How To Use LangChain4j With LocalAI
Learn how you can integrate Large Language Model (LLM) capabilities into your Java application, and how to integrate with LocalAI from your Java application.
Join the DZone community and get the full member experience.
Join For FreeIn this post, you will learn how you can integrate Large Language Model (LLM) capabilities into your Java application. More specifically, how you can integrate with LocalAI from your Java application. Enjoy!
Introduction
In a previous post, it was shown how you could run a Large Language Model (LLM) similar to OpenAI by means of LocalAI. The Rest API of OpenAI was used in order to interact with LocalAI. Integrating these capabilities within your Java application can be cumbersome. However, since the introduction of LangChain4j, this has become much easier to do. LangChain4j offers you a simplification in order to integrate with LLMs. It is based on the Python library LangChain. It is therefore also advised to read the documentation and concepts of LangChain since the documentation of LangChain4j is rather short. Many examples are provided though in the LangChain4j examples repository. Especially, the examples in the other-examples directory have been used as inspiration for this blog.
The real trigger for writing this blog was the talk I attended about LangChain4j at Devoxx Belgium. This was the most interesting talk I attended at Devoxx: do watch it if you can make time for it. It takes only 50 minutes.
The sources used in this blog can be found on GitHub.
Prerequisites
The prerequisites for this blog are:
- Basic knowledge about what a Large Language Model is
- Basic Java knowledge (Java 21 is used)
- You need LocalAI if you want to run the examples (see the previous blog linked in the introduction on how you can make use of LocalAI). Version 2.2.0 is used for this blog.
LangChain4j Examples
In this section, some of the capabilities of LangChain4j are shown by means of examples. Some of the examples used in the previous post are now implemented using LangChain4j instead of using curl.
How Are You?
As a first simple example, you ask the model how it is feeling.
In order to make use of LangChain4j in combination with LocalAI, you add the langchain4j-local-ai dependency to the pom file.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-local-ai</artifactId>
<version>0.24.0</version>
</dependency>In order to integrate with LocalAI, you create a ChatLanguageModel specifying the following items:
- The URL where the LocalAI instance is accessible
- The name of the model you want to use in LocalAI
- The temperature: A high temperature allows the model to respond in a more creative way.
Next, you ask the model to generate an answer to your question and you print the answer.
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.9)
.build();
String answer = model.generate("How are you?");
System.out.println(answer);Start LocalAI and run the example above.
The response is as expected.
I'm doing well, thank you. How about yourself?Before continuing, note something about the difference between LanguageModel and ChatLanguageModel. Both classes are available in LangChain4j, so which one to choose? A chat model is a variation of a language model. If you need a "text in, text out" functionality, you can choose LanguageModel. If you also want to be able to use "chat messages" as input and output, you should use ChatLanguageModel.
In the example above, you could just have used LanguageModel and it would behave similarly.
Facts About Famous Soccer Player
Let’s verify whether it also returns facts about the famous Dutch soccer player Johan Cruijff. You use the same code as before, only now you set the temperature to zero because no creative answer is required.
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.build();
String answer = model.generate("who is Johan Cruijff?");
System.out.println(answer);Run the example, the response is as expected.
Johan Cruyff was a Dutch professional football player and coach. He played as a forward for Ajax, Barcelona, and the Netherlands national team. He is widely regarded as one of the greatest players of all time and was known for his creativity, skill, and ability to score goals from any position on the field.Stream the Response
Sometimes, the answer will take some time. In the OpenAPI specification, you can set the stream parameter to true in order to retrieve the response character by character. This way, you can display the response already to the user before awaiting the complete response.
This functionality is also available with LangChain4j but requires the use of a StreamingResponseHandler. The onNext method receives every character one by one. The complete response is gathered in the answerBuilder and futureAnswer. Running this example prints every single character one by one, and at the end, the complete response is printed.
StreamingChatLanguageModel model = LocalAiStreamingChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.build();
StringBuilder answerBuilder = new StringBuilder();
CompletableFuture<String> futureAnswer = new CompletableFuture<>();
model.generate("who is Johan Cruijff?", new StreamingResponseHandler<AiMessage>() {
@Override
public void onNext(String token) {
answerBuilder.append(token);
System.out.println(token);
}
@Override
public void onComplete(Response<AiMessage> response) {
futureAnswer.complete(answerBuilder.toString());
}
@Override
public void onError(Throwable error) {
futureAnswer.completeExceptionally(error);
}
});
String answer = futureAnswer.get(90, SECONDS);
System.out.println(answer);Run the example. The response is as expected.
J
o
h
a
n
...
s
t
y
l
e
.
Johan Cruijff was a Dutch professional football player and coach who played as a forward. ...Other Languages
You can instruct the model by means of a system message how it should behave. For example, you can instruct it to answer always in a different language; Dutch, in this case. This example shows clearly the difference between LanguageModel and ChatLanguageModel. You have to use ChatLanguageModel in this case because you need to interact by means of chat messages with the model.
Create a SystemMessage to instruct the model. Create a UserMessage for your question. Add them to a list and send the list of messages to the model. Also, note that the response is an AiMessage.
The messages are explained as follows:
UserMessage: AChatMessagecoming from a human/userAiMessage: AChatMessagecoming from an AI/assistantSystemMessage: AChatMessagecoming from the system
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.build();
SystemMessage responseInDutch = new SystemMessage("You are a helpful assistant. Antwoord altijd in het Nederlands.");
UserMessage question = new UserMessage("who is Johan Cruijff?");
var chatMessages = new ArrayList<ChatMessage>();
chatMessages.add(responseInDutch);
chatMessages.add(question);
Response<AiMessage> response = model.generate(chatMessages);
System.out.println(response.content());Run the example, the response is as expected.
AiMessage { text = "Johan Cruijff was een Nederlands voetballer en trainer. Hij speelde als aanvaller en is vooral bekend van zijn tijd bij Ajax en het Nederlands elftal. Hij overleed in 1996 op 68-jarige leeftijd." toolExecutionRequest = null }Chat With Documents
A fantastic use case is to use an LLM in order to chat with your own documents. You can provide the LLM with your documents and ask questions about it.
For example, when you ask the LLM for which football clubs Johan Cruijff played ("For which football teams did Johan Cruijff play and also give the periods, answer briefly"), you receive the following answer.
Johan Cruijff played for Ajax Amsterdam (1954-1973), Barcelona (1973-1978) and the Netherlands national team (1966-1977).This answer is quite ok, but it is not complete, as not all football clubs are mentioned and the period for Ajax includes also his youth period. The correct answer should be:
| Years | Team |
|---|---|
| 1964-1973 | Ajax |
| 1973-1978 | Barcelona |
| 1979 | Los Angeles Aztecs |
| 1980 | Washington Diplomats |
| 1981 | Levante |
| 1981 | Washington Diplomats |
| 1981-1983 | Ajax |
| 1983-1984 | Feyenoord |
Apparently, the LLM does not have all relevant information and that is not a surprise. The LLM has some basic knowledge, it runs locally and has its limitations. But what if you could provide the LLM with extra information in order that it can give an adequate answer? Let’s see how this works.
First, you need to add some extra dependencies to the pom file:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain4j.version}</version>
</dependency> Save the Wikipedia text of Johan Cruijff to a PDF file and store it in src/main/resources/example-files/Johan_Cruyff.pdf. The source code to add this document to the LLM consists of the following parts:
- The text needs to be embedded; i.e., the text needs to be converted to numbers. An embedding model is needed for that, for simplicity you use the
AllMiniLmL6V2EmbeddingModel. - The embeddings need to be stored in an embedding store. Often a vector database is used for this purpose, but in this case, you can use an in-memory embedding store.
- The document needs to be split into chunks. For simplicity, you split the document into chunks of 500 characters. All of this comes together in the
EmbeddingStoreIngestor. - Add the PDF to the ingestor.
- Create the
ChatLanguageModeljust like you did before. - With a
ConversationalRetrievalChain, you connect the language model with the embedding store and model. - And finally, you execute your question.
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 0))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
Document johanCruiffInfo = loadDocument(toPath("example-files/Johan_Cruyff.pdf"));
ingestor.ingest(johanCruiffInfo);
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.build();
ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder()
.chatLanguageModel(model)
.retriever(EmbeddingStoreRetriever.from(embeddingStore, embeddingModel))
.build();
String answer = chain.execute("Give all football teams Johan Cruijff played for in his senior career");
System.out.println(answer);When you execute this code, an exception is thrown.
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: java.io.InterruptedIOException: timeout
at dev.langchain4j.internal.RetryUtils.withRetry(RetryUtils.java:29)
at dev.langchain4j.model.localai.LocalAiChatModel.generate(LocalAiChatModel.java:98)
at dev.langchain4j.model.localai.LocalAiChatModel.generate(LocalAiChatModel.java:65)
at dev.langchain4j.chain.ConversationalRetrievalChain.execute(ConversationalRetrievalChain.java:65)
at com.mydeveloperplanet.mylangchain4jplanet.ChatWithDocuments.main(ChatWithDocuments.java:55)
Caused by: java.lang.RuntimeException: java.io.InterruptedIOException: timeout
at dev.ai4j.openai4j.SyncRequestExecutor.execute(SyncRequestExecutor.java:31)
at dev.ai4j.openai4j.RequestExecutor.execute(RequestExecutor.java:59)
at dev.langchain4j.model.localai.LocalAiChatModel.lambda$generate$0(LocalAiChatModel.java:98)
at dev.langchain4j.internal.RetryUtils.withRetry(RetryUtils.java:26)
... 4 more
Caused by: java.io.InterruptedIOException: timeout
at okhttp3.internal.connection.RealCall.timeoutExit(RealCall.kt:398)
at okhttp3.internal.connection.RealCall.callDone(RealCall.kt:360)
at okhttp3.internal.connection.RealCall.noMoreExchanges$okhttp(RealCall.kt:325)
at okhttp3.internal.connection.RealCall.getResponseWithInterceptorChain$okhttp(RealCall.kt:209)
at okhttp3.internal.connection.RealCall.execute(RealCall.kt:154)
at retrofit2.OkHttpCall.execute(OkHttpCall.java:204)
at dev.ai4j.openai4j.SyncRequestExecutor.execute(SyncRequestExecutor.java:23)
... 7 more
Caused by: java.net.SocketTimeoutException: timeout
at okio.SocketAsyncTimeout.newTimeoutException(JvmOkio.kt:147)
at okio.AsyncTimeout.access$newTimeoutException(AsyncTimeout.kt:158)
at okio.AsyncTimeout$source$1.read(AsyncTimeout.kt:337)
at okio.RealBufferedSource.indexOf(RealBufferedSource.kt:427)
at okio.RealBufferedSource.readUtf8LineStrict(RealBufferedSource.kt:320)
at okhttp3.internal.http1.HeadersReader.readLine(HeadersReader.kt:29)
at okhttp3.internal.http1.Http1ExchangeCodec.readResponseHeaders(Http1ExchangeCodec.kt:178)
at okhttp3.internal.connection.Exchange.readResponseHeaders(Exchange.kt:106)
at okhttp3.internal.http.CallServerInterceptor.intercept(CallServerInterceptor.kt:79)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at okhttp3.internal.connection.ConnectInterceptor.intercept(ConnectInterceptor.kt:34)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at okhttp3.internal.cache.CacheInterceptor.intercept(CacheInterceptor.kt:95)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at okhttp3.internal.http.BridgeInterceptor.intercept(BridgeInterceptor.kt:83)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at okhttp3.internal.http.RetryAndFollowUpInterceptor.intercept(RetryAndFollowUpInterceptor.kt:76)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at dev.ai4j.openai4j.ResponseLoggingInterceptor.intercept(ResponseLoggingInterceptor.java:21)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at dev.ai4j.openai4j.RequestLoggingInterceptor.intercept(RequestLoggingInterceptor.java:31)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at dev.ai4j.openai4j.AuthorizationHeaderInjector.intercept(AuthorizationHeaderInjector.java:25)
at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.kt:109)
at okhttp3.internal.connection.RealCall.getResponseWithInterceptorChain$okhttp(RealCall.kt:201)
... 10 more
Caused by: java.net.SocketException: Socket closed
at java.base/sun.nio.ch.NioSocketImpl.endRead(NioSocketImpl.java:243)
at java.base/sun.nio.ch.NioSocketImpl.implRead(NioSocketImpl.java:323)
at java.base/sun.nio.ch.NioSocketImpl.read(NioSocketImpl.java:346)
at java.base/sun.nio.ch.NioSocketImpl$1.read(NioSocketImpl.java:796)
at java.base/java.net.Socket$SocketInputStream.read(Socket.java:1099)
at okio.InputStreamSource.read(JvmOkio.kt:94)
at okio.AsyncTimeout$source$1.read(AsyncTimeout.kt:125)
... 32 moreThis can be solved by setting the timeout of the language model to a higher value.
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.timeout(Duration.ofMinutes(5))
.build();Run the code again, and the following answer is received, which is correct.
Johan Cruijff played for the following football teams in his senior career:
- Ajax (1964-1973)
- Barcelona (1973-1978)
- Los Angeles Aztecs (1979)
- Washington Diplomats (1980-1981)
- Levante (1981)
- Ajax (1981-1983)
- Feyenoord (1983-1984)
- Netherlands national team (1966-1977)Using a 1.x version of LocalAI gave this response, which was worse.
Johan Cruyff played for the following football teams:
- Ajax (1964-1973)
- Barcelona (1973-1978)
- Los Angeles Aztecs (1979)The following steps were used to solve this problem.
When you take a closer look at the PDF file, you notice that the information about the football teams is listed in a table next to the regular text. Remember that splitting the document was done by creating chunks of 500 characters. So, maybe this splitting is not executed well enough for the LLM.
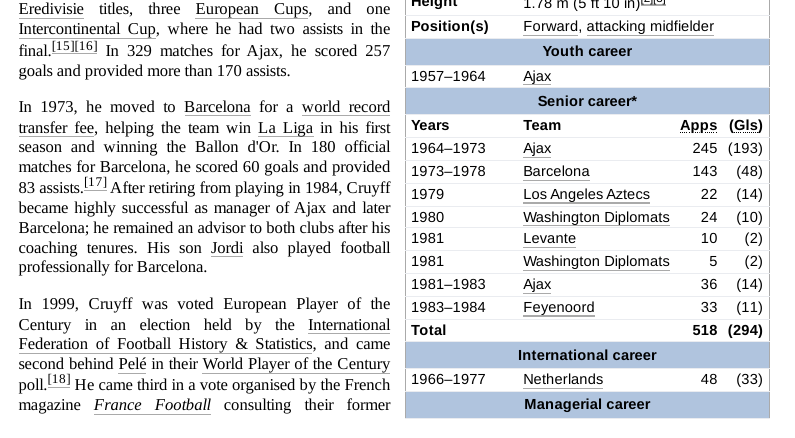
Copy the football teams in a separate text document.
Years Team Apps (Gls)
1964–1973 Ajax 245 (193)
1973–1978 Barcelona 143 (48)
1979 Los Angeles Aztecs 22 (14)
1980 Washington Diplomats 24 (10)
1981 Levante 10 (2)
1981 Washington Diplomats 5 (2)
1981–1983 Ajax 36 (14)
1983–1984 Feyenoord 33 (11)Add both documents to the ingestor.
Document johanCruiffInfo = loadDocument(toPath("example-files/Johan_Cruyff.pdf"));
Document clubs = loadDocument(toPath("example-files/Johan_Cruyff_clubs.txt"));
ingestor.ingest(johanCruiffInfo, clubs);Run this code and this time, the answer was correct and complete.
Johan Cruijff played for the following football teams in his senior career:
- Ajax (1964-1973)
- Barcelona (1973-1978)
- Los Angeles Aztecs (1979)
- Washington Diplomats (1980-1981)
- Levante (1981)
- Ajax (1981-1983)
- Feyenoord (1983-1984)
- Netherlands national team (1966-1977)It is therefore important that the sources you provide to an LLM are split wisely. Besides that, the used technologies improve in a rapid way. Even while writing this blog, some problems were solved in a couple of weeks. Updating to a more recent version of LocalAI for example, solved one way or the other the problem with parsing the single PDF.
Conclusion
In this post, you learned how to integrate an LLM from within your Java application using LangChain4j. You also learned how to chat with documents, which is a fantastic use case! It is also important to regularly update to newer versions as the development of these AI technologies improves continuously.
Published at DZone with permission of Gunter Rotsaert, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments