Hybrid Search: A New Frontier in Enterprise Search
Discover how hybrid search, with its exceptional search capabilities, can deliver relevant results with utmost accuracy for a better search experience.
Join the DZone community and get the full member experience.
Join For FreeIn the business landscape, information is crucial for an organization. Not only this but finding the right information at the right time is even more important.
This is where enterprise search comes in handy. Earlier traditional enterprise search engines fell short in understanding the context of user queries. These search engines used keyword matching to find results. Post that, vector search became the next promising solution that considered the context of the user query, providing more relevant results.
Now with the advancement in technology, more efficient search solutions are developed that have taken search experience to the next level. One such solution is “hybrid search."
With the power of keyword search and vector-based semantic search, this new search has unlocked a whole new level of information retrieval. The combination of both of these technologies, hybrid search can provide more accurate, relevant, and meaningful results.
Let’s learn more about hybrid search and how it is capable of improving your search relevancy.
Sparse and Dense Representations
Hybrid search uses both sparse and dense vectors. With the help of these vectors, it improves keyword accuracy while understanding the semantic meaning and context of user search queries. Let’s get a clear idea of both these vectors:
Sparse Representation
In this, documents and queries are represented as sparse vectors. Sparse vectors are mainly used in traditional keyword-based searches and mostly have zero values with a few non-zero values.
The main focus of these vectors is to match the exact keywords. It uses the TF-IDF (term frequency-inverse document frequency) ranking technique to rank the search results based on their relevance. The embeddings of these vectors are generated using algorithms like BM25 and SPLADE.
BM25
This algorithm is particularly used for ranking of the relevant documents. It is built on TF-IDF and balances between term frequency, document length, and query relevance. It can be easily applied to the document collection without any labeled data. During ranking it takes into consideration, term occurrences, term frequency, and document frequency.
The disadvantage of this algorithm is that it is unable to identify the synonyms; i.e. if different terms are used in a query and a document, the information retrieval for the same will not be possible.
Components of BM25
- Term Frequency: TF determines the number of times a term appears in the document. In BM25 it is in a more refined form to rank the documents efficiently based on relevance. Earlier, the more a term appeared in the document, the more its relevance to the search query. But in BM25, this was replaced by a “Saturation Function," which segregated the results in a way that the more a term appears in a document, the less it contributes to the relevance of the search query.
![Term Frequency formula]()
- Inverse Document Frequency: IDF is nothing but determining how rare a term is in the document collection. The main purpose of IDF is to give importance to terms that are rarely used in the documents. Thus, it helps to identify terms that are more relevant to user search queries. The formula for IDF is as shown below:
![Inverse Document Frequency formula]()
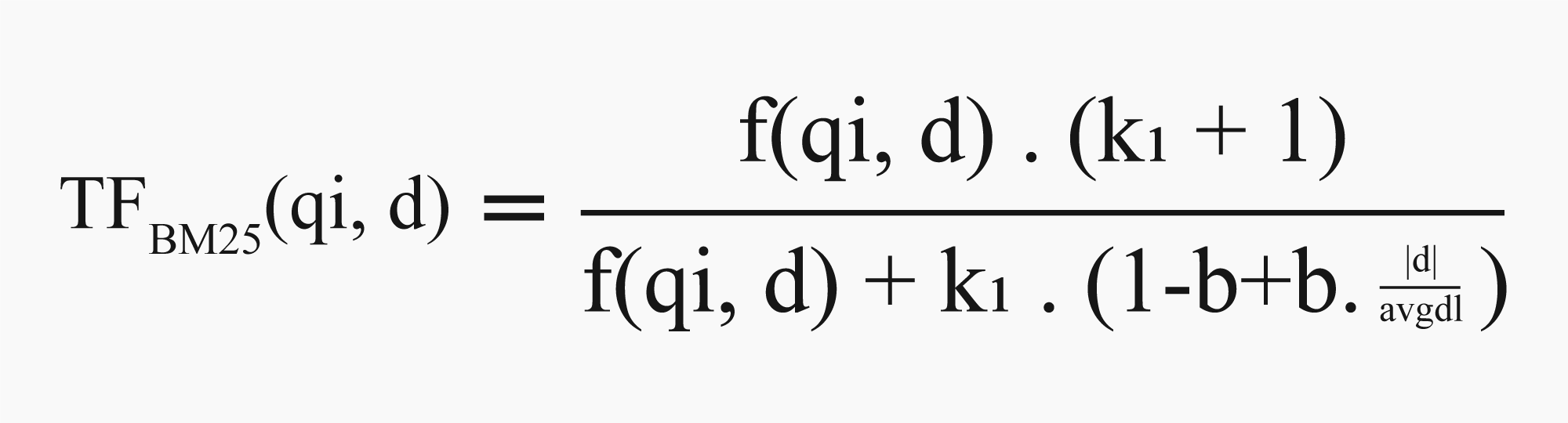
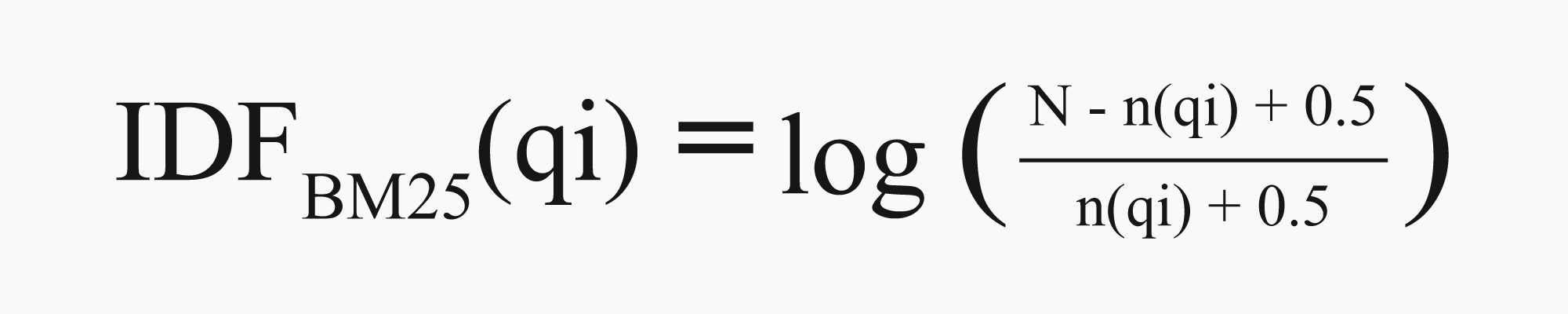
Dense Representation
This is done by representing the information stored in the database (including text images and other types of data) in the form of dense vectors. These vectors have mostly non-zero values and are packed with a lot of information. These are used in a semantic search to understand the context and meaning of this search query.
In other words, we can say it is useful for concept-based search. Some examples of the models that are used for this are Word2Vec, BERT, and ColBERT.
The vector embeddings are stored in the vector database and the distance between vectors is calculated. This distance gives an idea of how similar or dissimilar vectors are from each other. Thereby leading to an effective information retrieval based on the context and meaning behind a search query.
Let’s now understand the ColBERT model for dense vector embeddings:
ColBERT stands for contextualized late interaction over BERT and is a retrieval and ranking model. It is built on BERT (a top-performing transformer-based model) to make the information retrieval highly relevant. It was introduced to address the limitations of certain retrieval methods like bi-encoder and BM25; thus, striking a balance between contextual understanding of dense vector embeddings and efficient search.
Key Components of ColBERT
- Contextualized embeddings: Using BERT, ColBERT generates contextual embeddings for queries and documents. These embeddings then capture the meaning of individual words and how they relate to other words. Thus, it helps ColBERT to undergo information retrieval by understanding the semantic meaning of words rather than just normal keyword matching. These contextual embeddings are used for individual terms which helps ColBERT to analyze fine-grind relationships between terms making information retrieval more efficient.
- Late interaction: This method is based on the core concept of the “Late interaction” mechanism that sets it apart from other dense retrieval methods.
In traditional methods, queries and documents were compressed into single dense vectors in the early stages which led to the loss of detailed term-level information.
This mechanism overcomes this limitation by delaying the compression to later in the information retrieval process for a fine-grained comparison between terms of both query and document. This leads to improved accuracy and relevancy of the search results.
- Efficiency via Indexing: The indexing scheme of ColBERT is such that it makes information retrieval faster. It breaks down the document representations into smaller dense vectors for each term. Thus, making it feasible to manage large documents while leveraging dense vectors. Thus, we can say that ColBERT method has enhanced the hybrid search by improving the search relevance and scalability, making it suitable for enterprise search applications.
Conclusion
From the above, we can conclude that hybrid search with its advanced features and technologies can take the search experience to its next level.
With its ability to leverage BM25 for keyword matching and ColBERT for semantic understanding, it will make search engines more efficient. Thus, addressing the limitations of traditional search engines.
Hybrid search is a promising solution that can make the knowledge discovery process much more efficient thereby, assisting in informed decision-making. We can say that it has set up a benchmark in the enterprise search landscape.
Opinions expressed by DZone contributors are their own.
Comments