How To Use Shadow Testing To Reduce the Risk of Production Issues
Shadow Testing minimizes risks during system changes, safeguarding users without difficulty, thanks to various testing tools.
Join the DZone community and get the full member experience.
Join For FreeNumerous tactics exist for mitigating the potential dangers that come along with shipping fresh modifications in a system. Practices such as automated testing, feature toggles, canary releases, and blue-green deployments are among the more commonly referenced methodologies that can assist in achieving this aim. However, I would like to bring your attention to a less frequently discussed approach known as Shadow Testing.
Shadow Testing is a special technique in which we duplicate the traffic for a particular software component that is subject to change and execute both the current and the [new] modified component. The idea is to compare the results from both components to detect disparities that could cause problems in production without affecting the users in production, so only the results from the current component are used to serve the users. See the diagram below illustrating how this works:
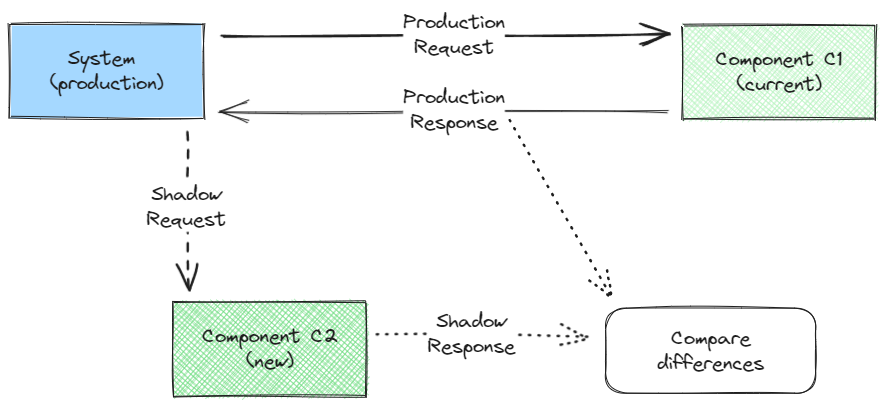
As we can see, regular production traffic is unaffected and continues to go through C1 (solid lines), but a duplicated request is sent to the new component (C2) in order to compare the results between C1 and C2. This can be applied to either simpler use cases like a new internal function/endpoint implementation and complex ones like system migrations. Before going deeper into the theme, it’s also worth mentioning that it can also be referred to as Shadow Deployment or Dark Launch, although these terms are used mostly when referring to applying DevOps in system-wide changes.
Applications
What is Shadow Testing used for? Its application is very broad, going from the lowest to the highest levels of a system. Generally, it works best when applied to something that processes or enhances existing user interactions rather than something that directly requires user input.
In the lower level, some of the examples where it can be applied are on backend migrations, testing the performance of a new [sub-]system of updating a particular [micro]service. In these instances, our aim isn't merely to assess the functional outcomes but also to ensure that the newly integrated component is capable of managing real-time production traffic. This is done by evaluating factors like server load, throughput, and response time.
As we go to the higher levels, some of the examples are switching to an external provider for a particular service, upgrading internal features, and even small features. At this point, our focus may shift towards verifying its performance under real-world traffic conditions. However, our concern is less about detailed metrics at this stage and more about ensuring that the newly introduced component does not exhibit a functional regression compared to its predecessor.
Benefits
As we’ve already mentioned, the main goal of Shadow Testing is to reduce the risks when rolling out new systems or updating components in an existing system. But how does it aid in achieving this goal? First, let's explore the broad advantages that Shadow Testing might offer for our releases. Following that, we'll look at some more specific examples.
Real-Life Scale
Replicating the scale of production traffic to validate a new system can be very challenging. This may not be a problem for smaller systems with fairly limited traffic, but as traffic grows and systems get more complex, this will sooner or later become a problem. Make no mistake. It remains vital to execute performance tests and prepare our systems as much as we can for deployment in a live environment. When it comes to launching it, though, Shadow Testing is a good way to provide full production scale to the new or modified system before it starts actually affecting what users see or interact with.
Real-Life Data
Let’s be honest: No automated tests (like stress, integration, or end-to-end tests) will be able to mirror production traffic perfectly. As much as we’d like to improve the simulation, the complexity of covering all the users’ behavior grows exponentially, and at some point, the effort to mimic production is not exactly worth the added benefit. Yes, automated tests are a very good practice, and I’ll be the first to recommend them, yet it's crucial to recognize their limitations. Even executing the best stress tests doesn’t exactly guarantee a stress-free (pun intended) deployment.
One solution to this problem that I’ve seen in the past is dumping production databases into staging environments and using an anonymization process to protect user privacy. This gets us much closer to real-life data, as it provides information somewhat similar to production, and, best of all, data is distributed in the DB tables in a sensible way. This solution, however, is still not real-life data.
Let me give an example where this would be problematic: let’s assume we’re working with a banking system, with all its complexity, and want to launch a new consolidation job to replace the legacy one. Of course, we want to make sure the consolidation works before launching it, so we test it with an anonymized production dump. However, as the data itself is what’s more relevant to validate the new job, we have an impasse: A simpler anonymization process will likely cause the job to fail in unrealistic scenarios, as the transaction numbers may have become inconsistent, making the job validation at least incomplete. Fixing this would require a more complex anonymization process that carefully keeps all data consistent, but this could have a very high implementation cost, which may not be worth it.
Here’s where Shadow Testing could be a good solution — it allows us to test real-life scenarios with real-life data. In our example, we could allow the consolidation job to run reading production data and then compare the outcomes with the existing production job.
Real-Life Scenarios
We’ve implicitly touched on this in the previous two topics, but it’s worth making it more explicit: with Shadow Testing, because we are leveraging production scale and production data, we don’t have to rely on specific test scenarios. Don’t get me wrong: I believe good test scenarios (automated or not) are fundamental to certify that the system adheres to the most important requirements and expectations. Usually, though, they only cover the “happy path” plus a few of the most common edge cases.
I’m sure we’ve all seen the memes about how users interact with our products in unexpected ways, and jokes aside, that’s very true. Production, where real users interact with our system, is the only environment where we can more exhaustively cover these unusual scenarios. There’s nothing better than real-life scenarios to make sure the new system or component is prepared for full deployment, and Shadow Testing is definitely a good strategy to make this happen.
No Impact on Real-Life Users
This benefit is actually part of the definition itself, but it’s still worth exploring how this fits in the software development life cycle. It’s a known process to validate the changes, fix, and update the version before it’s rolled out to production, but the real challenge begins when the changes are rolled out to serve the production traffic. What happens if any issue is identified after this point? The most common options would be to land a fix, disable the feature with a feature flag (or feature toggle), or potentially even roll back the deployment.
The biggest problem here is that real users were already affected by the issue, even if for a small period. For smaller issues, this may not be a big thing, but what if it’s something critical? Let's go back to our bank example and imagine that the consolidation had a rounding error in the calculations. This could result in a money loss of millions, right? That’s without mentioning the institution's image, sues, and so on.
I don’t want to sound too dramatic, and most systems are probably not as sensitive as a bank. However, it’s important to be aware that before the issue happens and is investigated, we cannot predict its potential impact. Therefore, Shadow Testing serves as an effective safeguard, particularly for more significant changes.
It Can Be Fairly Easy to Apply
In a wide range of use cases, implementing Shadow Testing can be quite straightforward. There are many tools (some are listed at the end) to help in the lower-level examples, and it gets easier as we go into higher-level engineering.
Let’s use a very silly example (changing a sum function) to illustrate how a high-level implementation could be applied in a code:
result = CurrentMathLib.sum(a, b);
resultToCompare = NewMathLib.sum(a, b);
ShadowTesting.logResults('sum', result, resultToCompare);
return result;There are basically four things happening here:
- The current sum function is called, and the result is stored
- The candidate sum function is called, and the result is stored
- Both results are logged
- The current sum result is returned
Steps 1 and 4 are what we already have in production. Let’s focus on the other two, beginning with logging the results.
ShadowTesting.logResults('sum', result, resultToCompare);There are countless ways to log and compare these results. One very simple approach might involve having them as records in a Database, having an identifier and both results. One could improve this with a timestamp, storing the comparison result instead of the raw results, and so on. But as we can see, the bare minimum would be there, and querying the results is very easy. Also worth mentioning is that if the scale of these writes is a concern, this logic could be easily sampled and still be statistically significant.
Now, let’s move back to the step we skipped:
resultToCompare = NewMathLib.sum(a, b);Here, we’re calling the new function, which is the target of the Shadow Testing, and storing its value for comparison. This looks harmless, but what if the function breaks or if its performance is unexpectedly bad? It would also impact production and potentially affect the users, right? Ideally, we want to isolate this in a protected run (like a try/catch), and also, we want to be able to disable this feature if anything that actually impacts production is detected. A more well-protected code, for example, could look like this:
public Number a(...) {
// ...
result = CurrentMathLib.sum(a, b);
compareSum(result, a, b);
return result;
}
private Number compareSum(Number result, Number a, Number b) {
if (!FeatureFlag.isEnabled('new_sum'))
return;
try {
resultToCompare = NewMathLib.sum(a, b);
ShadowTesting.logResults('sum', result, resultToCompare);
}
catch (Exception e) {
Logger.error(' ... ', e);
}
}Now, we have a slightly better example, but it’s important to remember that unless the feature is disabled, it will now be running in production and could still bring some impact. There are many other improvements one could make (for example, parallel execution of both function calls to cut out the time waiting for the second call), and each system has different tooling and infrastructure available to execute them. In lower-level implementations, it's likely we'll need additional infrastructure and machine capacity to operate entirely new systems, and the implementation might not occur at the application level.
A key point to remember is that no strategy is flawless. In Shadow Testing, for example, there’s a tradeoff between server capacity and how much we can afford to have errors in the component or system being updated.
Tools
There are many different ways to implement Shadow Testing. At higher levels, it’s probably worth investing a small effort to create a library that is tailored to the particular system/codebase we’re working with. At lower levels, it may already be supported by the DevOps tools in use, but if that’s not the case, I’m listing here a few tools (with no special recommendation or order) that could serve as a good starting point.
Opinions expressed by DZone contributors are their own.
Comments