How To Fine-Tune Large Language Models: A Step-By-Step Guide
In 2023, the rise of Large Language Models (LLMs) like Alpaca, Falcon, Llama 2, and GPT-4 indicates a trend toward AI democratization.
Join the DZone community and get the full member experience.
Join For FreeIn 2023, the rise of Large Language Models (LLMs) like Alpaca, Falcon, Llama 2, and GPT-4 indicates a trend toward AI democratization. This allows even small companies to afford customized models, promoting widespread adoption. However, challenges persist, such as restricted licensing for open-source models and the costs of fine-tuning and maintenance, which are manageable mainly for large enterprises or research institutes.
The key to maximizing LLM potential is in fine-tuning and customizing pre-trained models for specific tasks. This approach aligns with individual requirements, providing innovative and tailored solutions. Fine-tuning not only enhances model efficiency and accuracy but also optimizes system resource utilization, requiring less computational power than training from scratch.
Efficient GPU RAM management is crucial for models with numerous parameters. For instance, loading a 1 billion parameter model at 32-bit precision demands 4GB of GPU RAM. To overcome this, quantization reduces parameter precision and cutting memory requirements. Converting from 32-bit to 16-bit precision can halve the memory needed for both loading and training the model.
The techniques most commonly employed to manage optimized fine tuning are PEFT (Parameter Efficient Fine Tuning) and RLHF (Reinforcement Learning with Human Feedback).
Parameter-efficient fine-tuning methods
In the process of fully fine-tuning Large Language Models, it is important to have a computational setup that can efficiently handle not just the substantial model weights, which for the most advanced models are now reaching sizes in the hundreds of gigabytes, but also manage a series of other critical elements. The following are the categories of PEFT methods for optimizing fine-tuning of LLMs.
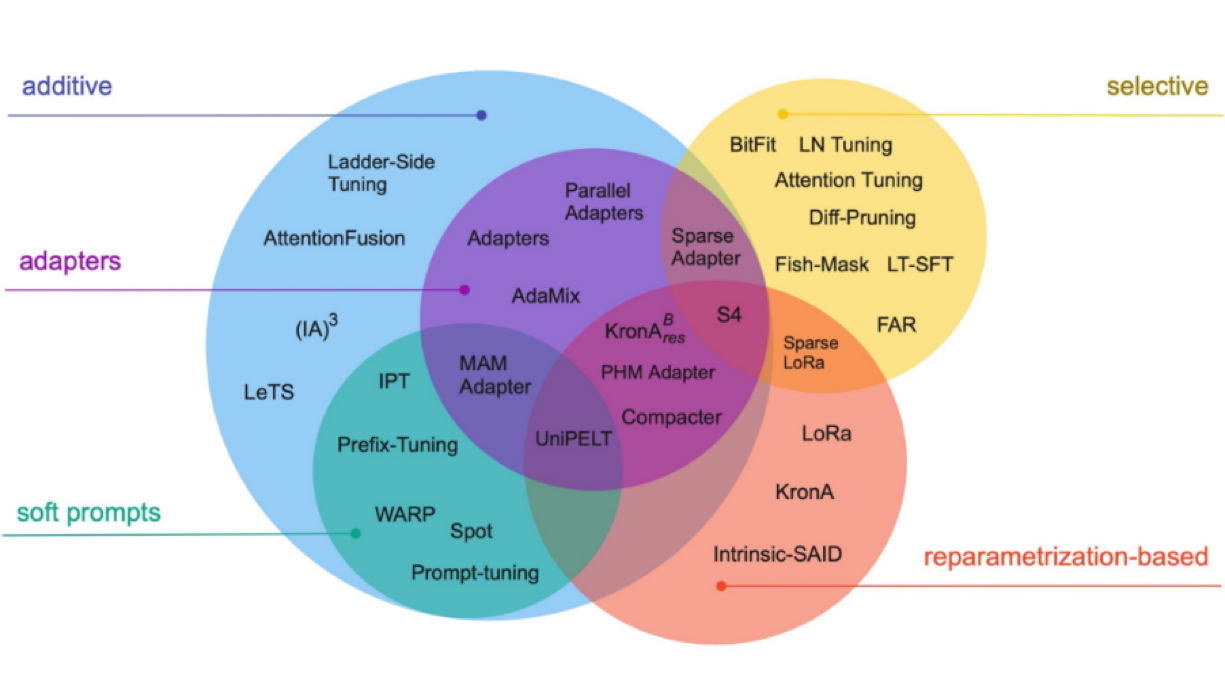
Additive Method
This type of tuning can augment the pre-trained model with additional parameters or layers, focusing on training only the newly added parameters. The additive method is further divided into sub-categories:
- Adapters: Incorporating small fully connected networks post transformer sub-layers, with notable examples being AdaMix, KronA, and Compactor.
- Soft prompts: Fine-tuning a segment of the model’s input embeddings through gradient descent, with IPT, prefix-tuning, and WARP being prominent examples.
- Other additive approaches: Include techniques like LeTS, AttentionFusion, and Ladder-Side Tuning.
Selective Method
Selective PEFTs fine-tune a limited number of top layers based on layer type and internal model structure. This category includes methods like BitFit and LN tuning, which focus on tuning specific elements such as model biases or particular rows.
Re-Parameterization Based Method
These methods utilize low-rank representations to reduce the number of trainable parameters, with the most renowned being Low-Rank Adaptation or LoRA.
LoRA (Low-Rank Adaptation)
LoRA emerged as a groundbreaking PEFT technique, introduced in a paper by Edward J. Hu and others in 2021. It operates within the reparameterization category, freezing the original weights of the LLM and integrating new trainable low-rank matrices into each layer of the Transformer architecture. This approach not only curtails the number of trainable parameters but also diminishes the training time and computational resources required, thereby providing more efficient alternative to full fine-tuning.
LoRA uses the concept of Singular Value Decomposition (SVD). Essentially, SVD dissects a matrix into three distinct matrices, one of which is a diagonal matrix housing singular values.
LoRA intervenes in this process, freezing all original model parameters and introducing a pair of “rank decomposition matrices” alongside the original weights. These smaller matrices, denoted as A and B, undergo training through supervised learning. This strategy has been effectively implemented using open-source libraries such as HuggingFace Transformers, facilitating LoRA fine-tuning for various tasks with remarkable efficiency.
QLoRA: Taking LoRA Efficiency Higher
Building on the foundation laid by LoRA, QLoRA further minimizes memory requirements. Introduced by Tim Dettmers and others in 2023, it combines low-rank adaptation with quantization, employing a 4-bit quantization format termed NormalFloat or NumericFloat4 (nf4). Quantization is essentially a process that transitions data from a higher informational representation to one with less information. This approach maintains the efficacy of 16-bit fine-tuning methods, de-quantizing the 4-bit weights to 16-bits as necessitated during computational processes.
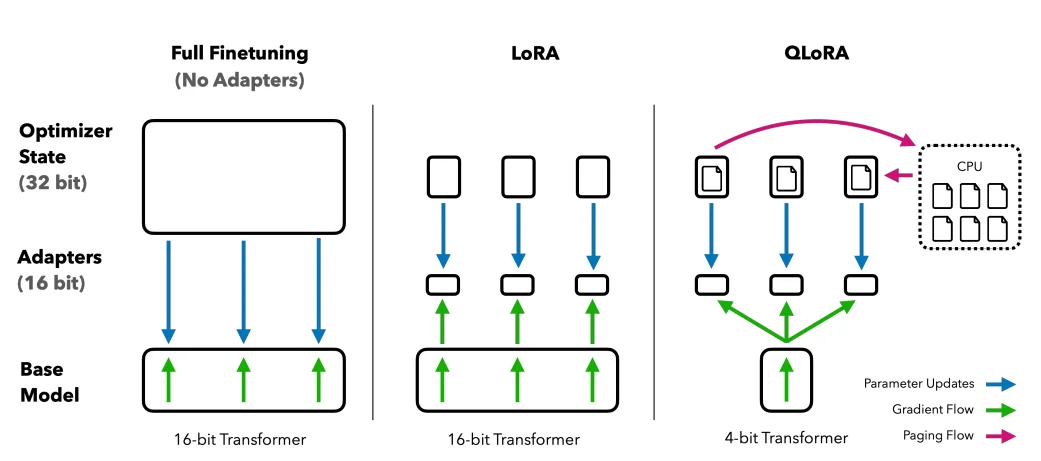
QLoRA leverages NumericFloat4 (nf4), targeting every layer in the transformer architecture, and introduces the concept of double quantization to further shrink the memory footprint required for fine-tuning. This is achieved by performing quantization on the already quantized constants, a strategy that averts typical gradient checkpointing memory spikes through the utilization of paged optimizers and unified memory management.
Reinforcement Learning From Human Feedback Methods
Reinforcement Learning from Human Feedback (RLHF is used when fine-tuning pre-trained language models to align more closely with human values. The RLHF process leverages human feedback extensively, utilizing it to train a reward model. It is a dynamic and iterative process where the model learns through a series of feedback loops leading to a reward in the context of language generation. At the core of RLHF is the reinforcement learning paradigm, a type of machine learning technique where an agent learns how to behave in an environment by performing actions and receiving rewards. It's a continuous loop of action and feedback where the agent is incentivized to make choices that will yield the highest reward. Translating this to the realm of language models, the agent is the model itself, operating within the environment of a given context window and making decisions based on the state, which is defined by the current tokens in the context window. The “action space” encompasses all potential tokens the model can choose from, with the goal being to select the token that aligns most closely with human preferences.
Instruction-Based Fine-Tuning
The fine-tuning phase in the Generative AI lifecycle is characterized by the integration of instruction inputs and outputs, coupled with examples of step-by-step reasoning.
Single-Task Fine-Tuning
Single-task fine-tuning focuses on honing the model's expertise in a specific task, such as summarization. This approach is particularly beneficial in optimizing workflows involving substantial documents or conversation threads, including legal documents and customer support tickets. This fine-tuning can achieve significant performance enhancements with a relatively small set of examples, ranging from 500 to 1000, a contrast to the billions of tokens utilized in the pre-training phase.
Steps for Fine-Tuning a LLM
Here are the steps required to fine-tune an LLM model with multi-billion parameters.
QLoRA technique is used in this example to fine-tune a model. For that, you can use the Hugging Face ecosystem of LLM libraries: transformers, accelerate, peft, trl, and bitsandbytes.
1. Getting Started
Start by installing the required libraries in the Python environment on a machine with the required GPU capacity for fine-tuning the use case. After that, load the necessary modules from these libraries.
2. Model Configuration
Access the model from the Hugging Face library, apply for a request, and get confirmation.
Example of the access request form on Hugging Face for Llama 2 open source model. Upon approval, download the model into your environment from the online library.

Image from Hugging Face
3. Load Dataset
Identify a dataset for fine-tuning based on the model and method for fine-tuning to be adopted for your specific use case. An example dataset is called mlabonne/guanaco-llama2-1k in the Hugging Face library. Load the identified dataset from the Hugging Face hub in your environment.
4. Carry Out Quantization Configuration if Required
4-bit quantization via QLoRA allows efficient finetuning of huge LLM models on consumer hardware while retaining high performance. This dramatically improves accessibility and usability for real-world applications.
QLoRA quantizes a pre-trained language model to 4 bits and freezes the parameters. A small number of trainable Low-Rank Adapter layers are then added to the model.
5. Load Tokenizer
Next, load the tokenizer from HuggingFace and adjust the padding side to fix any issues.
6. PEFT Parameters
Traditional fine-tuning of pre-trained language models (PLMs) requires updating all of the model's parameters, which is computationally expensive and requires massive amounts of data.
Parameter-efficient fine-tuning (PEFT) works by only updating a small subset of the model's parameters, making it much more efficient. Learn about parameters by reading the PEFT official documentation.
7. Training Parameters
Below is a list of hyper-parameters that can be used to optimize the training process:
- output_dir: The output directory is where the model predictions and checkpoints will be stored.
- num_train_epochs: One training epoch.
- fp16/bf16: Disable fp16/bf16 training.
- per_device_train_batch_size: Batch size per GPU for training.
- per_device_eval_batch_size: Batch size per GPU for evaluation.
- gradient_accumulation_steps: This refers to the number of steps required to accumulate the gradients during the update process.
- gradient_checkpointing: Enabling gradient checkpointing.
- max_grad_norm: Gradient clipping.
- learning_rate: Initial learning rate.
- weight_decay: Weight decay is applied to all layers except bias/LayerNorm weights.
- Optim: Model optimizer (AdamW optimizer).
- lr_scheduler_type: Learning rate schedule.
- max_steps: Number of training steps.
- warmup_ratio: Ratio of steps for a linear warmup.
- group_by_length: This can significantly improve performance and accelerate the training process.
- save_steps: Save checkpoint every 25 update steps.
- logging_steps: Log every 25 update steps.
8. Model Fine-Tuning
Supervised fine-tuning (SFT) is a key step in reinforcement learning from human feedback (RLHF). The TRL library from HuggingFace provides an easy-to-use API to create SFT models and train them on your dataset with just a few lines of code. It comes with tools to train language models using reinforcement learning, starting with supervised fine-tuning, then reward modeling, and finally, proximal policy optimization (PPO). After training the model, save the model adopter and tokenizers. You can also upload the model to Hugging Face using a similar API.
9. Evaluation
Review the training results in the interactive session of Tensorboard.
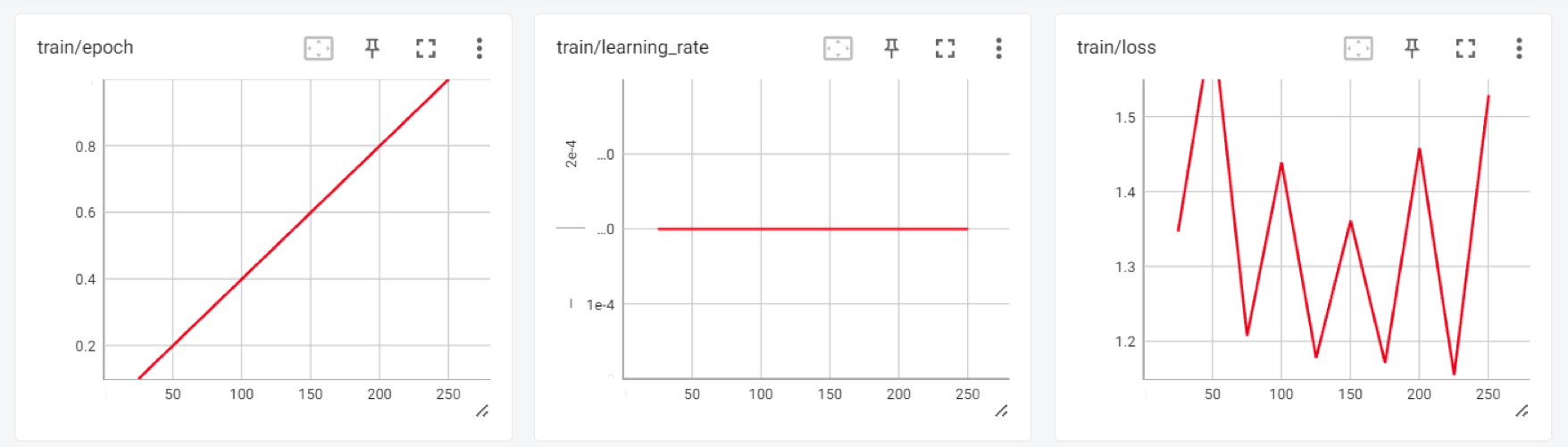
To test a fine-tuned model, use the Transformers text generation pipeline and ask simple questions like “Who is Leonardo Da Vinci?”.
Conclusion
The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA, PEFT, and SFT to overcome memory and compute limitations. By leveraging Hugging Face libraries like transformers, accelerate, peft, trl, and bitsandbytes, we were able to successfully fine-tune the 7B parameter LLaMA 2 model on a consumer GPU.
Overall, this tutorial exemplified how recent advances have enabled the democratization and accessibility of large language models, allowing even hobbyists to build state-of-the-art AI with limited resources.
Opinions expressed by DZone contributors are their own.
Comments