How to Build a Data Foundation for Generative AI
GenAI depends on data maturity, in which an organization demonstrates mastery over both integrating data (moving and transforming it) and governing its use.
Join the DZone community and get the full member experience.
Join For FreeSince late 2022, generative AI has quickly demonstrated its value and potential to help businesses of all sizes innovate faster. By generating new media from prompts, generative AI stands to become a powerful productivity aid, multiplying the effect of creative and intellectual work of all kinds. According to Gartner, 55 percent of organizations have plans to use generative AI and 78 percent of executives believe the benefits of AI adoption outweigh the risks.
The world will be transformed by AI-assisted medicine, education, scientific research, law, and more. Researchers at the University of Toronto use generative AI to model proteins that don’t exist in nature. Similarly, pharmaceutical giant Bayer now uses generative AI to accelerate the process of drug discovery. Education provider Khan Academy has developed an AI chatbot/tutor, Khanmigo, to personalize learning. The list of examples across all industries only continues to grow.
Generative AI is not just a general-purpose productivity aid that surfaces information the way a search engine does; with gen AI, organizations can combine their unique, proprietary data with foundation models that have been pre-trained on a broad base of public data. Trained on a combination of public and proprietary data, generative AI may become the most knowledgeable entity within an organization, opening up innumerable opportunities for innovation.
However, as with all analytics, generative AI is only as good as its data. To fully leverage AI, an organization needs mastery over its proprietary data. This means a solid foundation of data operations technologies and organizational norms that facilitate responsible and effective use of data.
Data readiness for generative AI depends on two key elements:
The ability to move and integrate data from databases, applications, and other sources in an automated, reliable, cost-effective, and secure manner
Knowing, protecting, and accessing data through data governance
This kind of data readiness is perennially overlooked and has historically derailed many attempts to leverage the power of big data and data science. One metric suggests that as many as 87 percent of data science projects never make it to production, often because of siloed and ungoverned data as well as underdeveloped data infrastructure.
Generative AI Depends on a Foundation of Data Maturity
Without data maturity, the prototyping, deployment, and testing of generative AI — or indeed, any kind of analytics — becomes extremely difficult.
There are both technological and organizational elements to data maturity. On the technological side, the following capabilities are essential:
A central, cloud-based data repository that can serve as a single source of truth
A tool that reliably and automatically ingests data from sources at scale and features:
Fast, timely updates
Reliability and the ability to quickly recover from failures
A tool that supports collaborative, version-controlled modeling and transforming of data.
Data governance capabilities such as:
Ability to block and hash sensitive data before it arrives in a central repository
Access control
Ability to catalog data
Automated user provisioning
Automation is an essential prerequisite for efficient, reliable, and scalable data movement and integration.
On the organizational side, your team will need the following practices and structures in place:
A scaled analytics organization where, in addition to a core team of analysts, you also have domain experts assigned to specific functional units within your organization
Reports issued on a regular cadence, and stakeholders in your organization who access and regularly use dashboards to support decisions
Product thinking in analytics, in which the reports, dashboards, models, etc. that your team builds are tailored to the needs of stakeholders
Good visibility into your data, as exemplified by cataloging of data assets
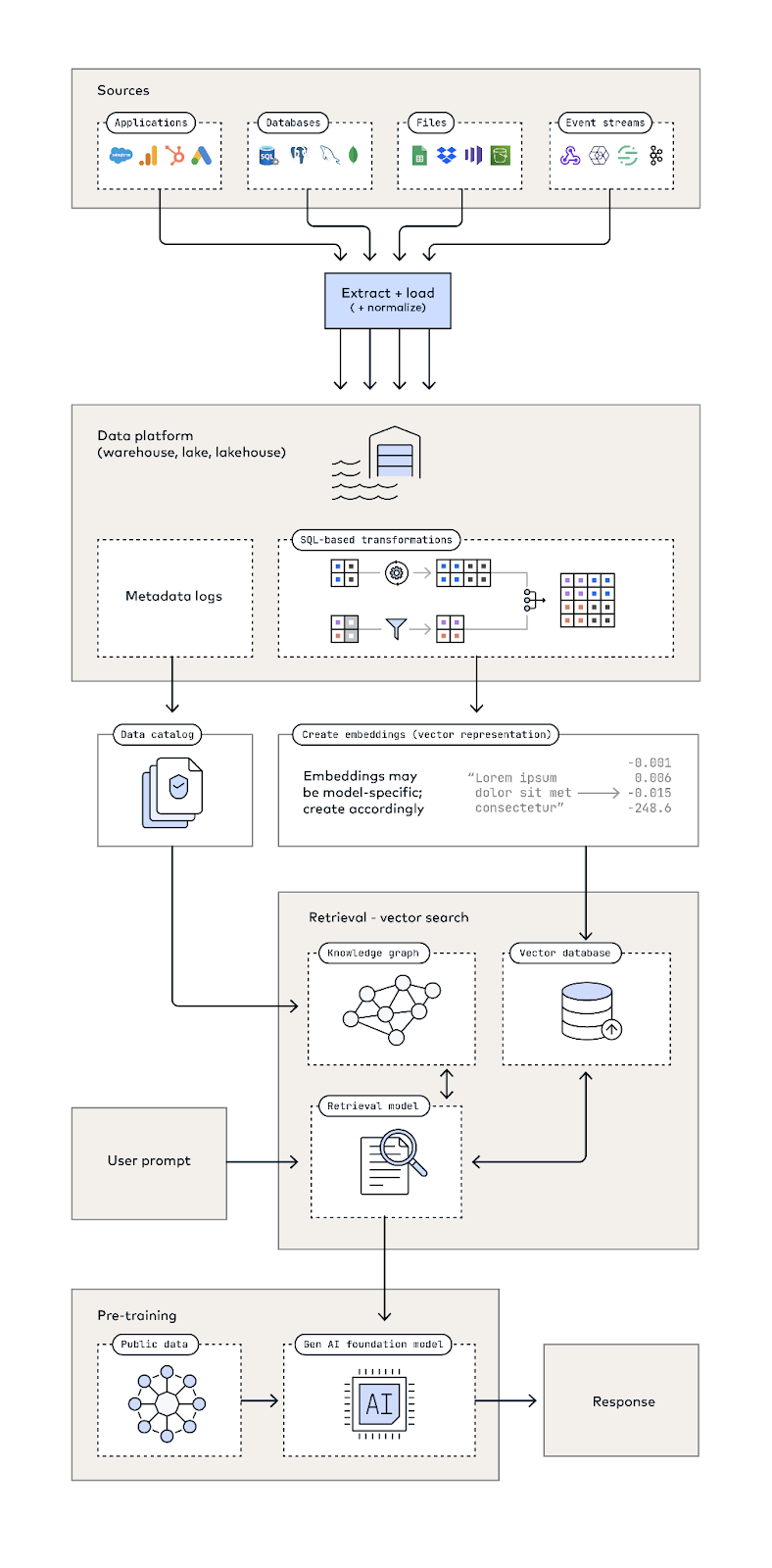
Your Data Platform Architecture for Generative AI
Building generative AI from scratch is a colossal undertaking, with the potential to cost hundreds of millions of dollars and the equivalent of hundreds of years. Your organization is most likely to use a base or foundation model — a commercially available model already trained on huge volumes of public data.
In the initial stages, this architecture (see appendix at the end) mirrors basic analytics use cases, requiring a data pipeline to extract, load, and transform raw data into models for supporting reports, dashboards, and other data assets.
What comes afterward is unique to generative AI. You can supplement an off-the-shelf generative AI model with your data in two ways:
Convert text into enumerations, store in a vector database for generative AI to integrate into long-term memory, enhancing results from initial training and unique organizational data.
Combine large language models with knowledge graphs, explicitly encoding semantic understanding into the model, not just statistical word associations.
Even with the help of an increasing number of off-the-shelf tools for managing data infrastructure with generative AI, it is likely that you will need to lean heavily on engineering, data science, and AI expertise to make the parts function properly with each other and build usable applications on top of the architecture.
The potential of generative AI can only be fully realized when organizations recognize the pivotal role of their proprietary data. By prioritizing mastery over data through the implementation of advanced data operations technologies and cultivating a culture of responsible data use, organizations can unlock the true power of generative AI, ensuring its optimal performance and ethical deployment in a rapidly advancing technological landscape.
Appendix
Published at DZone with permission of Charles Wang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments