HtmlUnit vs JSoup: HTML Parsing in Java
Join the DZone community and get the full member experience.
Join For Freein continuation of my earlier blog jsoup: nice way to do html parsing in java, in this blog i will compare jsoup with other similar framework, htmlunit . apparently both of them are good html parsing frameworks and both can be used for web application unit testing and web scraping. in this blog, i will explain how htmlunit is better suited for web application unit testing automation and jsoup is better suited for web scraping.
typically web application unit testing automation is a way to automate webtesting in junit framework. and web scraping is a way to extract unstructured information from the web to a structured format. i recently tried 2 decent web scraping tools, webharvy and mozenda .
for any good html parsing tools to click, they should support either xpath based or css selector based element access. there are lot of blogs comparing each one like, why css locators are the way to go vs xpath , and css selectors and xpath expressions .
htmlunit
htmlunit is a powerful framework, where you can simulate pretty much anything a browser can do like click events, submit events etc and is ideal for web application automated unit testing.
xpath based parsing is simple and most popular and htmlunit is heavily based on this. in one of my application, i wanted to extract information from the web in a structured way. htmlunit worked out very well for me on this. but the problem starts when you try to extract structured data from modern web applications that use jquery and other ajax features and use div tags extensively. htmlunit and other xpath based html parsers will not work with this. there is also a jsoup version that supports xpath based on jaxe n, i tried this as well, guess what? it also was not able to access the data from modern web applications like ebay.com.
finally my experience with htmlunit was it was bit buggy or maybe i call it unforgiving unlike a browser, where in if the target web applications have missing javascripts, it will throw exceptions, but we can get around this, but out of the box it will not work.
jsoup
the latest version of jsoup goes extra length not to support xpath and will very well support css selectors . my experience was it is excellent for extracting structured data from modern web applications. it is also far forgiving if the web application has some missing javascripts.
extracting xpath and css selector data
in most of the browsers, if you point to an element and right click and click on “inspect element” it can extract the xpath information, i noticed firefox/firebug can also extract css selector path as shown below,
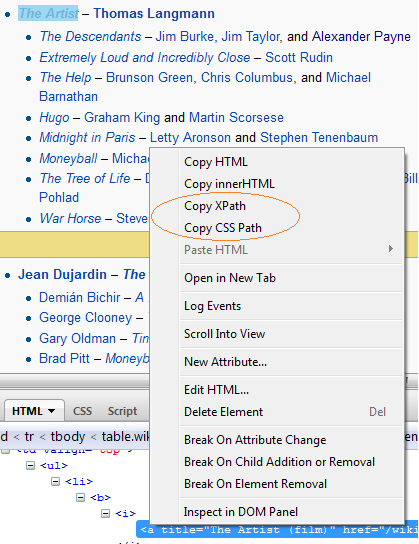
htmlunit vs jsoup: extract css path and xpath in firebug
i hope this blog helped.
Published at DZone with permission of Krishna Prasad, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments