How Disaster Recovery Solutions for Cloud Databases Have Evolved Over the Years
In this article, you’ll learn about the development of disaster recovery technologies and the databases that have adopted those innovations.
Join the DZone community and get the full member experience.
Join For FreeDisaster recovery (DR) is a core feature of enterprise-level databases. Database vendors are constantly looking to improve DR, and in the last 10 years they’ve made major innovations.
This article is a brief history of database DR, with an emphasis on DR and high availability (HA) innovations in cloud-based distributed databases.
Measuring HA and DR
The goal of HA and DR is to keep a system up and running at an operational level. They both try to eliminate single points of failure in the system and automate the failover or recovery process.
High availability is usually measured by the percentage of time the system is up per year. Disaster recovery focuses on returning a system to service after a disaster with minimal data loss. This is measured by two metrics: the time it takes to recover or Recovery Time Objective (RTO), and the loss of data volume, or Recovery Point Objective (RPO). RPO and RTO should be reduced as much as possible.
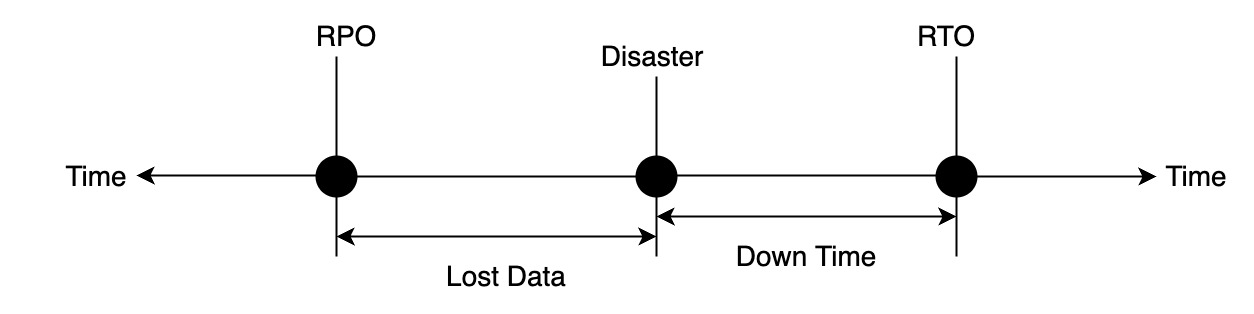
HA/DR and their measurements
Each disaster is unique, so Fault Tolerance Target (FTT) describes the maximum scope of disasters that the system can survive. A commonly-used FTT is the region level, which indicates that a disaster has impacted a geographic area like a state or city.
A Brief History of DR
Database DR technologies have gone through three stages: backup and restore, active-passive, and multi-active.
Backup and Restore
In the earliest stage of disaster recovery, databases leveraged data blocks and transaction logs to create a backup for full and incremental data. If a disaster occurred, the database was restored from the backup and application transaction logs.
In recent years, public cloud database services have combined storage replication with traditional database backup technologies and offered cross-region auto-recovery backup based on snapshots. This approach regularly generates snapshots from the database in the source region and replicates the snapshot files to the destination region. If the source region crashes, the database is recovered from the destination region, and the services will continue. The RTO and RPO of this solution can be as long as a few hours, so it is most appropriate for applications that don’t have strict availability requirements.
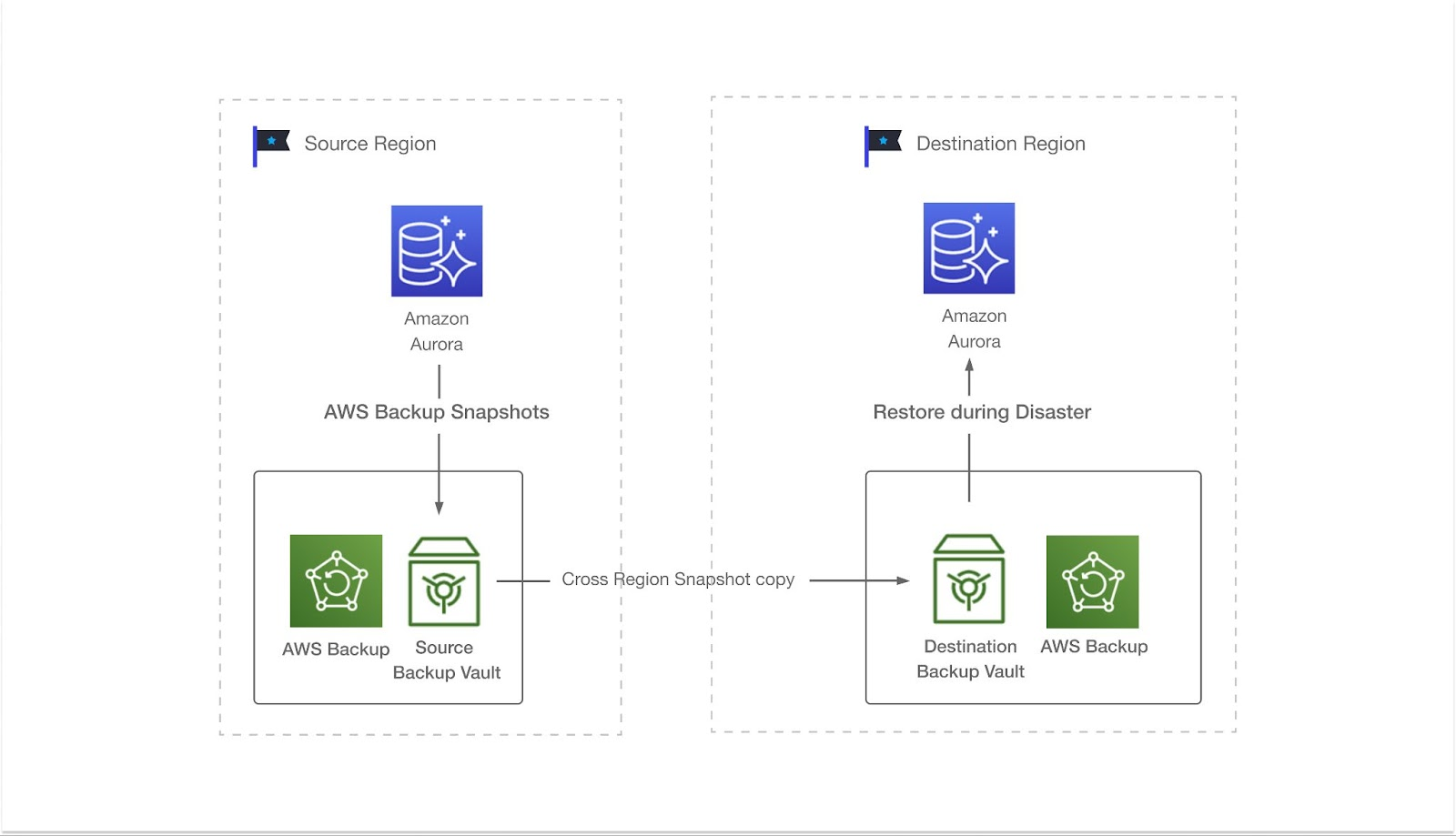
The backup and restore DR approach
Active-Passive DR
Database clusters mark the second phase of development. In a cluster, a master node reads and writes data. One or more backup nodes receive the transaction logs and apply them, providing read capabilities with some delay.
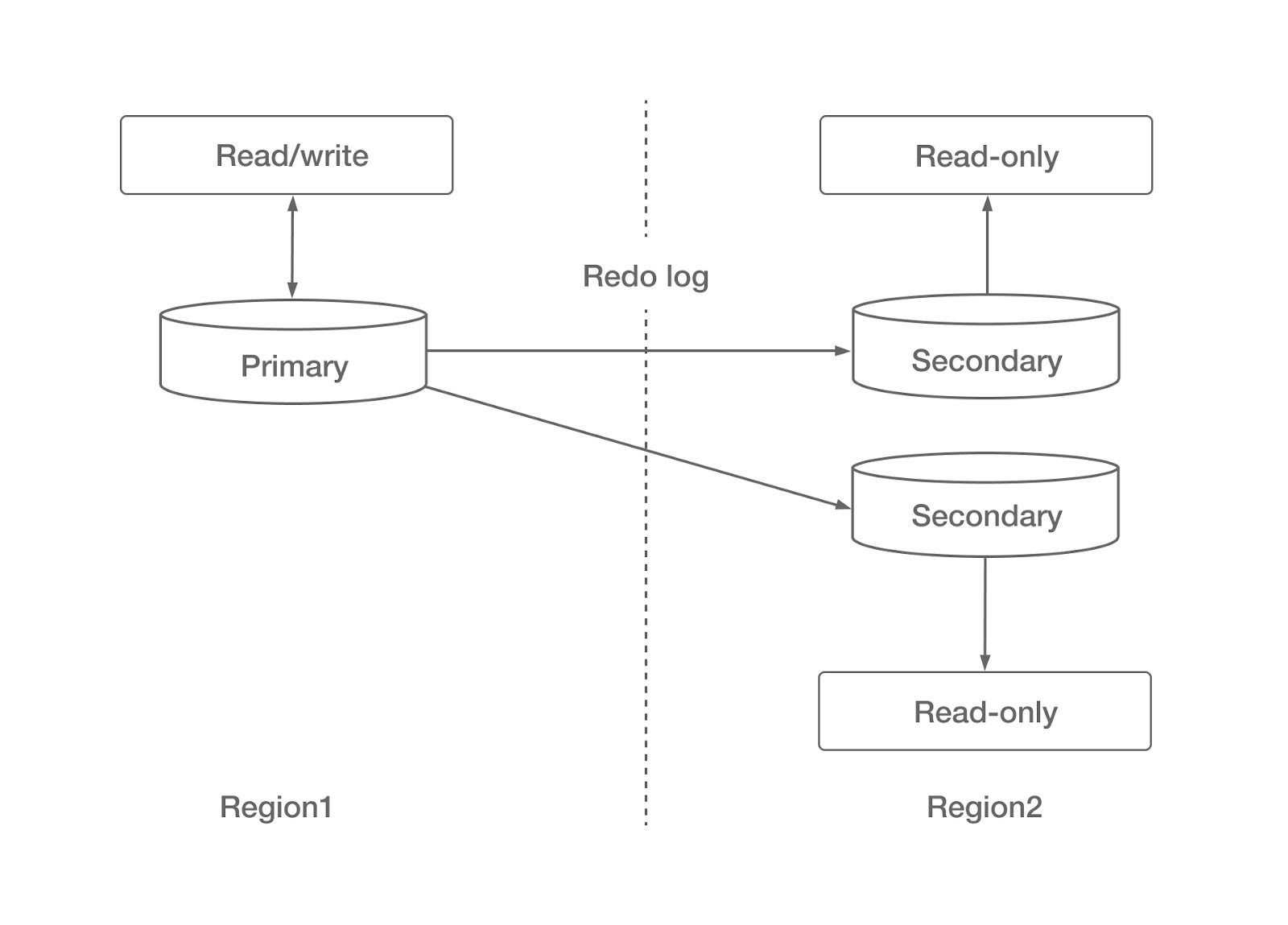
Active-passive DR
Although this solution involves the concept of a cluster, it is still based on a monolithic database. The scalability is limited to read operations; it can’t scale writes. Of course, compared with its predecessor, the RTO is reduced to a few minutes and the RPO a few seconds.
Amazon Aurora, which uses logical replication with cross-region read replicas, is one of the early cloud database services built on this technology.

Aurora logical replication with cross-region read replicas
In recent years, Aurora has built on this design and offered Global Database service. This service uses storage replication technology to asychronously replicate data from a source region to a destination region. If the source region goes down, the service can immediately failover to the backup cluster. RTO can be reduced to a few minutes, and RPO is less than one second.
Multi-Active Disaster Recovery
In multi-active disaster recovery, a database provides at least three read and write service nodes for the same copy of the data, and the database can scale out or scale in based on the workload. The requirements behind this capability are from the widespread internet-scale applications, which requires higher performance, lower latency, higher availability, elastic scalability, and elasticity from a database.
Multi-activeness took shape with traditional sharding databases, which shared data based on one or multiple columns. The sharding solution achieves DR through transaction logs replication. For example, Google once maintained an extremely large MySQL sharding system. This solution offers some level of scalability, but cannot improve the disaster recovery capability as shards increase. The performance will degrade significantly and the maintenance cost will soar. Therefore, sharding is a transitional solution for multi-activeness.
In recent years, shared-nothing databases based on the Raft or Paxos consensus protocol developed quickly. They solved the scalability and availability challenges mentioned above. Key players in the multi-active era include TiDB and CockroachDB. Their databases, along with their DR technologies, make most of the legacy databases and relational database services (RDS) obsolete.
Multi-Active DR With a Distributed Database
Let’s look at multi-active DR as it applies to distributed databases. For example, TiDB is an open-source and highly available distributed database. It divides each table or partition into smaller TiDB regions and stores multiple copies of the data in those TiDB regions on different TiKV nodes. This is called data redundancy. TiDB adopts the Raft consensus protocol, so when the data changes, the transaction commit is only returned when the transaction log is synchronized to the majority of the data copies. This greatly improves database RPO. In fact, in most cases the RPO is 0. This ensures data consistency. In addition, TiDB’s architecture separates its storage and computing engines. This allows users to scale TiDB nodes and TiKV storage nodes in or out as their workloads change.
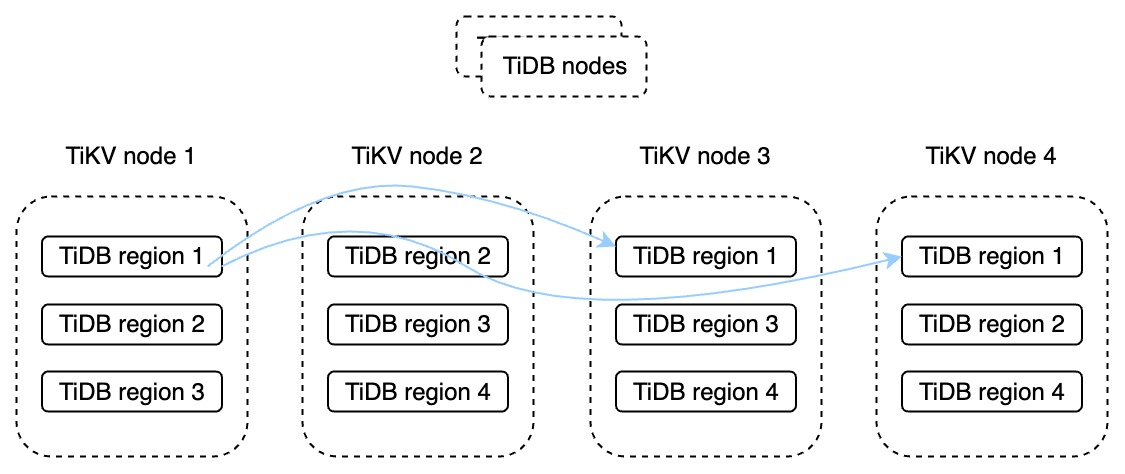
TiDB’s storage architecture
A Typical Multi-Region DR Solution
The following diagram shows how TiDB delivers a typical multi-region disaster recovery solution.
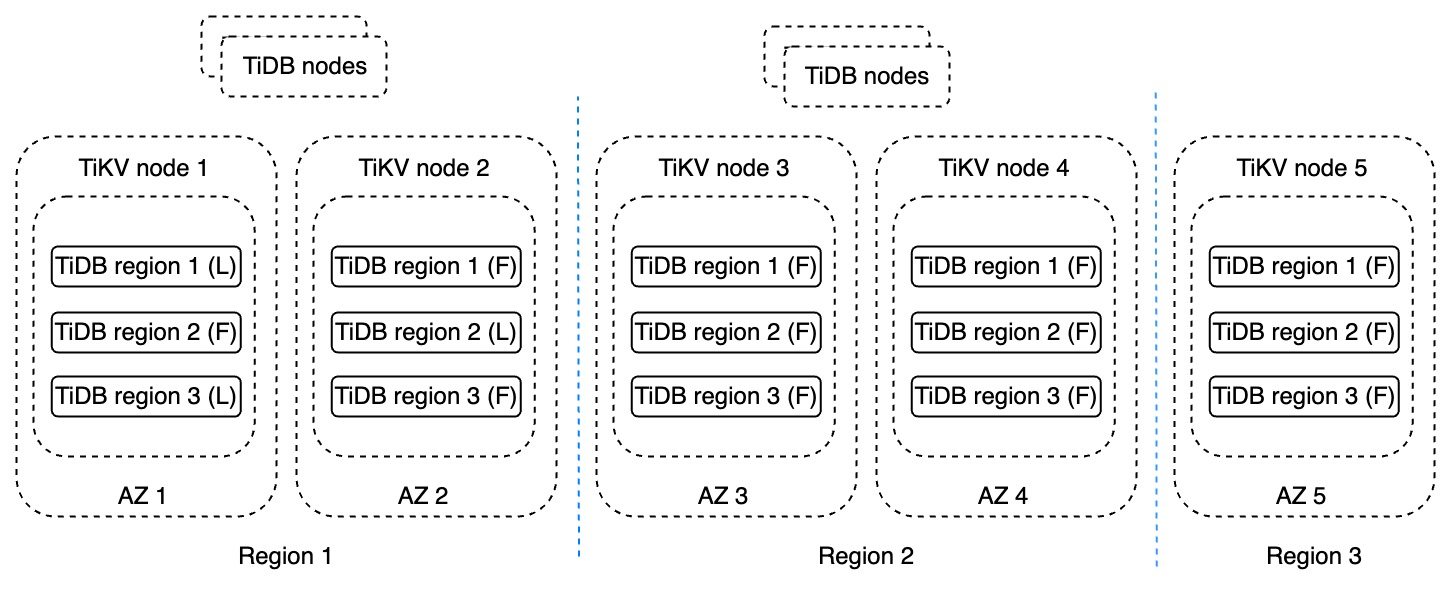
TiDB’s multi-region disaster recovery solution
These are key terms for the TiDB DR architecture:
TiDB region: TiDB’s scheduling and storage unit
Region: two sites or cities.
Availability zone (AZ): an independent HA zone. In most cases, an AZ is two data centers or cities that are closer to each other in a Region.
L: the Leader replica in a Raft group
F: the Follower replica in a Raft group
In the figure above, each Region contains two replicas of the data. They are located in different AZs, and the entire cluster spans three Regions. Region 1 usually processes read and write requests. Region 2 is used for failover after a disaster occurs in Region 1, and it can also process some read loads that are not sensitive to latency. Region 3 is the replica that guarantees consensus can be still reached even when Region 1 is done. This typical configuration is referred to as an “2-2-1” architecture. This architecture not only ensures disaster recovery, but gives the business multi-active capability. In this architecture:
The largest fault tolerance target can be at the Region level.
The writing capability can be expanded.
The RPO is 0.
The RTO can be set to one minute or even less.
This architecture has been frequently recommended by many distributed database vendors to their users as a disaster recovery solution. For example, CockroachDB recommends their 3-3-3 configuration to achieve Region-level disaster recovery; Spanner provides a 2-2-1 configuration for multi-Region deployment. However, this solution won’t guarantee high availability when Regions 1 and 2 are unavailable at the same time. Once Region 1 is completely down, if any storage node on Region 2 has a problem, the system might suffer performance degradation and even data loss. If you require a multi-Region level of FTT, or strict system response time, it is still necessary to combine this solution with transaction log replication technology.
Enhanced Multi-Region DR With Change Data Capture
TiCDC is an incremental data replication tool for TiDB. It fetches data changes on TiKV nodes and synchronizes them with downstream systems. TiCDC has a similar architecture to transaction log replication systems, but it is more scalable and works well with TiDB in disaster recovery scenarios.
The following configuration contains two TiDB clusters. Region 1 and Region 2 together form Cluster 1, which is a 5-replica cluster. Region 1 contains two replicas for serving read and write operations, and Region 2 contains two replicas for quick failover in case of a disaster in Region 1. Region 3 contains one replica for reaching the quorum among the Raft group. Cluster 2 in Region 3 functions as the disaster recovery cluster. It contains three replicas to provide quick failover in the event of a disaster in both Region 1 and Region 2. TiCDC handles the synchronization of data changes between the two clusters. This enhanced architecture can be referred to as 2-2-1:1.
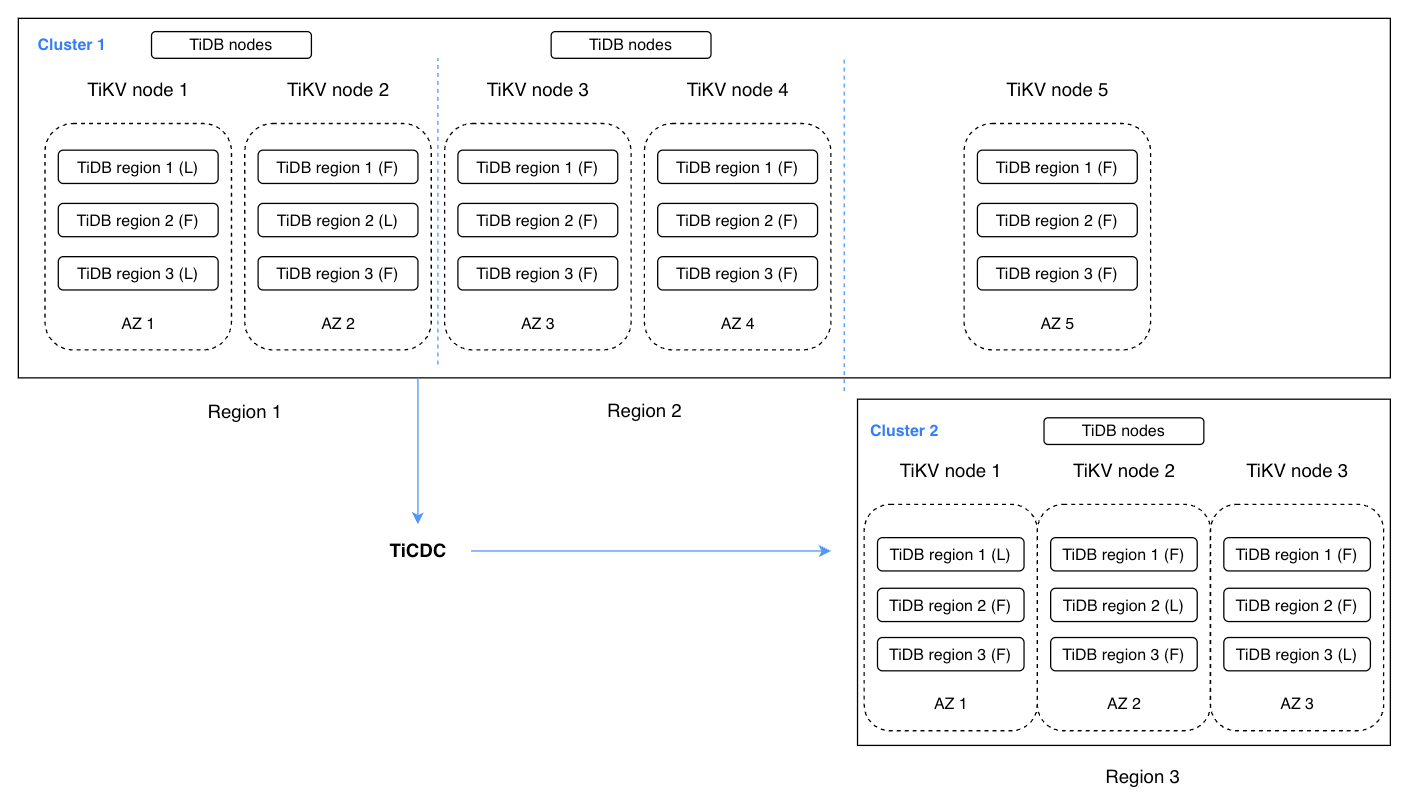
TiDB multi-region DR with TiCDC
This seemingly complex configuration actually has higher availability. It can achieve a maximum fault tolerance target at a multi-region level, with RPO in seconds and RTO in minutes. For a single Region, the RPO is 0 in the event of complete unavailability.
Comparing DR Solutions
In the following table, we have compared the DR solutions mentioned in this article:
TCO |
FTT |
RPO |
RTO |
|
Snapshot-based cross-region data backup and restore by Aurora |
Low |
Region |
Hours |
Hours |
Aurora logical replication with cross-region read replicas |
Medium |
Region |
Seconds |
Minutes |
Aurora Global Database |
Medium |
Region |
< a second |
Minutes |
TiDB (2-2-1) |
High |
Region |
< a second |
Minutes |
TiDB (2-2-1:1) |
High |
Multi-Region |
Seconds |
Minutes |
CockroachDB (3-3-3) |
Higher |
Region |
< a second |
Minutes |
CockroachDB (3-3-3-3-3) |
Very high |
Multi-Region |
< a second |
Minutes |
Summary
After more than 30 years and several distinct stages of development, DR technologies have entered the multi-active phase.
Using a shared-nothing architecture, distributed databases like TiDB combine multiple-replica technology and log replication tools, and move database DR into the multi-region age.
Published at DZone with permission of Allen Gao. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments