How To Use SingleStore Pipelines With Kafka, Part 3 of 3
This series of articles looks at the SingleStore feature called Pipelines. Today, learn how to replace the Consumer part of a Producer-Consumer with a SingleStore Pipeline.
Join the DZone community and get the full member experience.
Join For FreeAbstract
This article is the third and final part of our Pipelines series. We'll look at replacing the Consumer part of our Producer-Consumer application by using a compelling feature of SingleStore, called Pipelines.
The SQL scripts, Java code, and notebook files used in this article series are available on GitHub. The notebook files are available in DBC, HTML, and iPython formats.
Introduction
This is a three-part article series, and it is structured as follows:
- Load the Sensor data into SingleStore.
- Demonstrate Producer-Consumer using Java and JDBC.
- Demonstrate SingleStore Pipelines.
This third article covers Part 3, Demonstrate SingleStore Pipelines.
SingleStore Pipelines
Pipelines allow us to create streaming ingest feeds from various sources, such as Apache Kafka™, Amazon S3, and HDFS, using a single command. With Pipelines, we can perform ETL operations:
- Extract. Pull data from various sources without the need for additional middleware.
- Transform. Map and enrich data using transformations.
- Load. Guarantee message delivery and eliminate duplicates.
Visually, Figure 1 shows our SingleStore Pipelines architecture.
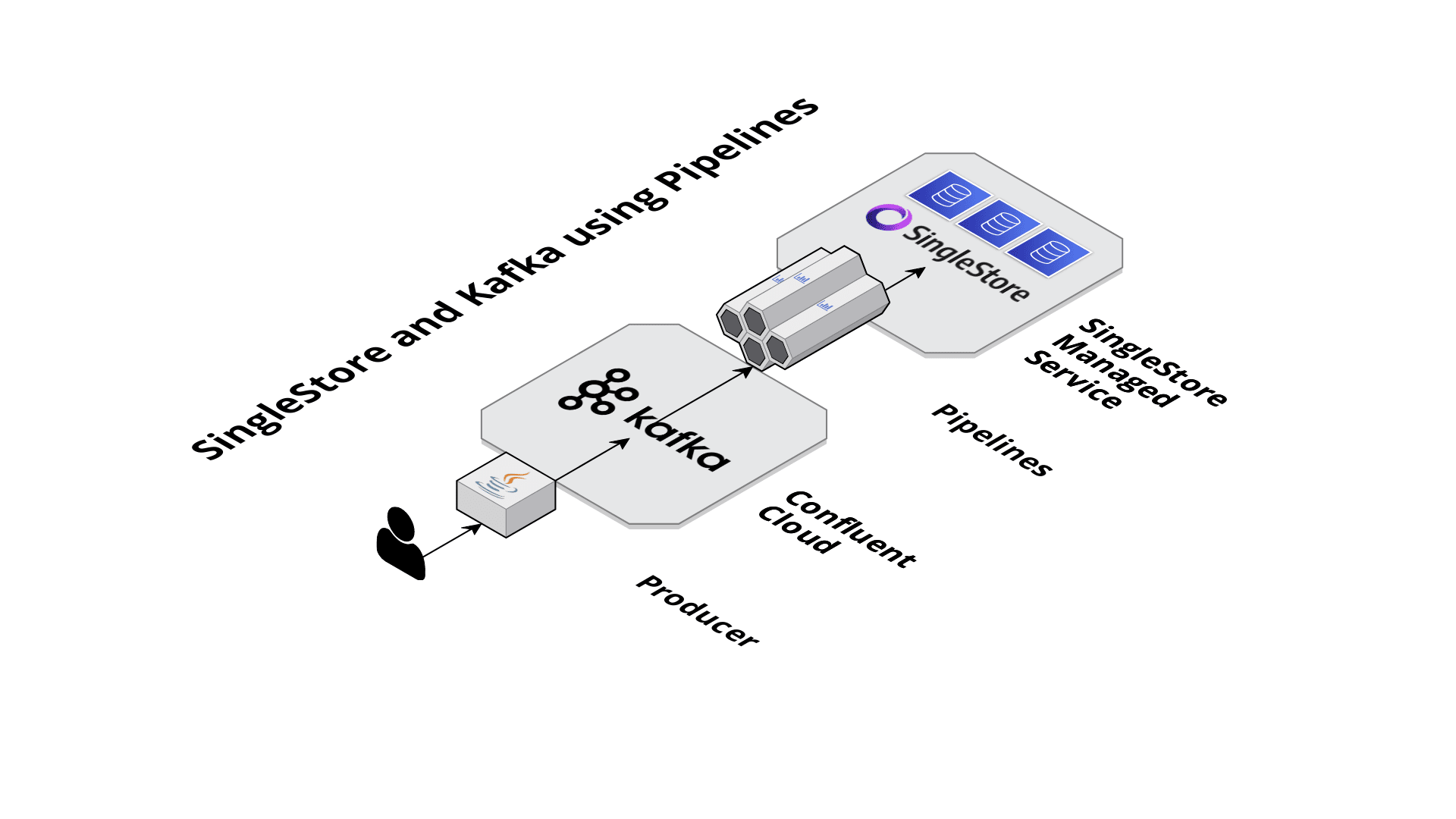
Figure 1. SingleStore and Kafka using Pipelines.
For our use case, we can create a simple Pipeline in SingleStore as follows:
USE sensor_readings;
CREATE PIPELINE IF NOT EXISTS kafka_confluent_cloud AS
LOAD DATA KAFKA '{{ BROKER_ENDPOINT }}/temp'
CONFIG '{
"security.protocol" : "SASL_SSL",
"sasl.mechanism" : "PLAIN",
"sasl.username" : "{{ CLUSTER_API_KEY }}"}'
CREDENTIALS '{
"sasl.password" : "{{ CLUSTER_API_SECRET }}"}'
SKIP DUPLICATE KEY ERRORS
INTO TABLE temperatures
FORMAT CSV
FIELDS TERMINATED BY ',';We need to add values for {{ BROKER_ENDPOINT }} , {{ CLUSTER_API_KEY }} and {{ CLUSTER_API_SECRET }}. We covered how to find these in the previous article in this series.
We specify the temp topic name on line 2 of the Pipeline code. We also specify that we are using CSV format and that the comma character separates the fields.
Next, we need to start the Pipeline. This can be done as follows:
START PIPELINE kafka_confluent_cloud;We can check the Pipeline using:
SHOW PIPELINES;The Pipeline we defined and started will ingest the message data directly from Confluent Cloud into our SingleStore database. As we can see, the architecture has been simplified compared to the approach using JDBC.
Example Queries
Now that we have built our system, we can start to ask queries, such as finding sensors where the temperature reading is within a specific range:
USE sensor_readings;
SELECT sensorid, COUNT(*)
FROM temperatures
WHERE temp > 70 AND temp < 100
GROUP BY sensorid
ORDER BY sensorid;Or within the particular latitude and longitude coordinates:
USE sensor_readings;
SELECT MAX(temp) AS max_temp, sensorid
FROM temperatures AS t
JOIN sensors AS s ON t.sensorid = s.id
WHERE s.latitude >= 24.7433195 AND s.latitude <= 49.3457868 AND
s.longitude >= -124.7844079 AND s.longitude <= -66.9513812
GROUP BY sensorid
ORDER BY max_temp DESC;We can also use the geospatial features of SingleStore to find the landmasses where sensors are located:
USE sensor_readings;
SELECT continents.name AS continent, sensors.name AS sensor_name
FROM continents
JOIN sensors
ON GEOGRAPHY_CONTAINS(continents.geo, sensors.location)
ORDER BY continents.name, sensors.name;Summary
Pipelines are a compelling feature of SingleStore. We have only implemented a small example but have immediately realized the benefits of a simplified architecture. The key benefits of Pipelines include:
- Rapid parallel loading of data into a database.
- Live de-duplication for real-time data cleansing.
- Simplified architecture that eliminates the need for additional middleware.
- Extensible plugin framework that allows customizations.
- Exactly once semantics, critical for enterprise data.
More details about Pipelines can be found on the SingleStore Documentation website.
Published at DZone with permission of Akmal Chaudhri. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments