Implementation of the Raft Consensus Algorithm Using C++20 Coroutines
Detailed implementation of Raft consensus using C++20 coroutines, emphasizing algorithmic challenges and a specialized network library.
Join the DZone community and get the full member experience.
Join For FreeThis article describes how to implement a Raft Server consensus module in C++20 without using any additional libraries. The narrative is divided into three main sections:
- A comprehensive overview of the Raft algorithm
- A detailed account of the Raft Server's development
- A description of a custom coroutine-based network library
The implementation makes use of the robust capabilities of C++20, particularly coroutines, to present an effective and modern methodology for building a critical component of distributed systems. This exposition not only demonstrates the practical application and benefits of C++20 coroutines in sophisticated programming environments, but it also provides an in-depth exploration of the challenges and resolutions encountered while building a consensus module from the ground up, such as Raft Server. The Raft Server and network library repositories, miniraft-cpp and coroio, are available for further exploration and practical applications.
Introduction
Before delving into the complexities of the Raft algorithm, let’s consider a real-world example. Our goal is to develop a network key-value storage (K/V) system. In C++, this can be easily accomplished by using an unordered_map<string, string>. However, in real-world applications, the requirement for a fault-tolerant storage system increases complexity. A seemingly simple approach could entail deploying three (or more) machines, each hosting a replica of this service. The expectation may be for users to manage data replication and consistency. However, this method can result in unpredictable behaviors. For example, it is possible to update data using a specific key and then retrieve an older version later.
What users truly want is a distributed system, potentially spread across multiple machines, that runs as smoothly as a single-host system. To meet this requirement, a consensus module is typically placed in front of the K/V storage (or any similar service, hereafter referred to as the "state machine"). This configuration ensures that all user interactions with the state machine are routed exclusively through the consensus module, rather than direct access. With this context in mind, let us now look at how to implement such a consensus module, using the Raft algorithm as an example.
Raft Overview
In the Raft algorithm, there are an odd number of participants known as peers. Each peer keeps its own log of records. There is one peer leader, and the others are followers. Users direct all requests (reads and writes) to the leader. When a write request to change the state machine is received, the leader logs it first before forwarding it to the followers, who also log it. Once the majority of peers have successfully responded, the leader considers this entry to be committed, applies it to the state machine, and notifies the user of its success.
The Term is a key concept in Raft, and it can only grow. The Term changes when there are system changes, such as a change in leadership. The log in Raft has a specific structure, with each entry consisting of a Term and a Payload. The term refers to the leader who wrote the initial entry. The Payload represents the changes to be made to the state machine. Raft guarantees that two entries with the same index and term are identical. Raft logs are not append-only and may be truncated. For example, in the scenario below, leader S1 replicated two entries before crashing. S2 took the lead and began replicating entries, and S1's log differed from those of S2 and S3. As a result, the last entry in the S1 log will be removed and replaced with a new one.

Raft RPC API
Let us examine the Raft RPC. It's worth noting that the Raft API is quite simple, with just two calls. We'll begin by looking at the leader election API. It is important to note that Raft ensures that there can only be one leader per term. There may also be terms without a leader, such as if elections fail. To ensure that only one election occurs, a peer saves its vote in a persistent variable called VotedFor. The election RPC is called RequestVote and has three parameters: Term, LastLogIndex, and LastLogTerm. The response contains Term and VoteGranted. Notably, every request contains Term, and in Raft, peers can only communicate effectively if their Terms are compatible.
When a peer initiates an election, it sends a RequestVote request to the other peers and collects their votes. If the majority of the responses are positive, the peer advances to the leader role.
Now let's look at the AppendEntries request. It accepts parameters such as Term, PrevLogIndex, PrevLogTerm, and Entries, and the response contains Term and Success. If the Entries field in the request is empty, it acts as a Heartbeat.
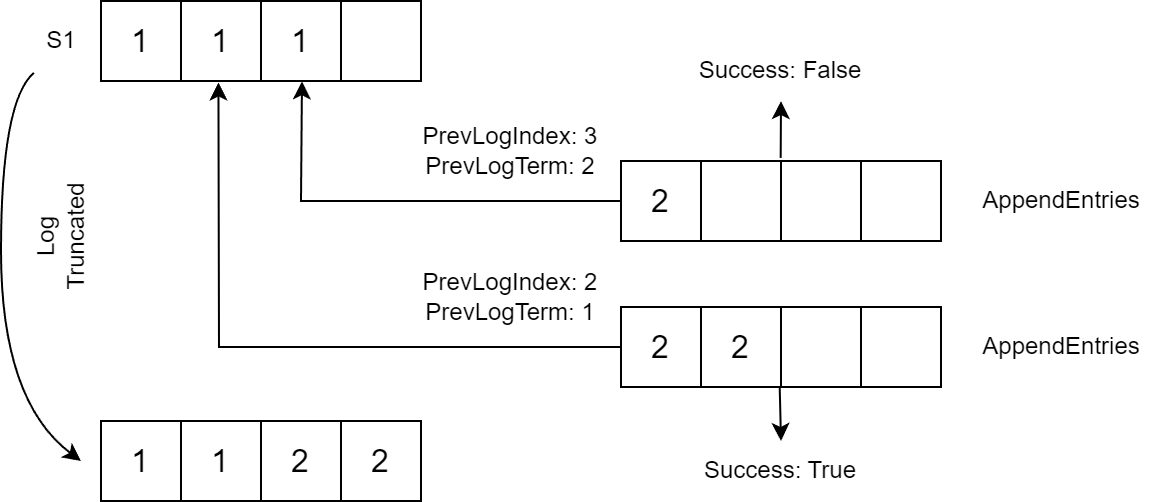
When an AppendEntries request is received, a follower checks the PrevLogIndex for the Term. If it matches PrevLogTerm, the follower adds Entries to its log beginning with PrevLogIndex + 1 (entries after PrevLogIndex are removed if they exist):
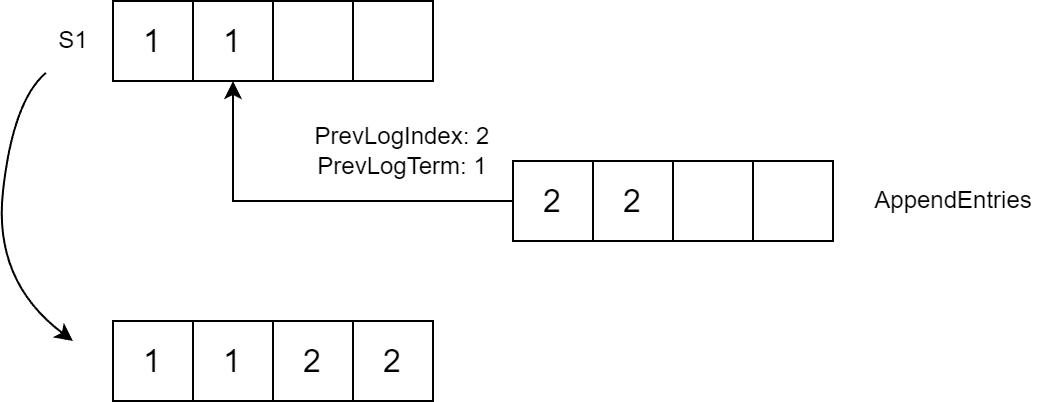
If the terms do not match, the follower returns Success=false. In this case, the leader retries sending the request, lowering the PrevLogIndex by one.
When a peer receives a RequestVote request, it compares its LastTerm and LastLogIndex pairs to the most recent log entry. If the pair is less than or equal to the requestor's, the peer returns VoteGranted=true.
State Transitions in Raft
Raft's state transitions look like this. Each peer begins in the Follower state. If a Follower does not receive AppendEntries within a set timeout, it extends its Term and moves to the Candidate state, triggering an election. A peer can move from the Candidate state to the Leader state if it wins the election, or return to the Follower state if it receives an AppendEntries request. A Candidate can also revert to being a Candidate if it does not transition to either a Follower or a Leader within the timeout period. If a peer in any state receives an RPC request with a Term greater than its current one, it moves to the Follower state.
Commit
Let us now consider an example that demonstrates how Raft is not as simple as it may appear. I took this example from Diego Ongaro's dissertation. S1 was the leader in Term 2, where it replicated two entries before crashing. Following this, S5 took the lead in Term 3, added an entry, and then crashed. Next, S2 took over leadership in Term 4, replicated the entry from Term 2, added its own entry for Term 4, and then crashed. This results in two possible outcomes: S5 reclaims leadership and truncates the entries from Term 2, or S1 regains leadership and commits the entries from Term 2. The entries from Term 2 are securely committed only after they are covered by a subsequent entry from a new leader.

This example demonstrates how the Raft algorithm operates in a dynamic and often unpredictable set of circumstances. The sequence of events, which includes multiple leaders and crashes, demonstrates the complexity of maintaining a consistent state across a distributed system. This complexity is not immediately apparent, but it becomes important in situations involving leader changes and system failures. The example emphasizes the importance of a robust and well-thought-out approach to dealing with such complexities, which is precisely what Raft seeks to address.
Additional Materials
For further study and a deeper understanding of Raft, I recommend the following materials: the original Raft paper, which is ideal for implementation. Diego Ongaro's PhD dissertation provides more in-depth insights. Maxim Babenko's lecture goes into even greater detail.
Raft Implementation
Let's now move on to the Raft server implementation, which, in my opinion, benefits greatly from C++20 coroutines. In my implementation, the Persistent State is stored in memory. However, in real-world scenarios, it should be saved to disk. I'll talk more about the MessageHolder later. It functions similarly to a shared_ptr, but is specifically designed to handle Raft messages, ensuring efficient management and processing of these communications.
struct TState {
uint64_t CurrentTerm = 1;
uint32_t VotedFor = 0;
std::vector<TMessageHolder<TLogEntry>> Log;
};In the Volatile State, I labeled entries with either L for "leader" or F for "follower" to clarify their use. The CommitIndex denotes the last log entry that was committed. In contrast, LastApplied is the most recent log entry applied to the state machine, and it is always less than or equal to the CommitIndex. The NextIndex is important because it identifies the next log entry to be sent to a peer. Similarly, MatchIndex keeps track of the last log entry that discovered a match. The Votes section contains the IDs of peers who voted for me. Timeouts are an important aspect to manage: HeartbeatDue and RpcDue manage leader timeouts, while ElectionDue handles follower timeouts.
using TTime = std::chrono::time_point<std::chrono::steady_clock>;
struct TVolatileState {
uint64_t CommitIndex = 0; // L,F
uint64_t LastApplied = 0; // L,F
std::unordered_map<uint32_t, uint64_t> NextIndex; // L
std::unordered_map<uint32_t, uint64_t> MatchIndex; // L
std::unordered_set<uint32_t> Votes; // C
std::unordered_map<uint32_t, TTime> HeartbeatDue; // L
std::unordered_map<uint32_t, TTime> RpcDue; // L
TTime ElectionDue; // F
};Raft API
My implementation of the Raft algorithm has two classes. The first is INode, which denotes a peer. This class includes two methods: Send, which stores outgoing messages in an internal buffer, and Drain, which handles actual message dispatch. Raft is the second class, and it manages the current peer's state. It also includes two methods: Process, which handles incoming connections, and ProcessTimeout, which must be called on a regular basis to manage timeouts, such as the leader election timeout. Users of these classes should use the Process, ProcessTimeout, and Drain methods as necessary. INode's Send method is invoked internally within the Raft class, ensuring that message handling and state management are seamlessly integrated within the Raft framework.
struct INode {
virtual ~INode() = default;
virtual void Send(TMessageHolder<TMessage> message) = 0;
virtual void Drain() = 0;
};
class TRaft {
public:
TRaft(uint32_t node,
const std::unordered_map<uint32_t, std::shared_ptr<INode>>& nodes);
void Process(TTime now,
TMessageHolder<TMessage> message,
const std::shared_ptr<INode>& replyTo = {});
void ProcessTimeout(TTime now);
};Raft Messages
Now let's look at how I send and read Raft messages. Instead of using a serialization library, I read and send raw structures in TLV format. This is what the message header looks like:
struct TMessage {
uint32_t Type;
uint32_t Len;
char Value[0];
};For additional convenience, I've introduced a second-level header:
struct TMessageEx: public TMessage {
uint32_t Src = 0;
uint32_t Dst = 0;
uint64_t Term = 0;
};This includes the sender's and receiver's ID in each message. With the exception of LogEntry, all messages inherit from TMessageEx. LogEntry and AppendEntries are implemented as follows:
struct TLogEntry: public TMessage {
static constexpr EMessageType MessageType = EMessageType::LOG_ENTRY;
uint64_t Term = 1;
char Data[0];
};
struct TAppendEntriesRequest: public TMessageEx {
static constexpr EMessageType MessageType
= EMessageType::APPEND_ENTRIES_REQUEST;
uint64_t PrevLogIndex = 0;
uint64_t PrevLogTerm = 0;
uint32_t Nentries = 0;
};
To facilitate message handling, I use a class called MessageHolder, reminiscent of a shared_ptr:
template<typename T>
requires std::derived_from<T, TMessage>
struct TMessageHolder {
T* Mes;
std::shared_ptr<char[]> RawData;
uint32_t PayloadSize;
std::shared_ptr<TMessageHolder<TMessage>[]> Payload;
template<typename U>
requires std::derived_from<U, T>
TMessageHolder<U> Cast() {...}
template<typename U>
requires std::derived_from<U, T>
auto Maybe() { ... }
};This class includes a char array containing the message itself. It may also include a Payload (which is only used for AppendEntry), as well as methods for safely casting a base-type message to a specific one (the Maybe method) and unsafe casting (the Cast method). Here is a typical example of using the MessageHolder:
void SomeFunction(TMessageHolder<TMessage> message) {
auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>();
if (maybeAppendEntries) {
auto appendEntries = maybeAppendEntries.Cast();
}
// if we are sure
auto appendEntries = message.Cast<TAppendEntriesRequest>();
// usage with overloaded operator->
auto term = appendEntries->Term;
auto nentries = appendEntries->Nentries;
// ...
}And a real-life example in the Candidate state handler:
void TRaft::Candidate(TTime now, TMessageHolder<TMessage> message) {
if (auto maybeResponseVote = message.Maybe<TRequestVoteResponse>()) {
OnRequestVote(std::move(maybeResponseVote.Cast()));
} else
if (auto maybeRequestVote = message.Maybe<TRequestVoteRequest>())
{
OnRequestVote(now, std::move(maybeRequestVote.Cast()));
} else
if (auto maybeAppendEntries = message.Maybe<TAppendEntriesRequest>())
{
OnAppendEntries(now, std::move(maybeAppendEntries.Cast()));
}
}This design approach improves the efficiency and flexibility of message handling in Raft implementations.
Raft Server
Let's discuss the Raft server implementation. The Raft server will set up coroutines for network interactions. First, we'll look at the coroutines that handle message reading and writing. The primitives used for these coroutines are discussed later in the article, along with an analysis of the network library. The writing coroutine is responsible for writing messages to the socket, whereas the reading coroutine is slightly more complex. To read, it must first retrieve the Type and Len variables, then allocate an array of Len bytes, and finally, read the rest of the message. This structure facilitates the efficient and effective management of network communications within the Raft server.
template<typename TSocket>
TValueTask<void>
TMessageWriter<TSocket>::Write(TMessageHolder<TMessage> message) {
co_await TByteWriter(Socket).Write(message.Mes, message->Len);
auto payload = std::move(message.Payload);
for (uint32_t i = 0; i < message.PayloadSize; ++i) {
co_await Write(std::move(payload[i]));
}
co_return;
}
template<typename TSocket>
TValueTask<TMessageHolder<TMessage>> TMessageReader<TSocket>::Read() {
decltype(TMessage::Type) type; decltype(TMessage::Len) len;
auto s = co_await Socket.ReadSome(&type, sizeof(type));
if (s != sizeof(type)) { /* throw */ }
s = co_await Socket.ReadSome(&len, sizeof(len));
if (s != sizeof(len)) { /* throw */}
auto mes = NewHoldedMessage<TMessage>(type, len);
co_await TByteReader(Socket).Read(mes->Value, len - sizeof(TMessage));
auto maybeAppendEntries = mes.Maybe<TAppendEntriesRequest>();
if (maybeAppendEntries) {
auto appendEntries = maybeAppendEntries.Cast();
auto nentries = appendEntries->Nentries; mes.InitPayload(nentries);
for (uint32_t i = 0; i < nentries; i++) mes.Payload[i] = co_await Read();
}
co_return mes;
}To launch a Raft server, create an instance of the RaftServer class and call the Serve method. The Serve method starts two coroutines. The Idle coroutine is responsible for periodically processing timeouts, whereas InboundServe manages incoming connections.
class TRaftServer {
public:
void Serve() {
Idle();
InboundServe();
}
private:
TVoidTask InboundServe();
TVoidTask InboundConnection(TSocket socket);
TVoidTask Idle();
}Incoming connections are received via the accept call. Following this, the InboundConnection coroutine is launched, which reads incoming messages and forwards them to the Raft instance for processing. This configuration ensures that the Raft server can efficiently handle both internal timeouts and external communication.
TVoidTask InboundServe() {
while (true) {
auto client = co_await Socket.Accept();
InboundConnection(std::move(client));
}
co_return;
}
TVoidTask InboundConnection(TSocket socket) {
while (true) {
auto mes = co_await TMessageReader(client->Sock()).Read();
Raft->Process(std::chrono::steady_clock::now(), std::move(mes),
client);
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
}
co_return;
}The Idle coroutine works as follows: it calls the ProcessTimeout method every sleep second. It's worth noting that this coroutine uses asynchronous sleep. This design enables the Raft server to efficiently manage time-sensitive operations without blocking other processes, improving the server's overall responsiveness and performance.
while (true) {
Raft->ProcessTimeout(std::chrono::steady_clock::now());
DrainNodes();
auto t1 = std::chrono::steady_clock::now();
if (t1 > t0 + dt) {
DebugPrint();
t0 = t1;
}
co_await Poller.Sleep(t1 + sleep);
}The coroutine was created for sending outgoing messages and is designed to be simple. It repeatedly sends all accumulated messages to the socket in a loop. In the event of an error, it starts another coroutine that is responsible for connecting (via the connect function). This structure ensures that outgoing messages are handled smoothly and efficiently while remaining robust through error handling and connection management.
try {
while (!Messages.empty()) {
auto tosend = std::move(Messages); Messages.clear();
for (auto&& m : tosend) {
co_await TMessageWriter(Socket).Write(std::move(m));
}
}
} catch (const std::exception& ex) {
Connect();
}
co_return;With the Raft Server implemented, these examples show how coroutines greatly simplify development. While I haven't looked into Raft's implementation (trust me, it's much more complex than the Raft Server), the overall algorithm is not only simple but also compact in design.
Next, we'll look at some Raft Server examples. Following that, I'll describe the network library I created from scratch specifically for the Raft Server. This library is critical to enabling efficient network communication within the Raft framework.
Here's an example of launching a Raft cluster with three nodes. Each instance receives its own ID as an argument, as well as the other instances' addresses and IDs. In this case, the client communicates exclusively with the leader. It sends random strings while keeping a set number of in-flight messages and waiting for their commitment. This configuration depicts the interaction between the client and the leader in a multi-node Raft environment, demonstrating the algorithm's handling of distributed data and consensus.
$ ./server --id 1 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Candidate, Term: 2, Index: 0, CommitIndex: 0,
...
Leader, Term: 3, Index: 1080175, CommitIndex: 1080175, Delay: 2:0 3:0
MatchIndex: 2:1080175 3:1080175 NextIndex: 2:1080176 3:1080176
....
$ ./server --id 2 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
$ ./server --id 3 --node 127.0.0.1:8001:1 --node 127.0.0.1:8002:2 --node 127.0.0.1:8003:3
...
Follower, Term: 3, Index: 1080175, CommitIndex: 1080175,
...
$ dd if=/dev/urandom | base64 | pv -l | ./client --node 127.0.0.1:8001:1 >log1
198k 0:00:03 [159.2k/s] [ <=>I measured the commit latency for configurations of both 3-node and 5-node clusters. As expected, the latency is higher for the 5-node setup:
- 3 Nodes
- 50 percentile (median): 292,872 ns
- 80 percentile: 407,561 ns
- 90 percentile: 569,164 ns
- 99 percentile: 40,279,001 ns
5 Nodes
- 50 percentile (median): 425,194 ns
- 80 percentile: 672,541 ns
- 90 percentile: 1,027,669 ns
- 99 percentile: 38,578,749 ns
I/O Library
Let's now look at the I/O library that I created from scratch and used in the Raft server's implementation. I began with the example below, taken from cppreference.com, which is an implementation of an echo server:
task<> tcp_echo_server() {
char data[1024];
while (true) {
std::size_t n = co_await socket.async_read_some(buffer(data));
co_await async_write(socket, buffer(data, n));
}
}An event loop, a socket primitive, and methods like read_some/write_some (named ReadSome/WriteSome in my library) were required for my library, as well as higher-level wrappers such as async_write/async_read (named TByteReader/TByteWriter in my library).
To implement the ReadSome method of the socket, I had to create an Awaitable as follows:
auto ReadSome(char* buf, size_t size) {
struct TAwaitable {
bool await_ready() { return false; /* always suspend */ }
void await_suspend(std::coroutine_handle<> h) {
poller->AddRead(fd, h);
}
int await_resume() {
return read(fd, b, s);
}
TSelect* poller; int fd; char* b; size_t s;
};
return TAwaitable{Poller_,Fd_,buf,size};
}When co_await is called, the coroutine suspends because await_ready returns false. In await_suspend, we capture the coroutine_handle and pass it along with the socket handle to the poller. When the socket is ready, the poller calls the coroutine_handle to restart the coroutine. Upon resumption, await_resume is called, which performs a read and returns the number of bytes read to the coroutine. The WriteSome, Accept, and Connect methods are implemented in a similar manner.
The Poller is set up as follows:
struct TEvent {
int Fd; int Type; // READ = 1, WRITE = 2;
std::coroutine_handle<> Handle;
};
class TSelect {
void Poll() {
for (const auto& ch : Events) { /* FD_SET(ReadFds); FD_SET(WriteFds);*/ }
pselect(Size, ReadFds, WriteFds, nullptr, ts, nullptr);
for (int k = 0; k < Size; ++k) {
if (FD_ISSET(k, WriteFds)) {
Events[k].Handle.resume();
}
// ...
}
}
std::vector<TEvent> Events;
// ...
};I keep an array of pairs (socket descriptor, coroutine handle) that are used to initialize structures for the poller backend (in this case, select). Resume is called when the coroutines corresponding to ready sockets wake up.
This is applied in the main function as follows:
TSimpleTask task(TSelect& poller) {
TSocket socket(0, poller);
char buffer[1024];
while (true) {
auto readSize = co_await socket.ReadSome(buffer, sizeof(buffer));
}
}
int main() {
TSelect poller;
task(poller);
while (true) { poller.Poll(); }
}We start a coroutine (or coroutines) that enters sleep mode on co_await, and control is then passed to an infinite loop that invokes the poller mechanism. If a socket becomes ready within the poller, the corresponding coroutine is triggered and executed until the next co_await.
To read and write Raft messages, I needed to create high-level wrappers over ReadSome/WriteSome, similar to:
TValueTask<T> Read() {
T res; size_t size = sizeof(T);
char* p = reinterpret_cast<char*>(&res);
while (size != 0) {
auto readSize = co_await Socket.ReadSome(p, size);
p += readSize;
size -= readSize;
}
co_return res;
}
// usage
T t = co_await Read<T>();To implement these, I needed to create a coroutine that also functions as an Awaitable. The coroutine is made up of a pair: coroutine_handle and promise. The coroutine_handle is used to manage the coroutine from the outside, whereas the promise is for internal management. The coroutine_handle can include Awaitable methods, which allow the coroutine's result to be awaited with co_await. The promise can be used to store the result returned by co_return and to awaken the calling coroutine.
In coroutine_handle, within the await_suspend method, we store the coroutine_handle of the calling coroutine. Its value will be saved in the promise:
template<typename T>
struct TValueTask : std::coroutine_handle<> {
bool await_ready() { return !!this->promise().Value; }
void await_suspend(std::coroutine_handle<> caller) {
this->promise().Caller = caller;
}
T await_resume() { return *this->promise().Value; }
using promise_type = TValuePromise<T>;
};Within the promise itself, the return_value method will store the returned value. The calling coroutine is woken up with an awaitable, which is returned in final_suspend. This is because the compiler, after co_return, invokes co_await on final_suspend.
template<typename T>
struct TValuePromise {
void return_value(const T& t) { Value = t; }
std::suspend_never initial_suspend() { return {}; }
// resume Caller here
TFinalSuspendContinuation<T> final_suspend() noexcept;
std::optional<T> Value;
std::coroutine_handle<> Caller = std::noop_coroutine();
};In await_suspend, the calling coroutine can be returned, and it will be automatically awakened. It is important to note that the called coroutine will now be in a sleeping state, and its coroutine_handle must be destroyed with destroy to avoid a memory leak. This can be accomplished, for example, in the destructor of TValueTask.
template<typename T>
struct TFinalSuspendContinuation {
bool await_ready() noexcept { return false; }
std::coroutine_handle<> await_suspend(
std::coroutine_handle<TValuePromise<T>> h) noexcept
{
return h.promise().Caller;
}
void await_resume() noexcept { }
};With the library description completed, I ported the libevent benchmark to it to ensure its performance. This benchmark generates a chain of N Unix pipes, each one linked to the next. It then initiates 100 write operations into the chain, which continues until there are 1000 total write calls. The image below depicts the benchmark's runtime as a function of N for various backends of my library (coroio) versus libevent. This test demonstrates that my library performs similarly to libevent, confirming its efficiency and effectiveness in managing I/O operations.

Conclusion
In closing, this article has described the implementation of a Raft server using C++20 coroutines, emphasizing the convenience and efficiency provided by this modern C++ feature. The custom I/O library, which was written from scratch, is critical to this implementation because it effectively handles asynchronous I/O operations. The performance of the library was validated against the libevent benchmark, demonstrating its competency.
For those interested in learning more about or using these tools, the I/O library is available at coroio, and the Raft library at miniraft-cpp (linked at the beginning of the article). Both repositories provide a detailed look at how C++20 coroutines can be used to build robust, high-performance distributed systems.
Opinions expressed by DZone contributors are their own.
Comments