How We Optimized Read Performance: Readahead, Prefetch, and Cache
In this in-depth analysis, take a deep dive into how JuiceFS enhances read performance using readahead, prefetch, and cache.
Join the DZone community and get the full member experience.
Join For FreeHigh-performance computing systems often use all-flash architectures and kernel-mode parallel file systems to satisfy performance demands. However, the increasing sizes of both data volumes and distributed system clusters raise significant cost challenges for all-flash storage and vast operational challenges for kernel clients.
JuiceFS is a cloud-native distributed file system that operates entirely in user space. It improves I/O throughput substantially through the distributed cache and uses cost-effective object storage for data storage. It’s hence suitable for serving large-scale AI workloads.
In JuiceFS, reading data starts with a client-side read request, which is sent to the JuiceFS client via FUSE. This request then passes through a readahead buffer layer, enters the cache layer, and ultimately accesses object storage. To enhance reading efficiency, we employ various strategies in the architecture, including data readahead, prefetch, and cache.
In this article, we’ll analyze the working principles of these strategies in detail and share our test results in specific scenarios. We hope this article will provide insights for improving your system performance.
JuiceFS Architecture Introduction
The architecture of JuiceFS Community Edition consists of three main parts in total, known as client, data storage, and metadata. Data access is supported through various interfaces, including POSIX, HDFS API, S3 API, and Kubernetes CSI, catering to different application scenarios. In terms of data storage, JuiceFS supports dozens of object storage solutions, including public cloud services and self-hosted solutions such as Ceph and MinIO. The metadata engine works with major databases such as Redis, TiKV, and PostgreSQL.
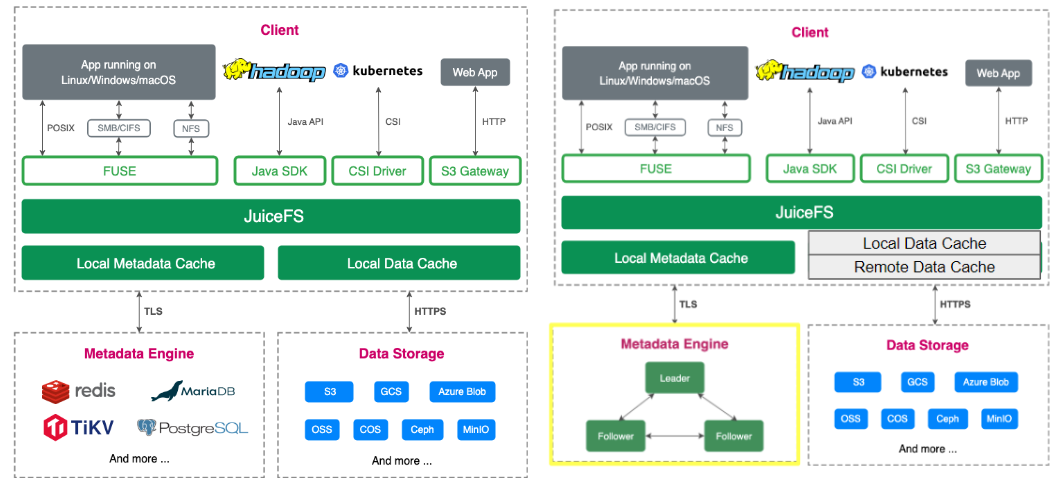
Architecture: JuiceFS Community Edition (left) vs. Enterprise Edition (right)
The primary differences between the community edition and the enterprise edition are in handling the metadata engine and data caching, as shown in the figure above. Specifically, the enterprise edition includes a proprietary distributed metadata engine and supports distributed cache, whereas the community edition only supports local cache.
Concepts of Reads in Linux
There are many ways to read data in the Linux system:
- Buffered I/O: It’s the standard method to read files. Data passes through the kernel buffer, and the kernel executes readahead operations to make reads more efficient.
- Direct I/O: Bypassing the kernel buffer, this technique enables file I/O operations. This lowers memory utilization and data copying. Large data transfers are appropriate for it.
- Asynchronous I/O: Frequently employed in conjunction with direct I/O, this technique enables programs to send out several I/O requests on a single thread without having to wait for each request to finish. This improves I/O concurrency performance.
- Memory map: This technique uses pointers to map files into the address space of the process, enabling immediate access to file content. With memory mapping, applications can access the mapped file area as if it were regular memory, with the kernel automatically handling data reads and writes.
These reading modes bring specific challenges to storage systems:
- Random reads: Including both random large I/O reads and random small I/O reads, these primarily test the storage system's latency and IOPS.
- Sequential reads: These primarily test the storage system's bandwidth.
- Reading a large number of small files: This tests the performance of the storage system's metadata engine and the overall system's IOPS capabilities.
JuiceFS Read Process Analysis
We employ a strategy of file chunking. A file is logically divided into several chunks, each with a fixed size of 64 MB. Each chunk is further subdivided into 4 MB blocks, which are the actual storage units in the object storage. Many performance optimization measures in JuiceFS are closely related to this chunking strategy. Learn more about the JuiceFS storage workflow.
To optimize read performance, we implement several techniques such as readahead, prefetch, and cache.
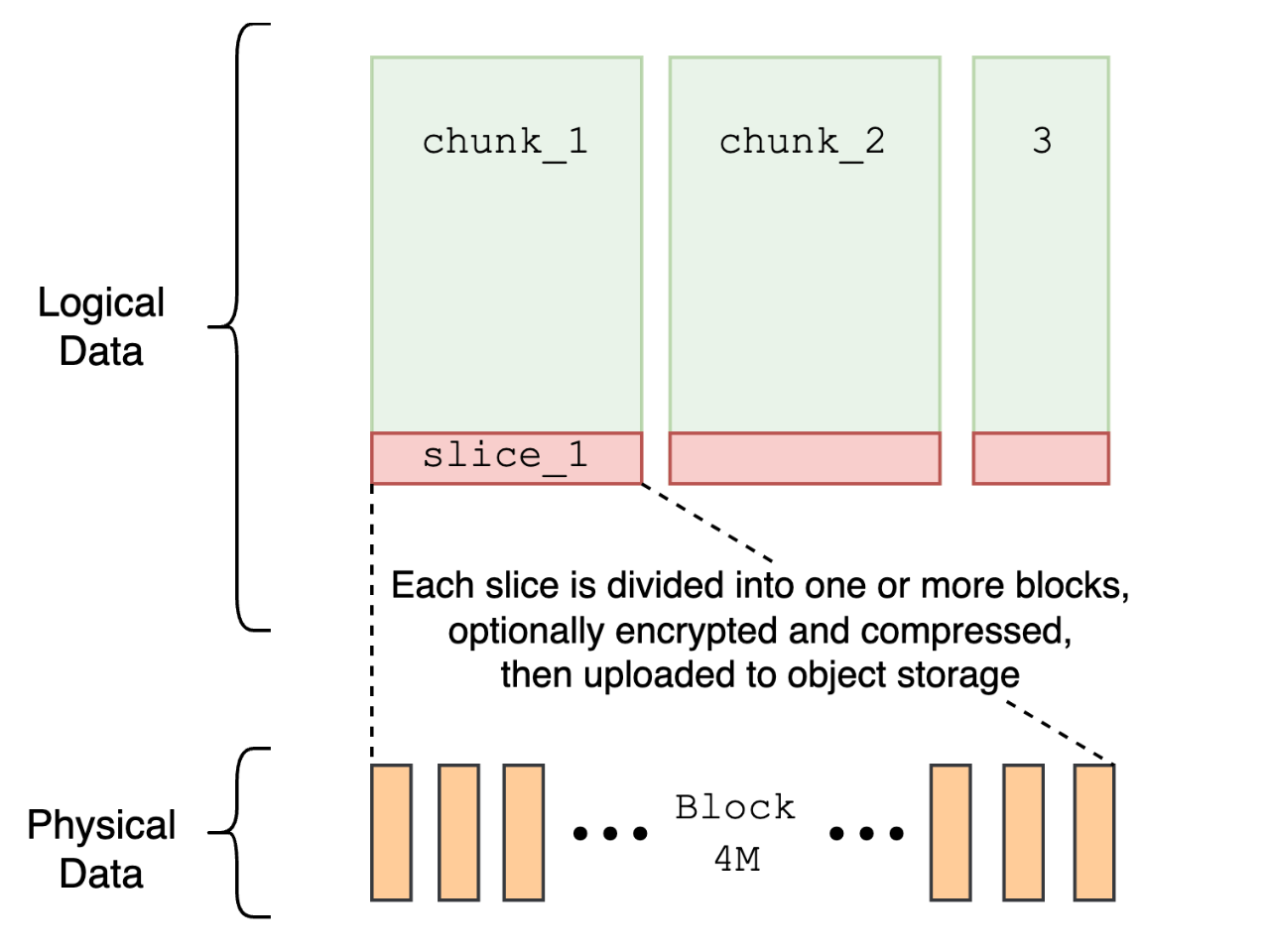
JuiceFS data storage
Readahead
Readahead is a technique that anticipates future read requests and preloads data from the object storage into memory. It reduces access latency and improves actual I/O concurrency. The figure below shows the read process in a simplified way. The area below the dashed line represents the application layer, while the area above it represents the kernel layer.
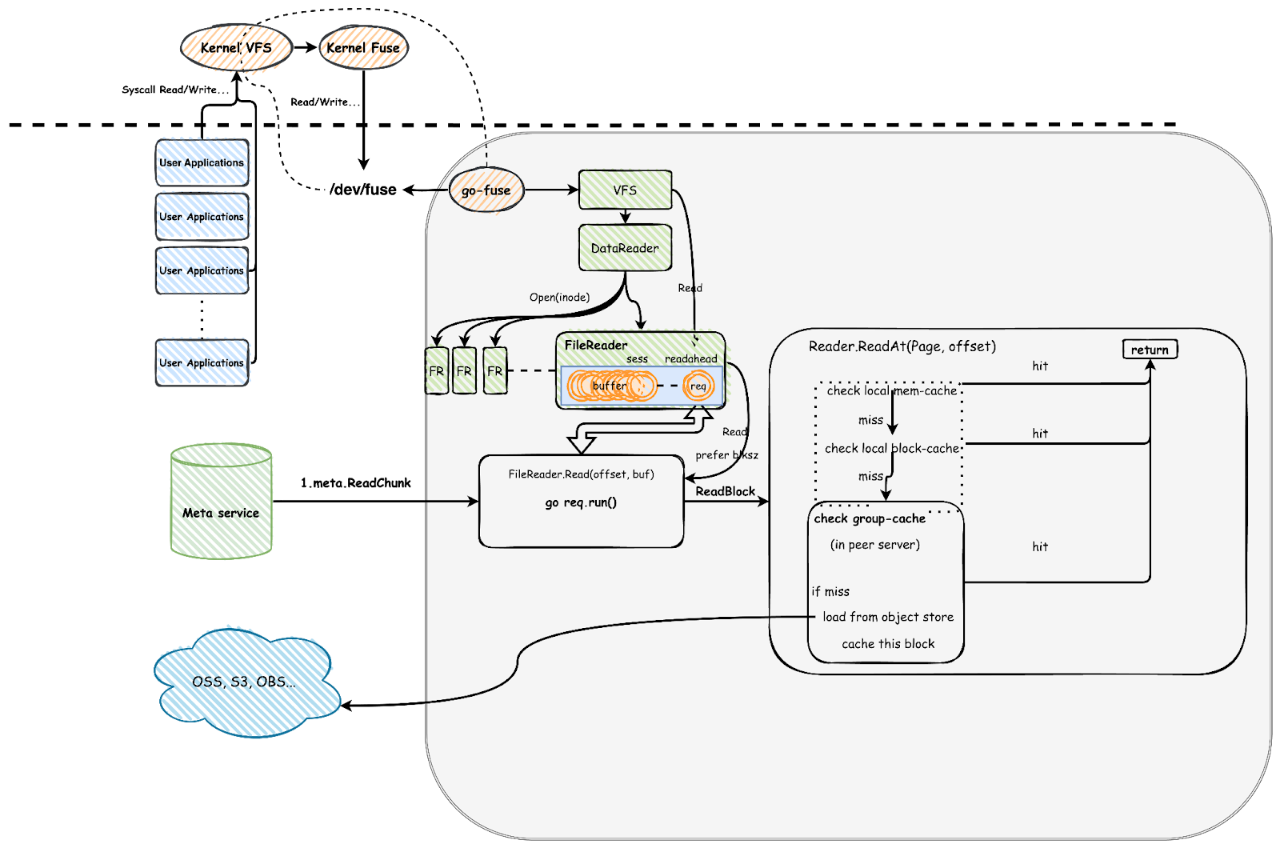
JuiceFS data reading workflow
When a user process (the application layer marked in blue in the lower left corner) initiates a system call for file reading and writing, the request first passes through the kernel's virtual file system (VFS), then to the kernel's FUSE module. It communicates with the JuiceFS client process via the /dev/fuse device.
The process illustrated in the lower right corner demonstrates the subsequent readahead optimization within JuiceFS. The system introduces sessions to track a series of sequential reads. Each session records the last read offset, the length of sequential reads, and the current readahead window size. This information helps determine if a new read request hits this session and automatically adjusts or moves the readahead window. By maintaining multiple sessions, JuiceFS can efficiently support high-performance concurrent sequential reads.
To enhance the performance of sequential reads, we introduced measures to increase concurrency in the system design. Each block (4 MB) in the readahead window initiates a goroutine to read data. It’s important to note that concurrency is limited by the buffer-size parameter. With a default setting of 300 MB, the theoretical maximum concurrency for object storage is 75 (300 MB divided by 4 MB). This setting may not suffice for some high-performance scenarios, and users need to adjust this parameter according to their resource configuration and specific requirements. We have tested different parameter settings in subsequent content.
For example, as shown in the second row of the figure below, when the system receives a second sequential read request, it actually initiates a request that includes the readahead window and three consecutive data blocks. According to the readahead settings, the next two requests will directly hit the readahead buffer and be returned immediately.
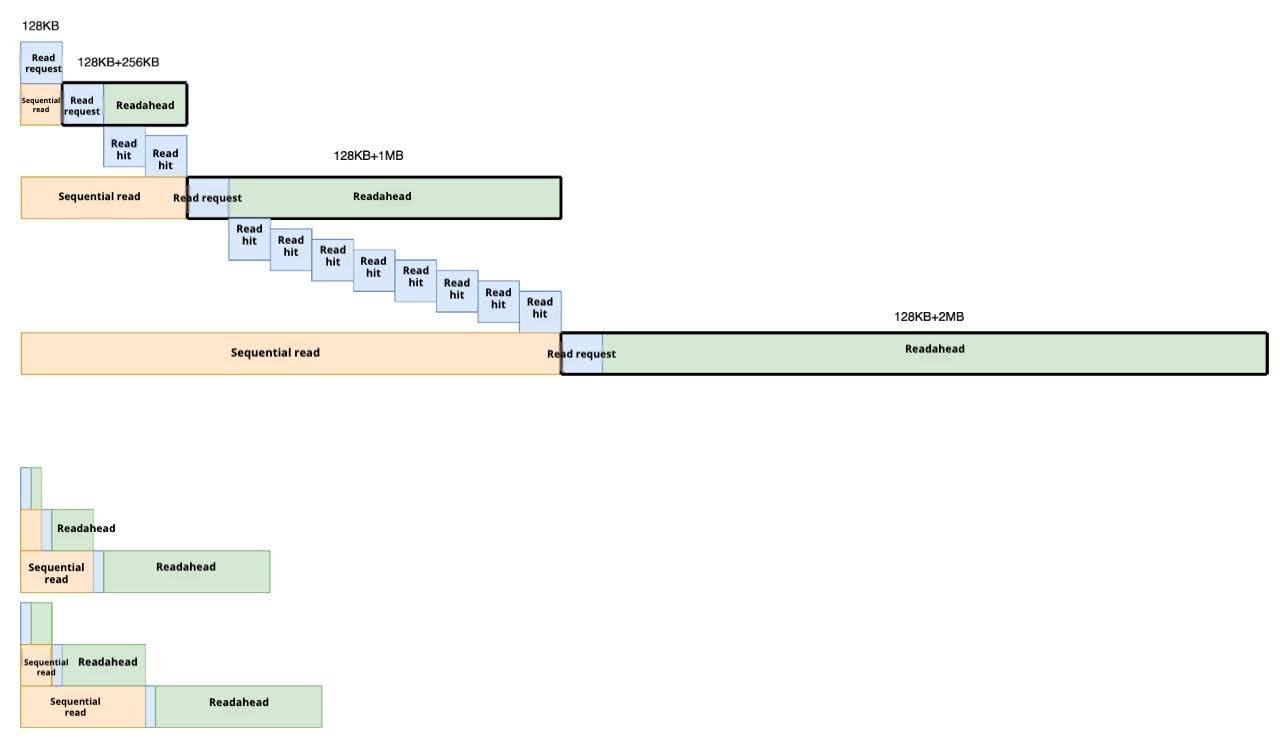
A simplified example of JuiceFS readahead mechanism
If the first and second requests do not use readahead and directly access object storage, the latency will be high (usually greater than 10 ms). When the latency drops to within 100 microseconds, it indicates that the I/O request successfully used readahead. This means the third and fourth requests directly hit the data preloaded into memory.
Prefetch
Prefetching occurs when a small segment of data is read randomly from a file. We assume that the nearby region might also be read soon. Therefore, the client asynchronously downloads the entire block containing that small data segment.
However, in some scenarios, prefetching might be unsuitable. For example, if the application performs large, sparse, random reads on a large file, prefetching might access unnecessary data, causing read amplification. Therefore, if users already understand their application's read patterns and determine that prefetching is unnecessary, they can disable it using --prefetch=0.
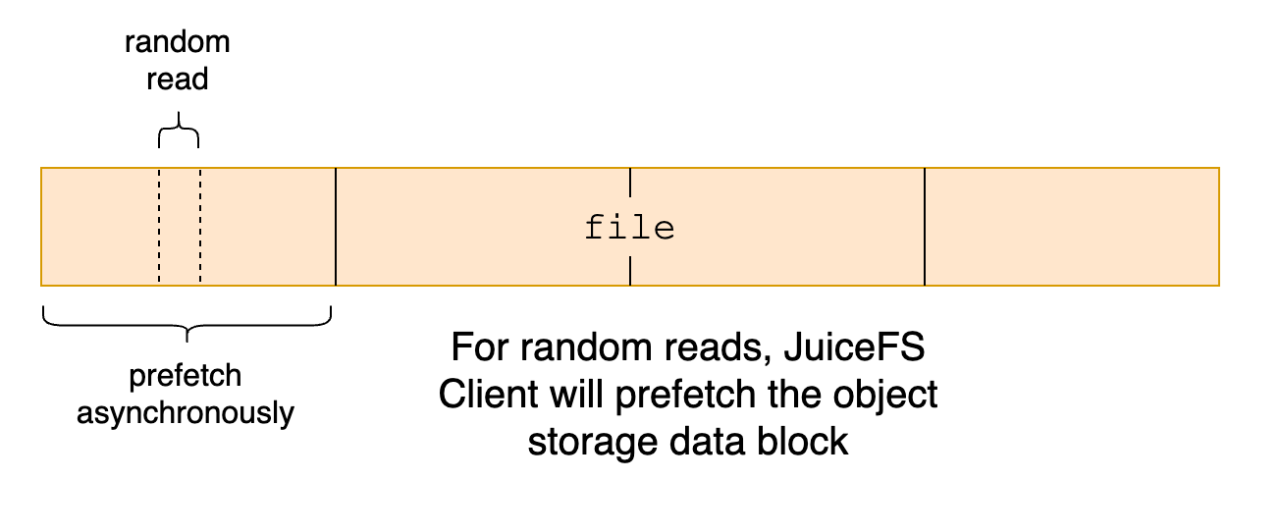
JuiceFS prefetch workflow
Cache
You can learn about the JuiceFS cache in this document. This article will focus on the basic concepts of cache.
Page Cache
The page cache is a mechanism provided by the Linux kernel. One of its core functionalities is readahead. It preloads data into the cache to ensure quick response times when the data is actually requested.
The page cache is particularly crucial in certain scenarios, such as when handling random read operations. If users strategically use the page cache to pre-fill file data, such as reading an entire file into the cache when memory is free, subsequent random read performance can be significantly improved. This can enhance overall application performance.
Local Cache
JuiceFS local cache can store blocks in local memory or on local disks. This enables local hits when applications access this data, reduces network latency, and improves performance. High-performance SSDs are typically recommended for local cache. The default unit of data cache is a block, 4 MB in size. It’s asynchronously written to the local cache after it’s initially read from object storage.
For configuration details on the local cache, such as --cache-dir and --cache-size, enterprise users can refer to the Data cache document.
Distributed Cache
Unlike local cache, the distributed cache aggregates the local caches of multiple nodes into a single cache pool, thereby increasing the cache hit rate. However, distributed cache introduces an additional network request. This results in slightly higher latency compared to local cache. The typical random read latency for distributed cache is 1-2 ms; for local cache, it’s 0.2-0.5 ms. For the details of the distributed cache architecture, see Distributed cache.
FUSE and Object Storage Performance
JuiceFS's read requests all go through FUSE, and the data must be read from object storage. Therefore, understanding the performance of FUSE and object storage is the basis for understanding the performance of JuiceFS.
FUSE Performance
We conducted two sets of tests on FUSE performance. The test scenario was that after the I/O request reached the FUSE mount process, the data was filled directly into the memory and returned immediately. The test mainly evaluated the total bandwidth of FUSE under different numbers of threads, the average bandwidth of a single thread, and the CPU usage. In terms of hardware, test 1 is Intel Xeon architecture and test 2 is AMD EPYC architecture.
The table below shows the test results of FUSE performance test 1, based on Intel Xeon CPU architecture:
| Threads | Bandwidth (GiB/s) | Bandwidth per Thread (GiB/s) | CPU usage (cores) |
|---|---|---|---|
|
1 |
7.95 |
7.95 |
0.9 |
|
2 |
15.4 |
7.7 |
1.8 |
|
3 |
20.9 |
6.9 |
2.7 |
|
4 |
27.6 |
6.9 |
3.6 |
|
6 |
43 |
7.2 |
5.3 |
|
8 |
55 |
6.9 |
7.1 |
|
10 |
69.6 |
6.96 |
8.6 |
|
15 |
90 |
6 |
13.6 |
|
20 |
104 |
5.2 |
18 |
|
25 |
102 |
4.08 |
22.6 |
|
30 |
98.5 |
3.28 |
27.4 |
The table shows that:
- In the single-threaded test, the maximum bandwidth reached 7.95 GiB/s while using less than one core of CPU.
- As the number of threads grew, the bandwidth increased almost linearly. When the number of threads grew to 20, the total bandwidth increased to 104 GiB/s.
Here, users need to pay special attention to the fact that the FUSE bandwidth performance measured using different hardware types and different operating systems under the same CPU architecture may be different. We tested using multiple hardware types, and the maximum single-thread bandwidth measured on one was only 3.9 GiB/s.
The table below shows the test results of FUSE performance test 2, based on AMD EPYC CPU architecture:
|
Threads |
Bandwidth (GiB/s) |
Bandwidth per thread (GiB/s) |
CPU usage (cores) |
|---|---|---|---|
|
1 |
3.5 |
3.5 |
1 |
|
2 |
6.3 |
3.15 |
1.9 |
|
3 |
9.5 |
3.16 |
2.8 |
|
4 |
9.7 |
2.43 |
3.8 |
|
6 |
14.0 |
2.33 |
5.7 |
|
8 |
17.0 |
2.13 |
7.6 |
|
10 |
18.6 |
1.9 |
9.4 |
|
15 |
21 |
1.4 |
13.7 |
In test 2, the bandwidth did not scale linearly. Especially when the number of concurrencies reached 10, the bandwidth per concurrency was less than 2 GiB/s.
Under multi-concurrency conditions, the peak bandwidth of test 2 (EPYC architecture) was about 20 GiBps, while test 1 (Intel Xeon architecture) showed higher performance. The peak value usually occurred after the CPU resources were fully occupied. At this time, both the application process and the FUSE process reached the CPU resource limit.
In actual applications, due to the time overhead in each stage, the actual I/O performance is often lower than the above-mentioned test peak of 3.5 GiB/s. For example, in the model loading scenario, when loading model files in pickle format, usually the single-thread bandwidth can only reach 1.5 to 1.8 GiB/s. This is mainly because when reading the pickle file, data deserialization is required, and there will be a bottleneck of CPU single-core processing. Even when reading directly from memory without going through FUSE, the bandwidth can only reach up to 2.8 GiB/s.
Object Storage Performance
We used the juicefs objbench tool for testing object storage performance, covering different loads of single concurrency, 10 concurrency, 200 concurrency, and 800 concurrency. It should be noted that the performance gap between different object stores may be large.
|
Load |
Upload objects (MiB/s) |
Download objects (MiB/s) |
Average upload time (ms/object) |
Average download time (ms/object) |
|---|---|---|---|---|
|
Single concurrency |
32.89 |
40.46 |
121.63 |
98.85 |
|
10 concurrency |
332.75 |
364.82 |
10.02 |
10.96 |
|
200 concurrency |
5,590.26 |
3,551.65 |
067 |
1.13 |
|
800 concurrency |
8,270.28 |
4,038.41 |
0.48 |
0.99 |
When we increased the concurrency of GET operations on object storage to 200 and 800, we could achieve very high bandwidth. This indicates that the bandwidth for single concurrency is very limited when reading data directly from object storage. Increasing concurrency is crucial for overall bandwidth performance.
Sequential Read and Random Read Tests
To provide a clear benchmark reference, we used the fio tool to test the performance of JuiceFS Enterprise Edition in sequential and random read scenarios.
Sequential Read
As shown in the figure below, 99% of the data had a latency of less than 200 microseconds. In sequential read scenarios, the readahead window performed very well, resulting in low latency.
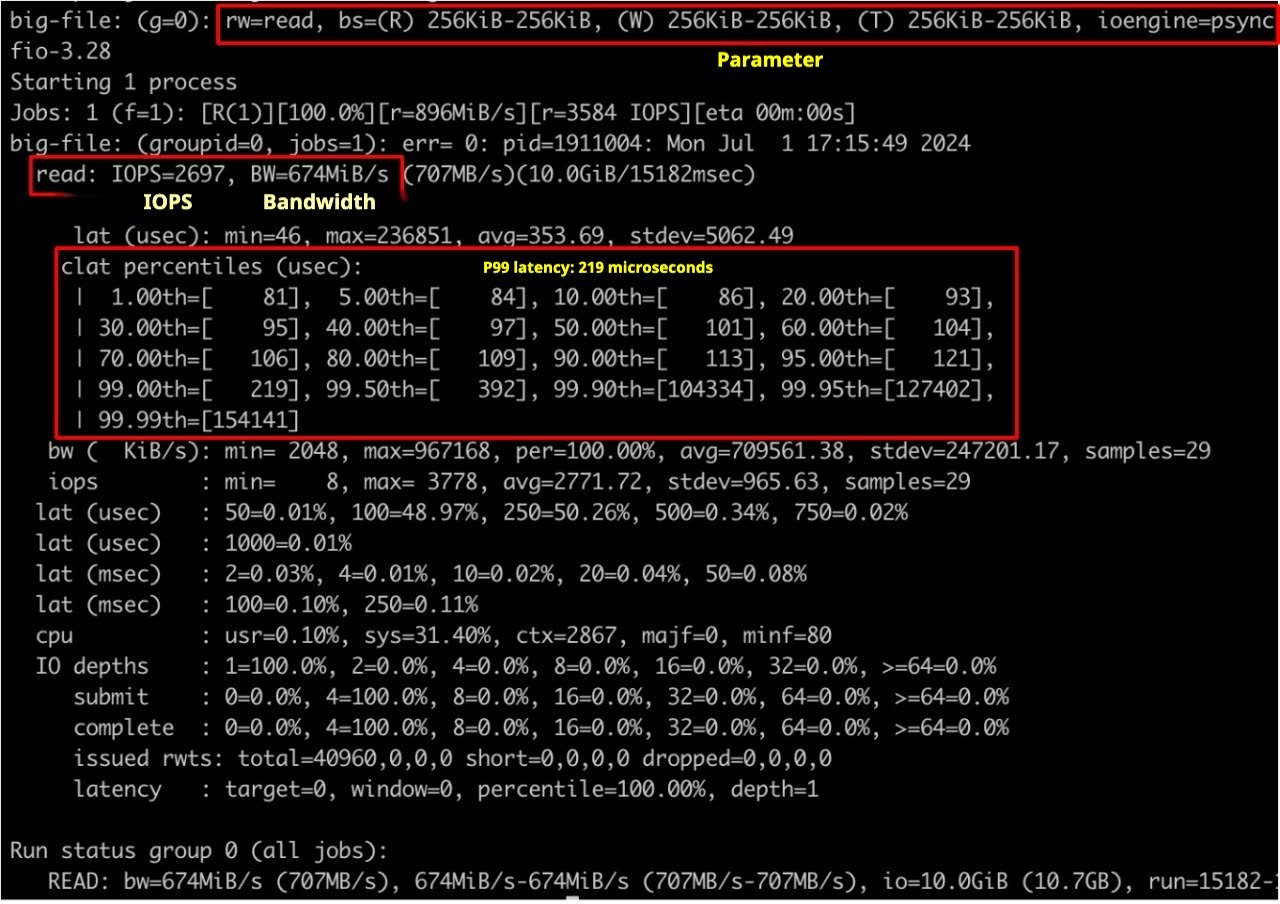 Sequential read
Sequential read
By default, buffer-size=300 MiB, a sequential reading of 10 GB from object storage.
By increasing the readahead window, we improved I/O concurrency and thus increased bandwidth. When we adjusted buffer-size from the default 300 MiB to 2 GiB, the read concurrency was no longer limited, and the read bandwidth increased from 674 MiB/s to 1,418 MiB/s. It reached the performance peak of single-threaded FUSE. To further increase bandwidth, it’s necessary to increase the I/O concurrency in the application code.
The table below shows the performance test results of different buffer sizes (single thread):
| buffer-size | Bandwidth |
|---|---|
|
300 MiB |
674 MiB/s |
|
2 GiB |
1,418 MiB/s |
When the number of application threads increased to 4, the bandwidth reached 3,456 MiB/s. For 16 threads, the bandwidth reached 5,457 MiB/s. At this point, the network bandwidth was already saturated.
The table below shows the bandwidth performance test results of different thread counts (buffer-size: 2 GiB):
| buffer-size | bandwidth |
|---|---|
|
1 thread |
1,418 MiB/s |
|
4 threads |
3,456 MiB/s |
|
16 threads |
5,457 MiB/s |
Random Read
For small I/O random reads, performance is mainly determined by latency and IOPS. Since total IOPS can be linearly scaled by adding nodes, we first focus on latency data on a single node.
- FUSE data bandwidth refers to the amount of data transmitted through the FUSE layer. It represents the data transfer rate observable and operable by user applications.
- Underlying data bandwidth refers to the bandwidth of the storage system that processes data at the physical layer or operating system level.
As shown in the table below, compared to penetrating object storage, latency was lower when hitting local cache and distributed cache. When optimizing random read latency, it's crucial to consider improving data cache hit rates. In addition, using asynchronous I/O interfaces and increasing thread counts can significantly improve IOPS.
The table below shows the test results of JuiceFS small I/O random reads:
| Category | Latency | IOPS | FUSE data bandwidth | |
|---|---|---|---|---|
|
Small I/O random read 128 KB (synchronous read) |
Hitting local cache |
0.1-0.2 ms |
5,245 |
656 MiB/s |
|
Hitting distributed cache |
0.3-0.6 ms |
1,795 |
224 MiB/s |
|
|
Penetrating object storage |
50-100 ms |
16 |
2.04 MiB/s |
|
|
Small I/O random read 4 KB (synchronous read) |
Hitting local cache |
0.05-0.1 ms |
14.7k |
57.4 MiB/s |
|
Hitting distributed cache |
0.1-0.2 ms |
6,893 |
26.9 MiB/s |
|
|
Penetrating object storage |
30-55 ms |
25 |
102 KiB/s |
|
|
Small I/O random read 4 KB (libaio iodepth=64) |
Hitting local cache |
- |
30.8k |
120 MiB/s |
|
Hitting distributed cache |
- |
32.3k |
126 MiB/s |
|
|
Penetrating object storage |
- |
1,530 |
6,122 KiB/s |
|
|
Small I/O random read 4 KB (libaio iodepth=64) 4 concurrency |
Hitting local cache |
- |
116k |
450 MiB/s |
|
Hitting distributed cache |
- |
90.5k |
340 MiB/s |
|
|
Penetrating object storage |
- |
5.4k |
21.5 MiB/s |
Unlike small I/O scenarios, large I/O random read scenarios must also consider the read amplification issue. As shown in the table below, the underlying data bandwidth was higher than the FUSE data bandwidth due to readahead effects. Actual data requests may be 1-3 times more than application data requests. In this case, you can disable prefetch and adjust the maximum readahead window for tuning.
The table below shows the test results of JuiceFS large I/O random reads, with distributed cache enabled:
| Category | FUSE data bandwidth | Underlying Data bandwidth |
|---|---|---|
|
1 MB buffered I/O |
92 MiB |
290 MiB |
|
2 MB buffered I/O |
155 MiB |
435 MiB |
|
4 MB buffered I/O |
181 MiB |
575 MiB |
|
1 MB direct I/O |
306 MiB |
306 MiB |
|
2 MB direct I/O |
199 MiB |
340 MiB |
|
4 MB direct I/O |
245 MiB |
735 MiB |
Conclusion
This article provided our strategies for optimizing the reading performance of JuiceFS. It has covered readahead, prefetch, and cache. JuiceFS lowers latency and increases I/O throughput by putting these strategies into practice.
We have shown through detailed benchmarks and analysis how various configurations affect system performance. If you are doing sequential reads or random I/Os, knowing about and tuning these mechanisms can be useful in improving your systems’ read performance.
Published at DZone with permission of Edric Mo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments