Implementing Cloud-Native Enterprise Applications with Open-Source Software
From our recently-release Containers Guide, check out this article that will show you how you can utilize OSS to create and manage cloud native applications.
Join the DZone community and get the full member experience.
Join For FreeThis article is featured in the new DZone Guide to Containers: Development and Management. Get your free copy for more insightful articles, industry statistics, and more!
Linux container technologies such as kernel namespaces, cgroups, chroot, AppArmor, and SELinux policies have been in development since 1979. In 2013, an organization called dotCloud built a complete ecosystem for making Linux containers extremely usable by introducing a better interface, a REST API, a CLI, and a layered container image format — and called it Docker. This exploded the interest in Linux containers and began to revolutionize the way software is being designed and deployed to achieve optimal infrastructure resource usage, scalability, and maintenance. Google, who was contributing to cgroups, LMCTFY, and other related Linux kernel features, initiated the Kubernetes project in 2014. With their experience of running containers at scale over a decade, Google was well-positioned to introduce this open-source container cluster manager. This made the next major milestone of container technologies, which lead to the inception of newer architectural patterns, distributed service management frameworks, serverless technologies, observability tools, and, most importantly, the Cloud Native Computing Foundation (CNCF).
Today, enterprises are rapidly adopting these technologies for implementing production systems using containers at different scales. CNCF is now taking the lead on standardizing the cloud-native technology stack by categorizing the spectrum, defining specifications, improving interoperability, allowing technology leaders to collaborate, and building an open-source, vendor-neutral ecosystem that is portable to public, private, and hybrid clouds.
What Is Cloud-native?
"Cloud-native" is nothing new, but it's a new term to define the concepts used for building and running applications on any cloud platform without having to change the application code. This approach may involve adopting microservices architecture, containerizing application components, and dynamically orchestrating containers using a cloud-agnostic container cluster manager — including tools for managing services and observing the deployments.
A Reference Architecture for Implementing Cloud-native Enterprise Systems
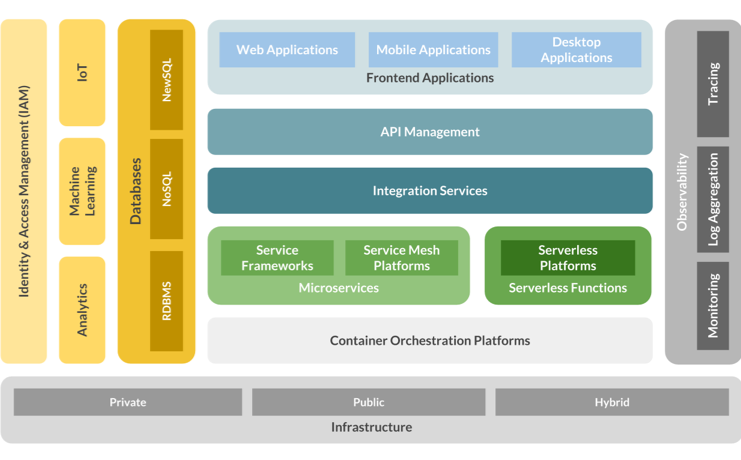
Figure 1: A reference architecture for cloud-native enterprise systems.
The above diagram illustrates a reference architecture for implementing cloud-native enterprise systems using container-based technologies. According to the current state of the ecosystem, microservices, serverless functions, integration services, and managed APIs are ready to be deployed on containers handling production workloads. Those components can be deployed on private, public, and hybrid cloud environments using a cloud-agnostic container orchestrator. Nevertheless, stateful, complex distributed systems such as database management systems, analytics platforms, message brokers, and business process servers may need more maturity at the container cluster manager and at the application level for natively supporting completely automated deployments.
Container Orchestration
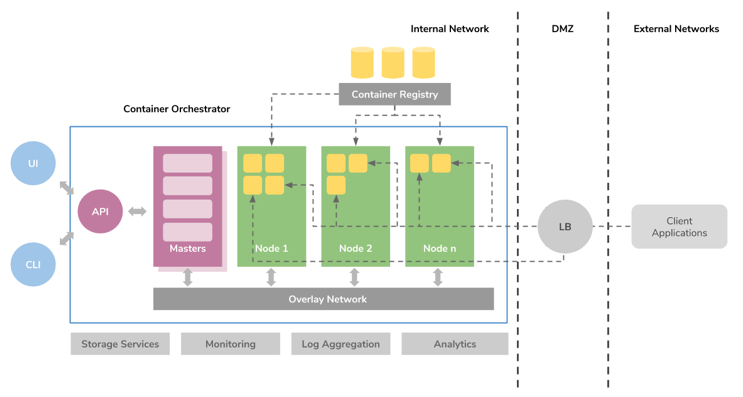
Figure 2: A reference architecture for a container cluster manager.
Today, Kubernetes is considered to be the most compelling open-source platform for orchestrating containers. It is now at Version 1.10 and currently being used in production to manage hundreds (if not thousands) of container hosts running millions of containers. At its core, it provides features for container grouping, self-healing, service discovery, load balancing, autoscaling, running daemons, managing stateful components, managing configurations, credentials, and persistent volumes. Moreover, it provides extension points to implement custom resources and controllers for advanced orchestration requirements needed by complex systems such as big data analytics, databases, and message brokers. Kubernetes can be installed on any virtualization platform without requiring any special tools, and can be spawned on AWS, Google Cloud, Azure, IBM Cloud, and Oracle Cloud as managed services by only paying for the virtual machines required for running the workloads.
Alternatively, organizations can also use RedHat OpenShift, Mesosphere DC/OS, Hashicorp Nomad, and Docker Swarm for container orchestration. OpenShift is a Kubernetes distribution which provides additional application lifecycle management and security features. It is available as CentOS-based open-source distribution and RHEL-based enterprise distribution. DC/OS has been implemented using Apache Mesos, Marathon, and Metronome by Mesosphere, and it's specifically optimized for running big data analytics systems such as Apache Spark, Cassandra, Kafka, HDFS, etc. It also has an open-source distribution and an enterprise edition. Some key features such as user management and credential management are missing in the open-source version. Docker Swarm is another container cluster manager implemented by Docker which is bundled into the Docker runtime. By design, it integrates well with Docker and provides a simpler deployment model compared to other systems. Nevertheless, Swarm has not been adopted much in the industry in comparison to other cluster managers.
Microservices For Better Agility, Speed, And Cost
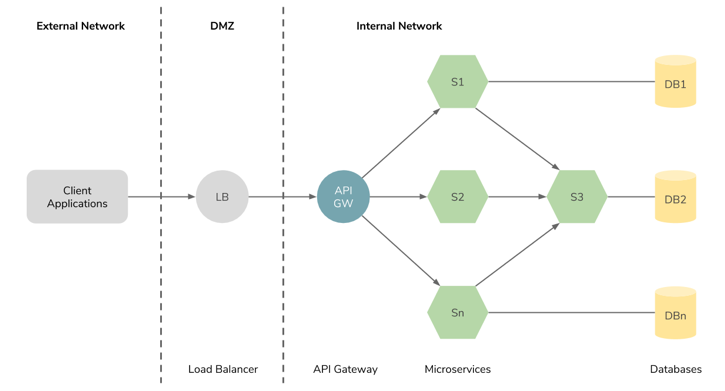
Figure 3: A reference implementation of microservices architecture.
Microservices architectural style proposes that an application should be implemented as a collection of independently manageable, lightweight services — in contrast to its opposite, monolith architecture, in which an application is implemented as a single unit. The microservices approach allows each service to have a single focus, loosely coupled, lightweight, highly scalable modular architecture to achieve better resource usages, optimized deployment models, fewer maintenance costs, and faster delivery times. Such services can be implemented in any programming language that supports REST- and RPC-based services.
Spring Boot, Dropwizard, and Spark are the most widely used open-source microservices frameworks for Java. Out of these, Spring Boot provides the advantages of Spring's dependency injection, data access, batch processing, security, and integration inclinations. Services that are mission-critical and require the merest latencies can be implemented with Golang using Echo, Iris, or Go kit. Otherwise, if the developers' preference is more toward JavaScript Express, Feathers and LoopBack would be striking options. LoopBack stands out for exposing CRUD APIs with OAuth2 security with a few lines of code. Besides the above, Flask, Sanic, and Tornado would be attractive alternatives for Python developers.
Optimal Governance for Microservices with Service Mesh Architecture
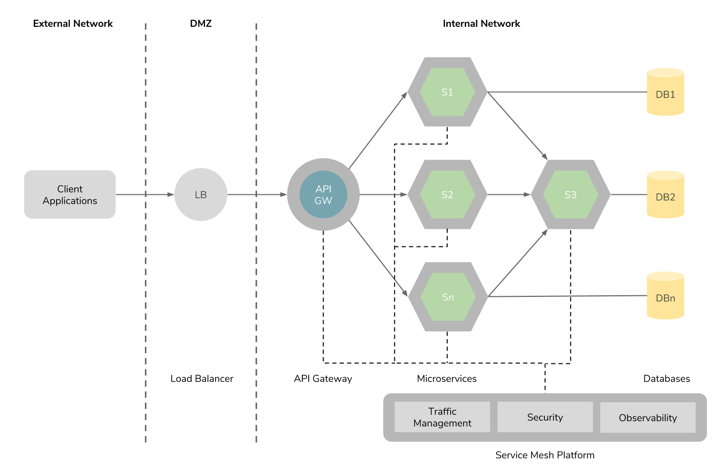
Figure4: Usage of a service mesh in microservices architecture.
Once a large system is decomposed into hundreds and thousands of smaller services according to microservices architecture (MSA), managing inter-service communications, service identity, authorization, monitoring, logging, and obtaining telemetry data might become challenging tasks. Last year, IBM, Google, and Lyft joined together to implement a solution for this problem with the Istio project, by combining IBM's Amalgam8 project, Google's Service Control implementation, and Lyft's Envoy proxy. Istio might be today's most comprehensive service mesh platform that can provide traffic management, security, policy enforcement, and telemetry data extraction at the application deployment time without having to implement the code in the services. Istio does this by injecting Envoy proxy into the service pods and dynamically intercepting the communication between services for controlling traffic using a central management layer. Service security can be managed with Istio using Mutual TLS. Role-Based Access Control (RBAC) monitoring is provided with Prometheus, Grafana, Heapster, and native GCP and AWS monitoring tools, and distributed tracing is provided with Zipkin and Jaeger. Due to the popularity of Istio, NGINX implemented another service mesh based on Istio called nginMesh by using NGINX as the sidecar proxy.
Linkerd is another popular open-source service mesh platform implemented using Finagle and Netty (by Buoyant and later donated to CNCF). Linkerd uses proxy daemons on each container host for intercepting inter-service communication unlike proxy sidecars in Istio. This model requires services to route requests specifically to the proxies using additional configurations. Buoyant has improved this architecture and produced Conduit, targeting Kubernetes by incorporating a Kubernetes object injection model similar to Istio.
Using Serverless Functions for Event-Driven Executions
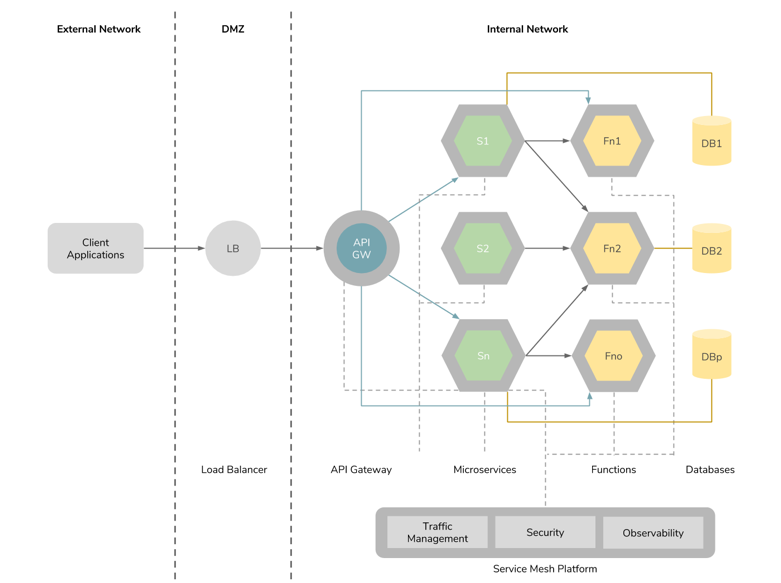
Figure 5: Usage of serverless functions in microservices architecture.
One of the key aspects of MSA is its ability to reduce the infrastructure resource usage by allocating resources at a granular level according to the actual service resource requirements. Nevertheless, at any given time, it would need to run at least one container per service. The serverless architecture attempts to further optimize this by decomposing the deployable unit up to functions and running functions only when needed. Serverless functions became popular when AWS introduced the AWS Lambda platform. Today, almost all public cloud vendors provide a similar offering, such as Google Cloud Functions, Azure Functions, and IBM Cloud Functions. Most of these platforms support programming languages such as Node.js, Java, and Python — except for Google Functions, which only supports Node.js. On the above public cloud offerings, users only get billed for the number of function invocations, considering the amount of infrastructure resources and time required for executing each.
Modern enterprises are now adopting microservices architecture for implementing highly scalable, cloud-agnostic applications that achieve better agility, speed, and lower cost.
Today, Apache OpenWhisk is one of the most widely used serverless frameworks for implementing on-premise serverless systems. It was initially developed by IBM and later donated to ASF for wider community adoption. OpenWhisk was designed using a highly extensible architecture to enable adding new languages and event triggers without much effort. Moreover, it supports creating a chain of functions for implementing a sequence of business operations. One of the key design decisions OpenWhisk has made for optimizing resource usage is to create containers on demand and preserve them for a given period of time.
Fission is another popular serverless platform specifically designed for Kubernetes. In contrast to OpenWhisk, Fission uses a configurable pool of containers for reducing the cold start time of functions and provides function composition capabilities. In terms of deployment, Fission can be integrated with Istio for incorporating service mesh features and function autoscaling based on Kubernetes Horizontal Pod Autoscalers. Kubeless is a similar platform developed by Bitnami for hosting serverless functions on Kubernetes. It uses a custom Kubernetes resource for deploying code, and as a result, functions can be managed using the standard Kubernetes CLI.
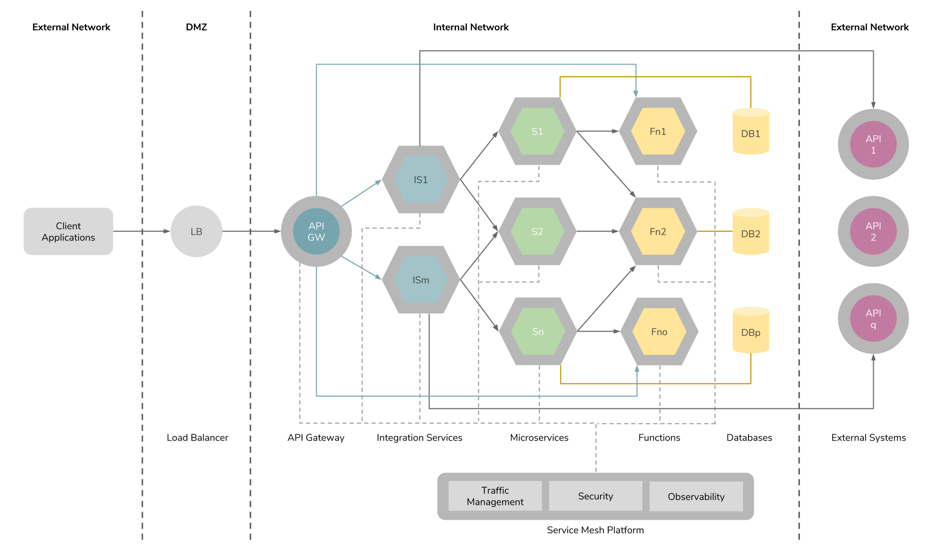
Figure 6: Usage of integration services in microservices architecture.
Implementing integrations can be achieved through microservices using standard programming constructs. If the system grows over time, it would require a considerable amount of effort and repetitive work by introducing a considerable amount of integrations. Ballerina is a new programming language purposely built by WSO2 to fill this gap in the container native ecosystem. It provides integration constructs and connectors for implementing distributed system integrations with distributed transactions, reliable messaging, stream processing, and workflows. It provides native support for Kubernetes, Prometheus, and Jaeger.
Distributed Observability Tools for Immeasurable Insights
Observability mainly divides into three categories: monitoring, logging, and tracing. Monitoring involves observing the health of the applications, including socket status, resource usage, request counts, latencies, etc., and generating alerts for the operations teams to take actions on actual system failures (excluding false positives). Prometheus is one of the most widely used tools available today for monitoring distributed systems. It was initially developed as an open-source project by ex-Googlers working at SoundCloud and later donated to CNCF. Prometheus provides features for active scraping, storing, querying, graphing, and alerting based on time series data.
Centralized logging is the second crucial aspect of distributed systems for investigating issues in production environments. Fluentd is one of the main open-source projects of this segment. It provides a unified logging system for connecting various sources of log data to various destination systems. Fluentd was initially developed at Treasure Data and later donated to CNCF. It can be integrated with other open-source monitoring tools, such as Elasticsearch and Kibana, to implement a complete solution for monitoring service logs. Moreover, it can be used for collecting data from a wide variety of systems (including lightweight IoT devices) and building data analytics systems.
Distributed tracing is the third key aspect. Distributed tracing helps provide better insights on analyzing latency bottlenecks, root-cause analysis of errors, resource utilization issues, etc., for applications that are built using a composition of services. Jaeger, Zipkin, and AppDash are three popular open-source projects inspired by Google's distributed tracing platform Dapper. Out of these three, Jaeger and Zipkin are more popular, and Jaeger has better support for OpenTracing-compatible clients.
Conclusion
Modern enterprises are now adopting microservices architecture for implementing highly scalable, cloud-agnostic applications that achieve better agility, speed, and lower cost. At a high level, designing such systems may require technologies for container orchestration, implementing microservices, serverless functions, integration services, APIs, service management, and observability. Today, CNCF is taking the lead in providing a vendor-neutral ecosystem for implementing such cloud-native applications using open-source technologies that empower state-of-the-art patterns and practices. Over the last few years, container orchestration features required for hosting stateless applications have matured and are now used in production by many organizations. The mechanics required to run complex stateful applications on containers, such as distributed databases and big data analytics systems, are now being supported. Over time, almost all software applications may run on container platforms incorporating the above technologies. Therefore, organizations should plan for the future by considering the reference architecture explained in this article.
References
This article is featured in the new DZone Guide to Containers: Development and Management. Get your free copy for more insightful articles, industry statistics, and more!
Opinions expressed by DZone contributors are their own.
Comments