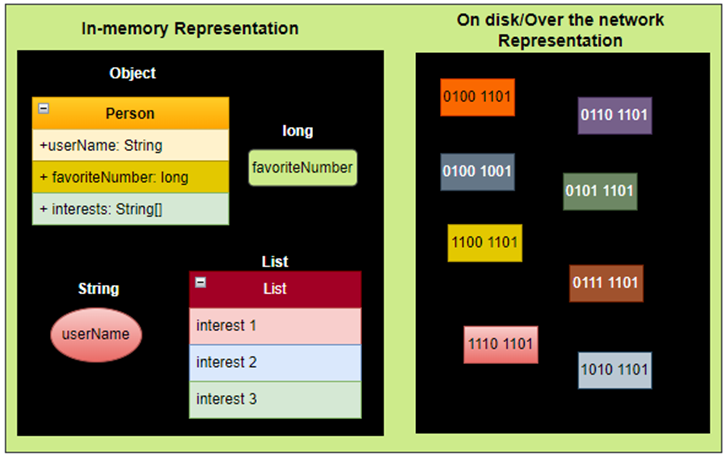
This is necessary because the data structures used in memory, such as objects or pointers, are specific to the programming language and the runtime environment. Encoding transforms the in-memory representation of data into a format that can be easily and efficiently transmitted or stored as a sequence of bytes.
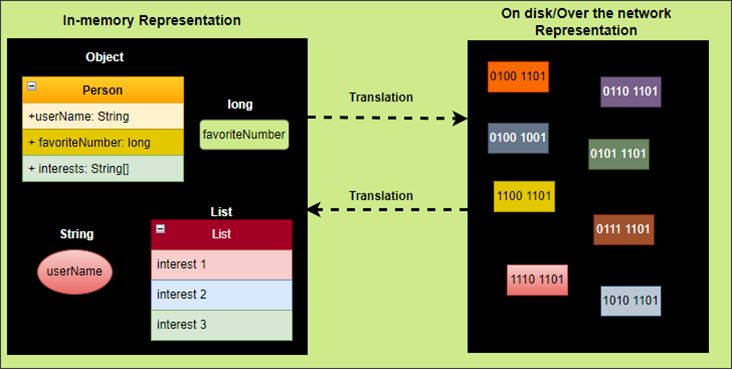
The translation from the in-memory representation to a byte sequence is called encoding (also known as serialization or marshaling), and the reverse is called decoding (parsing, deserialization, unmarshalling).
As this is a common problem, numerous encoding formats, and libraries are available to encode.
JSON, XML, and CSV are widely known and widely supported standardized encoding formats. They are textual formats and thus somewhat human-readable.
LinkedIn, in its homegrown REST framework, from inception has used JSON as its default encoding format. While JSON served well in terms of broad programming language support and human readability (which eases debuggability), its runtime performance has been far from ideal. Though several attempts were made to improve the performance of JSON encoding in the REST framework, it continued to be a bottleneck in many performance profiles.
Challenges With JSON
JSON, being a standardized encoding format, offers a broad support of programming languages and is human-readable. However, LinkedIn posed a few challenges that resulted in performance bottlenecks.
- The first challenge is that JSON is a textual format, which tends to be verbose. This results in increased network bandwidth usage and higher latencies, which is less than ideal. While the size can be optimized using standard compression algorithms like gzip, compression and decompression consume additional hardware resources and may be disproportionately expensive or unavailable in some environments.
- The second challenge was that due to the textual nature of JSON, serialization and deserialization latency and throughput were suboptimal. LinkedIn uses garbage-collected languages, like Java and Python, so improving latency and throughput is crucial to ensure efficiency.
When looking for a JSON replacement, LinkedIn wanted an alternative that satisfied a few criteria:
- Compact payload size for reduced network bandwidth and lower latencies.
- High serialization and deserialization efficiency.
- Wide programming language support.
- Easy integration into their existing REST framework for incremental migration.
After a thorough evaluation of several formats like Protobuf, Flatbuffers, Cap’n’Proto, SMILE, MessagePack, CBOR, and Kryo, it was determined that Protobuf was the best option because it performed the most effectively across the above criteria.
Let’s understand what a Protocol Buffer is.
Protocol Buffers
Protocol Buffers or Protobuf was originally developed at Google.
Schema-Based Encoding
It is a binary encoding library and requires a schema for any data that is encoded. The schema provides a predefined structure for the data, allowing for more streamlined serialization.
With a well-defined schema, Protobuf can efficiently encode and decode data without the need to include field names or additional metadata in the serialized output.
Binary Encoding
Binary encoding represents data in a binary format, meaning the data is encoded using a sequence of binary digits (0s and 1s). This contrasts with text-based encoding formats like JSON, XML, or CSV, which use human-readable characters to represent data. Binary encoding is more compact and efficient in terms of storage and transmission, resulting in faster serialization and deserialization processes. But it is not human-readable.
Protobuf supports a variety of data types, including simple types like integers and strings, as well as more complex structures like classes, structs, lists, etc.
The type efficiency ensures that data is encoded and decoded in a way that aligns with the underlying data types, reducing the overhead associated with type conversion during serialization and deserialization.
Protobuf supports multiple programming languages, allowing for efficient implementation in various language environments.
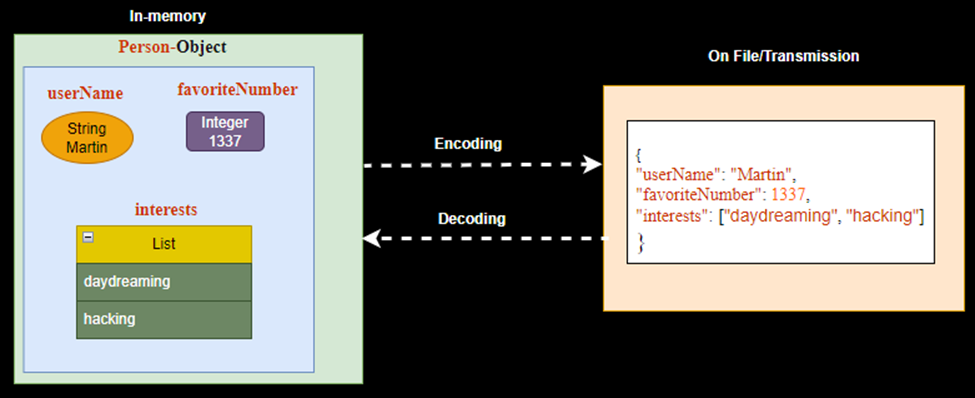
Example Record
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
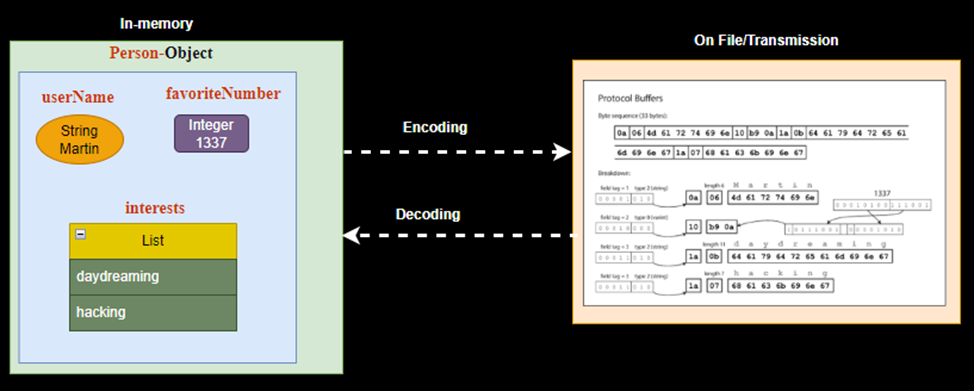
}Schema Used to Encode
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}Protocol Buffers encode the same data as:
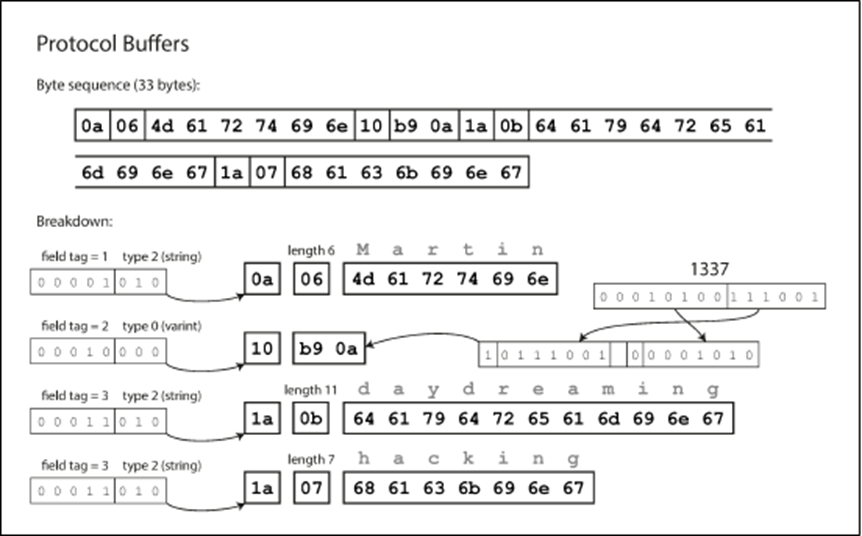
This encoding fits the record in only 33 bytes compared to the 81 bytes JSON textual format.
Also, the inherent characteristics of binary encoding, compact representation, schema-based serialization, type efficiency, standardized binary format, language agnosticism, and empirical testing collectively contributed to Protobuf's success in achieving high serialization and deserialization efficiency.
Using Protobuf resulted in an average throughput per-host increase of 6.25% for response payloads and 1.77% for request payloads across all services at LinkedIn. For services with large payloads, there was up to 60% improvement in latency.
Below is the P99 latency comparison chart from benchmarking Protobuf against JSON when servers are under heavy load.
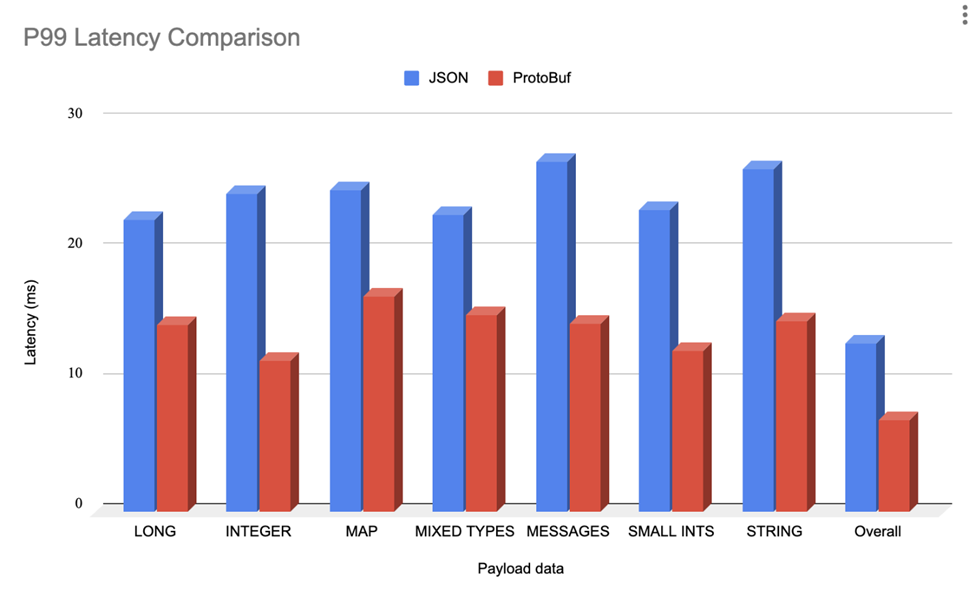
Conclusion
The shift from JSON to Protobuf at LinkedIn showcases tangible efficiency wins, emphasizing the importance of choosing the right encoding format for improved performance at scale.
Must READ for Continuous Learning:
- System Design
- Head First Design Patterns
- Clean Code: A Handbook of Agile Software Craftsmanship
- Java Concurrency in Practice
- Java Performance: The Definitive Guide
- Designing Data-Intensive Applications
- Designing Distributed Systems
- Clean Architecture
- Kafka – The Definitive Guide
- Becoming An Effective Software Engineering Manager
Published at DZone with permission of Roopa Kushtagi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments