How To Use Retrieval Augmented Generation (RAG) for Go Applications
In this article, learn how to implement RAG (using LangChain and PostgreSQL) to improve the accuracy and relevance of LLM outputs.
Join the DZone community and get the full member experience.
Join For FreeGenerative AI development has been democratized, thanks to powerful Machine Learning models (specifically Large Language Models such as Claude, Meta's LLama 2, etc.) being exposed by managed platforms/services as API calls. This frees developers from the infrastructure concerns and lets them focus on the core business problems. This also means that developers are free to use the programming language best suited for their solution. Python has typically been the go-to language when it comes to AI/ML solutions, but there is more flexibility in this area.
In this post, you will see how to leverage the Go programming language to use Vector Databases and techniques such as Retrieval Augmented Generation (RAG) with langchaingo. If you are a Go developer who wants to how to build and learn generative AI applications, you are in the right place!
If you are looking for introductory content on using Go for AI/ML, feel free to check out my previous blogs and open-source projects in this space.
First, let's take a step back and get some context before diving into the hands-on part of this post.
The Limitations of LLMs
Large Language Models (LLMs) and other foundation models have been trained on a large corpus of data enabling them to perform well at many natural language processing (NLP) tasks. But one of the most important limitations is that most foundation models and LLMs use a static dataset which often has a specific knowledge cut-off (say, January 2022).
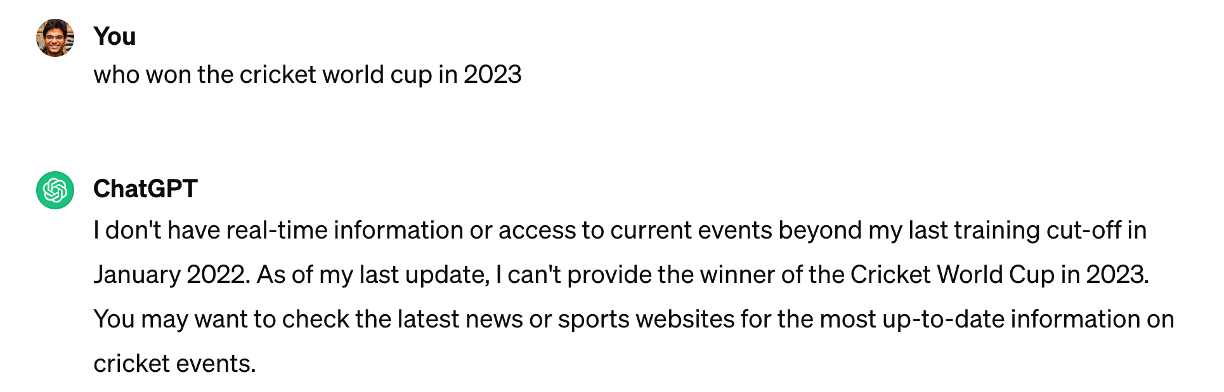
For example, if you were to ask about an event that took place after the cut-off, date it would either fail to answer it (which is fine) or worse, confidently reply with an incorrect response — this is often referred to as Hallucination.
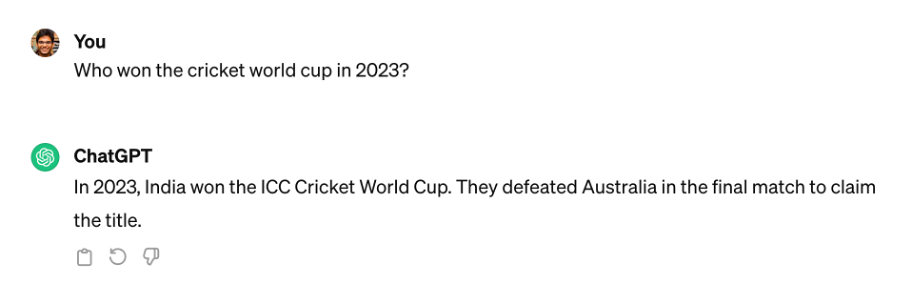
We need to consider the fact that LLMs only respond based on the data they were trained on - it limits their ability to accurately answer questions on topics that are either specialized or proprietary. For instance, if I were to ask a question about a specific AWS service, the LLM may (or may not) be able to come up with an accurate response. Wouldn't it be nice if the LLM could use the official AWS service documentation as a reference?
RAG (Retrieval Augmented Generation) Helps Alleviate These Issues
It enhances LLMs by dynamically retrieving external information during the response generation process, thereby expanding the model's knowledge base beyond its original training data. RAG-based solutions incorporate a vector store which can be indexed and queried to retrieve the most recent and relevant information, thereby extending the LLM's knowledge beyond its training cut-off. When an LLM equipped with RAG needs to generate a response, it first queries a vector store to find relevant, up-to-date information related to the query. This process ensures that the model's outputs are not just based on its pre-existing knowledge but are augmented with the latest information, thereby improving the accuracy and relevance of its responses.
But, RAG Is Not the Only Way
Although this post focuses solely on RAG, there are other ways to work around this problem, each with its pros and cons:
- Task-specific tuning: Fine-tuning large language models on specific tasks or datasets to improve their performance in those domains.
- Prompt engineering: Carefully designing input prompts to guide language models towards desired outputs, without requiring significant architectural changes.
- Few-shot and zero-shot learning: Techniques that enable language models to adapt to new tasks with limited or no additional training data.
Vector Store and Embeddings
I mentioned vector store a few times in the last paragraph. These are nothing but databases that store and index vector embeddings, which are numerical representations of data such as text, images, or entities. Embeddings help us go beyond basic search since they represent the semantic meaning of the source data — hence the word Semantic search, which is a technique that understands the meaning and context of words to improve search accuracy and relevance. Vector databases can also store metadata, including references to the original data source (for example, the URL of a web document) of the embedding.
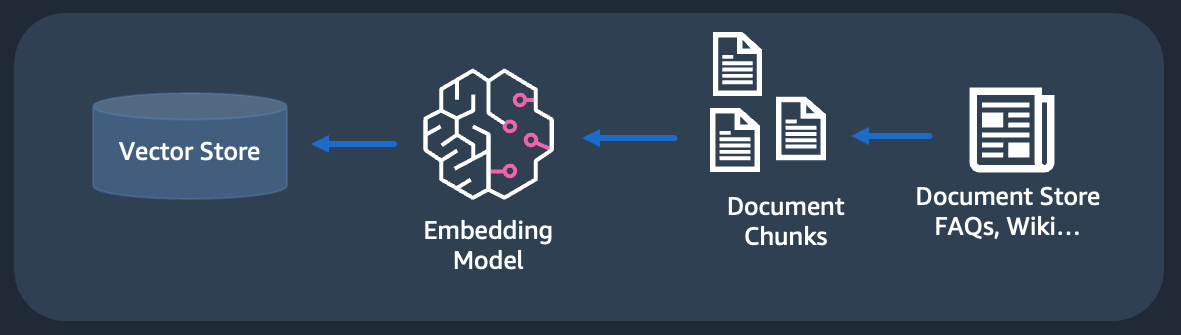
Thanks to generative AI technologies, there has also been an explosion in Vector Databases. These include established SQL and NoSQL databases that you may already be using in other parts of your architecture — such as PostgreSQL, Redis, MongoDB, and OpenSearch. But there are also databases that are custom-built for vector storage. Some of these include Pinecone, Milvus, Weaviate, etc.
Alright, let's go back to RAG...
What Does a Typical RAG Workflow Look Like?
At a high level, RAG-based solutions have the following workflow. These are often executed as a cohesive pipeline:
- Retrieving data from a variety of external sources like documents, images, web URLs, databases, proprietary data sources, etc. This consists of sub-steps such as chunking which involves splitting up large datasets (e.g. a 100 MB PDF file) into smaller parts (for indexing).
- Create embeddings: This involves using an embedding model to convert data into numerical representations.
- Store/Index embeddings in a vector store
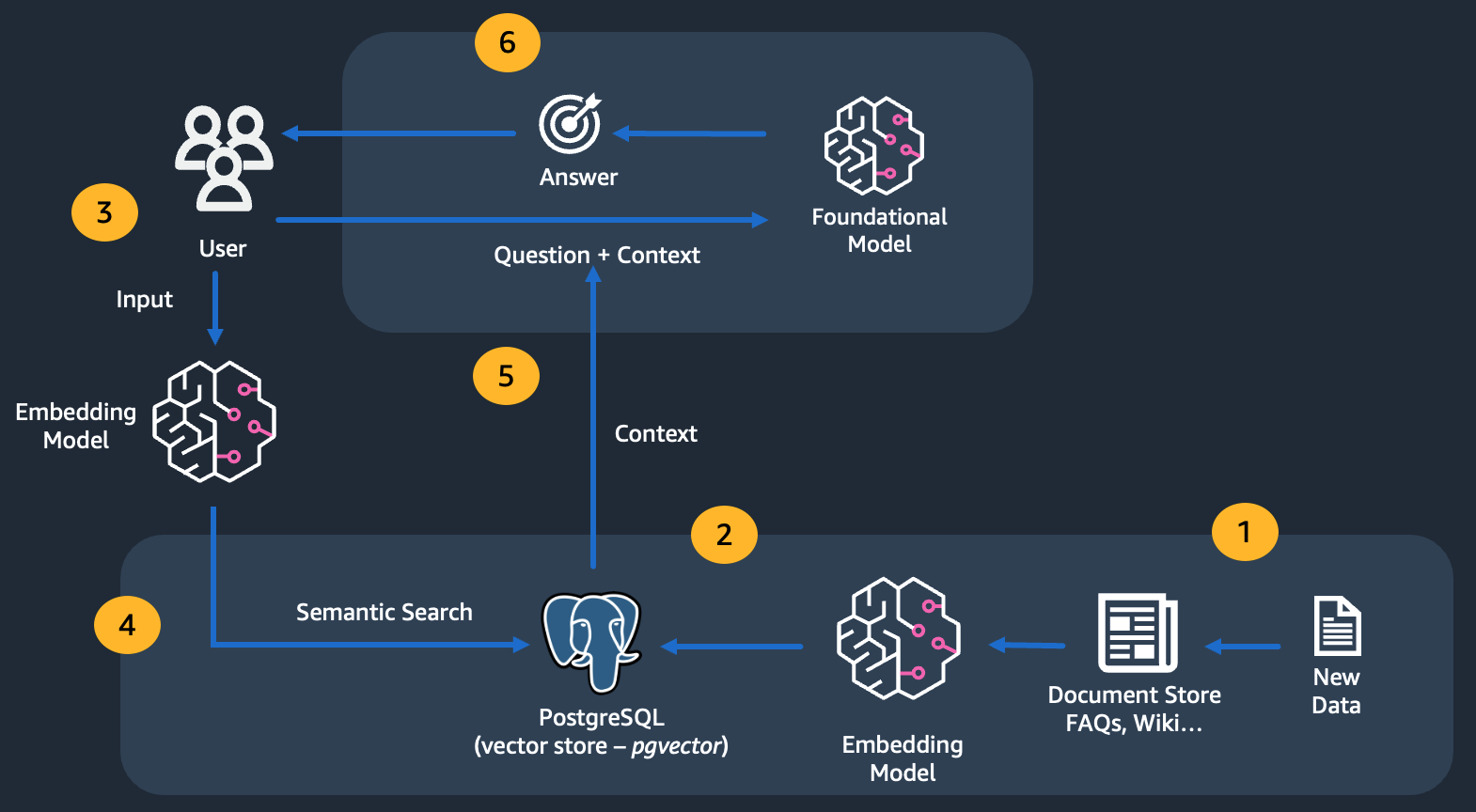
Ultimately, this is integration as part of a larger application where the contextual data (semantic search result) is provided to LLMs (along with the prompts).
End-To-End RAG Workflow in Action
Each of the workflow steps can be executed with different components. The ones used in the blog include:
- PostgreSQL: It will be used as a Vector Database, thanks to the pgvector extension. To keep things simple, we will run it in Docker.
- langchaingo: It is a Go port of the langchain framework. It provides plugins for various components, including vector store. We will use it for loading data from web URLs and indexing it in PostgreSQL.
- Text and embedding models: We will use Amazon Bedrock Claude and Titan models (for text and embedding respectively) with langchaingo.
- Retrieval and app integration: langchaingo vector store (for semantic search) and chain (for RAG).
You will get a sense of how these individual pieces work. We will cover other variants of this architecture in subsequent blogs.
Before You Begin
Make sure you have:
- Go, Docker and psql (for e.g., using Homebrew if you're on Mac) installed.
- Amazon Bedrock access configured from your local machine - Refer to this blog post for details.
Start PostgreSQL on Docker
There is a Docker image we can use!
docker run --name pgvector --rm -it -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres ankane/pgvector
Activate pgvector extension by logging into PostgreSQL (using psql) from a different terminal:
# enter postgres when prompted for password
psql -h localhost -U postgres -W
CREATE EXTENSION IF NOT EXISTS vector;
Load Data Into PostgreSQL (Vector Store)
Clone the project repository:
git clone https://github.com/build-on-aws/rag-golang-postgresql-langchain
cd rag-golang-postgresql-langchain
At this point, I am assuming that your local machine is configured to work with Amazon Bedrock
The first thing we will do is load data into PostgreSQL. In this case, we will use an existing web page as the source of information. I have used this developer guide — but feel free to use your own! Make sure to change the search query accordingly in the subsequent steps.
export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=load -source=https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-general-nosql-design.html
You should get the following output:
loading data from https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-general-nosql-design.html
vector store ready - postgres://postgres:postgres@localhost:5432/postgres?sslmode=disable
no. of documents to be loaded 23
Give it a few seconds. Finally, you should see this output if all goes well:
data successfully loaded into vector store
To verify, go back to the psql terminal and check the tables:
\d
You should see a couple of tables — langchain_pg_collection and langchain_pg_embedding. These are created by langchaingo since we did not specify them explicitly (that's ok, it's convenient for getting started!). langchain_pg_collection contains the collection name while langchain_pg_embedding stores the actual embeddings.
| Schema | Name | Type | Owner |
|--------|-------------------------|-------|----------|
| public | langchain_pg_collection | table | postgres |
| public | langchain_pg_embedding | table | postgres |
You can introspect the tables:
select * from langchain_pg_collection;
select count(*) from langchain_pg_embedding;
select collection_id, document, uuid from langchain_pg_embedding LIMIT 1;
You will see 23 rows in the langchain_pg_embedding table, since that was the number of langchain documents that our web page source was split into (refer to the application logs above when you loaded the data)
A quick detour into how this works...
The data loading implementation is in load.go, but let's look at how we access the vector store instance (in common.go):
brc := bedrockruntime.NewFromConfig(cfg)
embeddingModel, err := bedrock.NewBedrock(bedrock.WithClient(brc), bedrock.WithModel(bedrock.ModelTitanEmbedG1))
//...
store, err = pgvector.New(
context.Background(),
pgvector.WithConnectionURL(pgConnURL),
pgvector.WithEmbedder(embeddingModel),
)
pgvector.WithConnectionURLis where the connection information for PostgreSQL instance is providedpgvector.WithEmbedderis the interesting part, since this is where we can plug in the embedding model of our choice.langchaingosupports Amazon Bedrock embeddings. In this case I have used Amazon Bedrock Titan embedding model.
Back to the loading process in load.go. We first get the data in form of a slice of schema.Document (getDocs function) using the langchaingo in-built HTML loader for this.
docs, err := documentloaders.NewHTML(resp.Body).LoadAndSplit(context.Background(), textsplitter.NewRecursiveCharacter())
Then, we load it into PostgreSQL. Instead of writing everything by ourselves, we can use the langchaingo vector store abstraction and use the high-level function AddDocuments:
_, err = store.AddDocuments(context.Background(), docs)
Great. We have set up a simple pipeline to fetch and ingest data into PostgreSQL. Let's make use of it!
Execute Semantic Search
Let's ask a question. I am going with "What tools can I use to design dynamodb data models?" relevant to this document which I used as the data source — feel free to tune it as per your scenario.
export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=semantic_search -query="what tools can I use to design dynamodb data models?" -maxResults=3
You should see a similar output — note that we opted to output a maximum of three results (you can change it):
vector store ready
============== similarity search results ==============
similarity search info - can build new data models from, or design models based on, existing data models that satisfy
your application's data access patterns. You can also import and export the designed data
model at the end of the process. For more information, see Building data models with NoSQL Workbench
similarity search score - 0.3141409
============================
similarity search info - NoSQL Workbench for DynamoDB is a cross-platform, client-side GUI
application that you can use for modern database development and operations. It's available
for Windows, macOS, and Linux. NoSQL Workbench is a visual development tool that provides
data modeling, data visualization, sample data generation, and query development features to
help you design, create, query, and manage DynamoDB tables. With NoSQL Workbench for DynamoDB, you
similarity search score - 0.3186116
============================
similarity search info - key-value pairs or document storage. When you switch from a relational database management
system to a NoSQL database system like DynamoDB, it's important to understand the key differences
and specific design approaches.TopicsDifferences between relational data
design and NoSQLTwo key concepts for NoSQL designApproaching NoSQL designNoSQL Workbench for DynamoDB
Differences between relational data
design and NoSQL
similarity search score - 0.3275382
============================
Now what you see here are the top three results (thanks to -maxResults=3).
Note that this is not an answer to our question. These are the results from our vector store that are semantically close to the query — the keyword here is semantic. Thanks to the vector store abstraction in langchaingo, we were able to easily ingest our source data into PostgreSQL and use the SimilaritySearch function to get the top N results corresponding to our query (see semanticSearch function in query.go):
Note that (at the time of writing) the pgvector implementation in langchaingo uses cosine distance vector operation but pgvector also supports L2 and inner product - for details, refer to the pgvector documentation.
Ok, so far we have:
- Loaded vector data
- Executed semantic search
This is the stepping stone to RAG (Retrieval Augmented Generation) - let's see it in action!
Intelligent Search With RAG
To execute a RAG-based search, we run the same command as above (almost), only with a slight change in the action (rag_search):
export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=rag_search -query="what tools can I use to design dynamodb data models?" -maxResults=3
Here is the output I got (might be slightly different in your case):
Based on the context provided, the NoSQL Workbench for DynamoDB is a tool that can be used to design DynamoDB data models. Some key points about NoSQL Workbench for DynamoDB:
- It is a cross-platform GUI application available for Windows, macOS, and Linux.
- It provides data modeling capabilities to help design and create DynamoDB tables.
- It allows you to build new data models or design models based on existing data models.
- It provides features like data visualization, sample data generation, and query development to manage DynamoDB tables.
- It helps in understanding the key differences and design approaches when moving from a relational database to a NoSQL database like DynamoDB.
So in summary, NoSQL Workbench for DynamoDB seems to be a useful tool specifically designed for modeling and working with DynamoDB data models.
As you can see, the result is not just about "Here are the top X responses for your query." Instead, it's a well-formulated response to the question. Let's peek behind the scenes again to see how it works.
Unlike, ingestion and semantic search, RAG-based search is not directly exposed by the langchaingo vector store implementation. For this, we use a langchaingo chain which takes care of the following:
- Invokes semantic search
- Combines the semantic search with a prompt
- Sends it to a Large Language Model (LLM), which in this case happens to be Claude on Amazon Bedrock.
Here is what the chain looks like (refer to the function ragSearch in query.go):
result, err := chains.Run(
context.Background(),
chains.NewRetrievalQAFromLLM(
llm,
vectorstores.ToRetriever(store, numOfResults),
),
question,
chains.WithMaxTokens(2048),
)
Let’s Try Another One
This was just one example. I tried a different question and increased maxResults to 10, which means that the top 10 results from the vector database will be used to formulate the answer.
go run *.go -action=rag_search -query="how is NoSQL different from SQL?" -maxResults=10
The result (again, it might be different for you):
Based on the provided context, there are a few key differences between NoSQL databases like DynamoDB and relational database management systems (RDBMS):
1. Data Modeling:
- In RDBMS, data modeling is focused on flexibility and normalization without worrying much about performance implications. Query optimization doesn't significantly affect schema design.
- In NoSQL, data modeling is driven by the specific queries and access patterns required by the application. The data schema is designed to optimize the most common and important queries for speed and scalability.
2. Data Organization:
- RDBMS organizes data into tables with rows and columns, allowing flexible querying.
- NoSQL databases like DynamoDB use key-value pairs or document storage, where data is organized in a way that matches the queried data shape, improving query performance.
3. Query Patterns:
- In RDBMS, data can be queried flexibly, but queries can be relatively expensive and don't scale well for high-traffic situations.
- In NoSQL, data can be queried efficiently in a limited number of ways defined by the data model, while other queries may be expensive and slow.
4. Data Distribution:
- NoSQL databases like DynamoDB distribute data across partitions to scale horizontally, and the data keys are designed to evenly distribute the traffic across partitions, avoiding hot spots.
- The concept of "locality of reference," keeping related data together, is crucial for improving performance and reducing costs in NoSQL databases.
In summary, NoSQL databases prioritize specific query patterns and scalability over flexible querying, and the data modeling is tailored to these requirements, in contrast with RDBMS where data modeling focuses on normalization and flexibility.
Where to “Go” From Here?
Learning by doing is a good approach. If you've followed along and executed the application thus far, great!
I recommend you try out the following:
langchaingohas support for lots of different models, including ones in Amazon Bedrock (e.g. Meta LLama 2, Cohere, etc.) — try tweaking the model and see if it makes a difference. Is the output better?- What about the Vector Database? I demonstrated PostgreSQL, but
langchaingosupports others as well (including OpenSearch, Chroma, etc.) - Try swapping out the Vector store and see how/if the search results differ. - You probably get the gist, but you can also try out different embedding models. We used Amazon Titan, but
langchaingoalso supports many others, including Cohere embed models in Amazon Bedrock.
Wrap Up
This was a simple example for you to better understand the individual steps in building RAG-based solutions. These might change a bit depending on the implementation, but the high-level ideas remain the same.
I used langchaingo as the framework. But this doesn't always mean you have to use one. You could also remove the abstractions and call the LLM platforms APIs directly if you need granular control in your applications or the framework does not meet your requirements. Like most generative AI, this area is rapidly evolving, and I am optimistic about having Go developers have more options to build generative AI solutions.
If you've feedback or questions, or you would like me to cover something else around this topic, feel free to comment below!
Happy building!
Published at DZone with permission of Abhishek Gupta, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments