How to Quarterback Data Incident Response
Incident management isn’t just for software engineers. With the rise of data platforms and the data-as-a-product mentality, building more reliable processes and workflows to handle data quality has emerged as a top concern for data engineers.
Join the DZone community and get the full member experience.
Join For FreeIt's Monday morning, and your phone won't stop buzzing.
You wake up to messages from your CEO saying, "The numbers in this report don't seem right...again."
You and your team drop what you're doing and begin to troubleshoot the issue at hand. However, your teams' response to the incident is a mess. Other team members across the organization are repeating efforts, and your CMO is left in the dark while no updates are being sent out to the rest of the organization.
As all of this is going on, you get texted by John in Finance about an errant table in his spreadsheet, and Eleanor in Operations about a query that pulled interesting results.
What is a data engineer to do?
If this situation sounds familiar to you, know that you are not alone. All too often, data engineers are straddled with the burden of not just fixing data issues, but prioritizing what to fix, how to fix it, and communicating status as the incident evolves. For many companies, data team responsibilities underlying this firefighting are often ambiguous, particularly when it relates to answering the question: “who is managing this incident?”
Sure, data reliability SLAs should be managed by entire teams, but when the rubber hits the road, we need a dedicated persona to help call the shots and make sure these SLAs are met should data break.
In software engineering, this role is often defined as an incident commander, and its core responsibilities include:
- Flagging incidents to the broader data team and stakeholders early and often.
- Maintain a working record of affected data assets or anomalies.
- Coordinating efforts and assigning responsibilities for a given incident.
- Circulating runbooks and playbooks as necessary.
- Assessing the severity and impact of the incident.
Data teams should assign rotating incident commanders on a weekly or daily basis, or for specific data sets owned by specific functional teams. Establishing a good, repeatable practice of incident management (that delegates clear incident commanders) is primarily a cultural process, but investing in automation and maintaining a constant pulse on data health gets you much of the way there. The rest is education.
Here are four key steps every incident manager must take when triaging and assessing the severity of a data issue:
1. Route Notifications to the Appropriate Team Members
When responding to data incidents, the way your data organization is structured will impact your incident management workflow, and as a result, the incident commander process.

If you sit on an embedded data team, it’s much easier to delegate incident response (i.e., the marketing data and analytics team owns all marketing analytics pipelines).

If you sit on a centralized data team, fielding and routing these incident alerts to the appropriate owners requires a bit more foresight and planning.
Either way, we suggest you set up dedicated Slack channels for data pipelines owned and maintained by specific members of your data team, inviting relevant stakeholders so they’re in the know if critical data they rely on is down. Many teams we work with set up PagerDuty or Opsgenie workflows to ensure that no bases are left uncovered.
2. Assess the Severity of the Incident
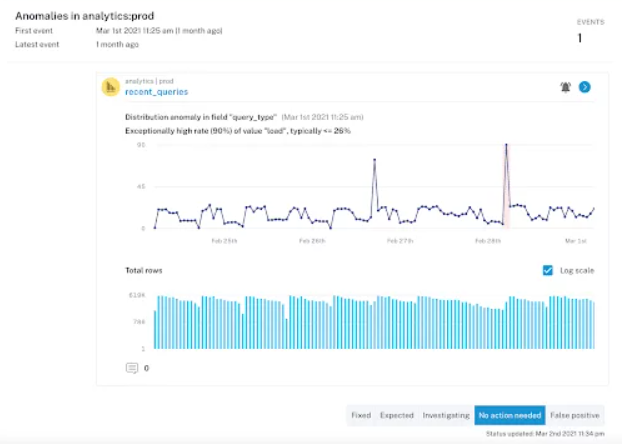
Once the pipeline owner is notified that something is wrong with the data, the first step they should take is to assess the severity of the incident. Because data ecosystems are constantly evolving, there are an abundance of changes that can be introduced into your data pipelines at any given time. While some are harmless (i.e., expected schema change), some are much more lethal, causing impact to downstream stakeholders (i.e., rows in a critical table dropping from 10,000 to 1,000).
Once your team starts troubleshooting the issue, it is a best practice to tag the issue based on its status, whether fixed, expected, investigating, no action needed, or false positive. Tagging the issue helps users with assessing the severity of the incident and also plays a key role in communicating the updates to relevant stakeholders in channels that are specific to the data that was affected so they can take appropriate action.
What if a data asset breaks that isn’t important to your company? In fact, what if this data is deprecated?
Phantom data haunts even the best data teams, and I can’t tell you how many times I have been on the receiving end of an alert for a data issue that, after all of the incident resolution was said and done, just did not matter to the business. So, instead of tackling high priority problems, I spent hours or even days firefighting broken data only to discover I was wasting my time. We have not used that table since 2019.
So, how do you determine what data matters most to your organization? One increasingly common way teams have been able to discover their most critical data sets is by utilizing tools that help them visualize their data lineage. This allows them to have visibility into how all of their data sets are related when an incident does arise, and to be able to trace data ownership to alert the right people that might be affected by the issue.
Once your team can figure out the severity of the impact, they will have a better understanding as to what priority level the error is. If it is data that is directly powering financial insights, or even how well your products are performing, it is likely a super high priority issue and your team should stop what they are doing to fix it ASAP. And if it's not, time to move on.
3. Communicate Status Updates as Often as Possible
Good communication goes a long way in the heat of responding to a data incident, which is why we have already discussed how and why data teams should create a runbook that walks through (step-by-step) how to handle a given type of incident. Following a runbook is crucial to maintain correct lines of responsibility and reduce duplication of effort.
Once you have “who does what” down, your team can then start updating a status page where stakeholders can follow along for updates in real time. A central status page also allows team members to see what others are working on and what the current status is of those incidents.
In talks with customers, I have seen incident command delegation handled in one of two ways:
- Assign a team member to be on call to handle any incidents during a given time period: While on call, that person is responsible for handling all types of data incidents. Some teams have someone full time that does this for all incidents their team manages, while others have a schedule in place that rotates team members every week to cover.
- Team members responsible for covering certain tables: This is the most common structure we see. With this structure, team members handle all incidents related to their assigned tables or reports while doing their normal daily activities. Table assignment is generally aligned based on the data or pipelines a given member works with most closely.
One important thing to keep in mind is that there is no right or wrong way here. Ultimately, it is just a matter of making sure that you commit to a process and stick with it.
4. Define and Align on Data SLAs and SLIs to Prevent Future Incidents and Downtime
While the incident commander is not accountable for setting SLAs, they are often held responsible for meeting them.
Simply put, service-level agreements (SLAs) are a method many companies use to define and measure the level of service a given vendor, product, or internal team will deliver — as well as potential remedies if they fail to deliver.
For example, Slack’s customer-facing SLA promises 99.99% uptime every fiscal quarter, and no more than 10 hours of scheduled downtime, for customers on Plus plans and above. If they fall short, affected customers will receive service credits on their accounts for future use.
Your service-level indicators (SLIs), quantitative measures of your SLAs, will depend on your specific use case, but here are a few metrics used to quantify incident response and data quality:
- The number of data incidents for a particular data asset (N): Although this may be beyond your control, given that you likely rely on external data sources, it’s still an important driver of data downtime and usually worth measuring.
- Time-to-detection (TTD): When an issue arises, this metric quantifies how quickly your team is alerted. If you don’t have proper detection and alerting methods in place, this could be measured in weeks or even months. “Silent errors” made by bad data can result in costly decisions, with repercussions for both your company and your customers.
- Time-to-resolution (TTR): When your team is alerted to an issue, this measures how quickly you were able to resolve it.
By keeping track of these, data teams can work to reduce TTD and TTR, and in turn, build more reliable data systems.
Why Data Incident Commanders Matter
When it comes to responding to data incidents, time is of the essence, and as the incident commander, time is both your enemy and your best friend.
In an ideal world, companies want data issues to be resolved as quickly as possible. However, that is not always the case and some teams often find themselves investigating data issues more frequently than they would like. In fact, while data teams invest a large amount of their time writing and updating custom data tests, they still experience broken pipelines.
An incident commander, armed with the right processes, a pinch of automation, and organizational support, can work wonders for the reliability of your data pipelines.
Your CEO will thank you later.
Published at DZone with permission of Glen Willis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments