An Executive Architect’s Approach to FinOps: How AI and Automation Streamline Data Management
FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value.
Join the DZone community and get the full member experience.
Join For FreeWe have learned to approach FinOps as both a mindset and a set of cloud solution capabilities. Yes, FinOps empowers firms to harness value from the cloud consistently and continuously (20 to 30% savings each year per a recent McKinsey article), but it also yields growth and innovation. To realize cost savings and transformational benefits, be ready to treat your FinOps effort as a critical business priority.
Over the past two years — and more than twenty consulting experiences later — we can summarize a group of issues blocking FinOps' success.
Business executives commit very late to FinOps principles, allowing too much focus, expert staff, and budget directed toward operational and tactical capabilities versus strategic competencies that drive future cloud savings. Teams fail to align the core tenets of FinOps with cloud data management principles, ensuring their success. Next, crucial core skills are not developed or skipped, leading to FinOps capability gaps that become calcified, so the economic advantages of FinOps are not realized.
To avoid those pitfalls, this article will put four FinOps disciplines in place:
- Understanding Cloud Usage and Cost
- Data Analysis and Showback
- Managing Anomalies
- Workload Management and Automation
Point of emphasis – AI and automation in data management allow the right, trusted, complete, hygienic data to drive your FinOps lifecycle. We will pursue this with a toolkit-based approach so your firm has the competencies needed to power your FinOps solution with a battle-tested cloud data management mindset.
As a positive actor in the FinOps public domain, this article abides by the FinOps 4.0 attribution for use terms and conditions.
What Is FinOps?
FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance, technology, and business teams collaborate on data-driven spending decisions. If FinOps is predicated on data-driven decisions, then cloud data management will always be critical for FinOps.
Recall FinOps is also a strategic mandate where teams manage cloud costs effectively and form a consensus on core practices, allowing lines of business (LOBs) to improve ownership of their cloud usage supported by a central best-practices group. Cross-functional teams in engineering, finance, CRM, and product disciplines empower each other to enable faster delivery while concurrently gaining more financial control and predictability.
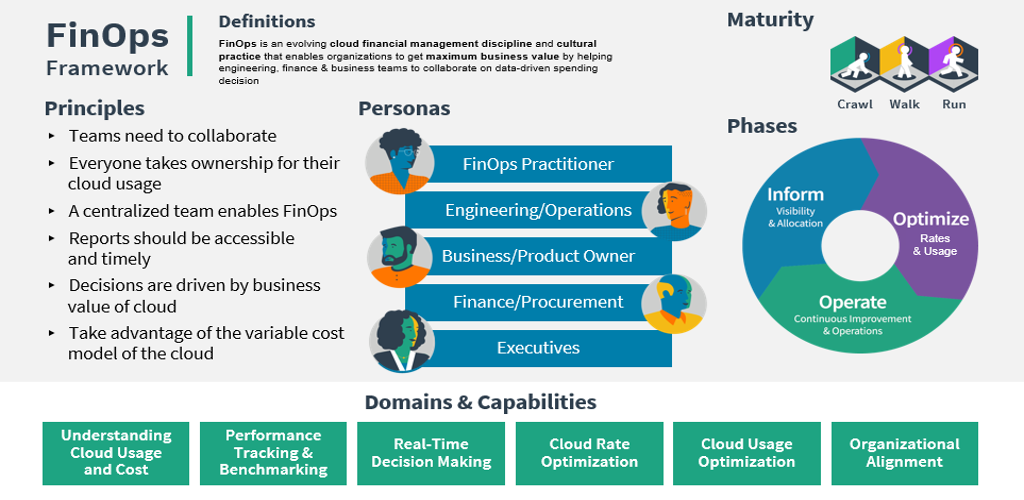
Depiction of the FinOps framework.
Before breaking down the FinOps phases to align to cloud data management goals and practices, it makes sense to share the core concepts driving it:
The FinOps Framework describes:
- Principles that drive our FinOps public domain and practice.
- Personas that FinOps is required to support for stakeholders.
- Best practices and process models allowing FinOps to accomplish this.
- Domains of activity that must consistently be acted upon for successful FinOps practice.
FinOps relies upon a flywheel “looping” lifecycle, which seeks to:
- Inform across teams, stakeholders, and business units (BUs).
- Identify and measure optimization targets.
- Operationalize changes and core capabilities as FinOps goals and metrics evolve.
This flywheel approach espouses a “Crawl, Walk, Run” maturity approach to solving the challenges cloud data management will present to an organization. This framework is also called the FinOps Capability Model or the FinOps Function model.
FinOps provides a simple but very powerful lifecycle to iteratively deliver and improve results: Inform, Optimize, and Operate. The Inform phase establishes visibility and allocation along with benchmarking, budgeting, and forecasting.
The Optimize phase should guide your firm to reach clearly stated, measurable goals. Consider starting at least these two disciplines: Cloud rate optimization and cloud usage optimization.
For cloud rate optimization, one simple principle should guide the approach — your firm rents cloud infrastructure, and cloud hyperscalers own it. Thus, the cloud infrastructure that meets your pricing model goals at a flexible unit cost wins the day. A mix of commitment-based discounts and awareness of historical seasonal variations should drive that pricing model. A core bundle of services vs. specialized (meaning price premium) services should be listed on a roster schedule for all LOBs utilizing the FinOps platform.
Focusing on cloud usage optimization — there is simply no way around variable use models (e.g., executing end-of-quarter financial summary reports vs. start-of-quarter limited use). So, the question comes to the accurate mapping of workloads to optimized compute stacks based on autoscaling analysis and shutdown of idle resources. Fortunately, elastic cloud computing clusters are designed exactly for this purpose. Controlling cloud costs and delivering timely business value creates a balancing act. So, request feedback from your IT operations and business partners early and often to ensure success here. FinOps is a flexible framework where your executive sponsors must consistently guide and prioritize the key outcomes for your teams.
The Operate phase is about reaching predictability for unit economics. That boils down to managing anomalies plus workload management and automation for FinOps.
Simply put, anomaly management is the ability to detect, specify, alert, and manage unexpected cloud cost events in a timely manner to reduce detrimental impact to the business, cost or otherwise. Managing anomalies typically involves the use of tools or reports to identify unexpected spending, the distribution of anomaly alerts, and the investigation and resolution of these anomalies. So now is the right time to consider:
- What tools provide automation, alerts, and AI to surface these anomalies — on time and consistently?
- Who in my FinOps structure should be responsible for applying those tools for a measurable result?
- What tool-driven process will dashboard the results for reliable data analysis and show back?
- How many sample sets across teams (two weeks, six months) are required to differentiate between predictable periodic variances and actual anomalies? Avoid the trap of making authoritative decisions on too small a time sample or too few of your teams — this is very important! Now, per the figure below, an uptick in metadata scanning for a Fortune 1000 firm is a predictable variance to plan for, not an outlier for anomaly management:
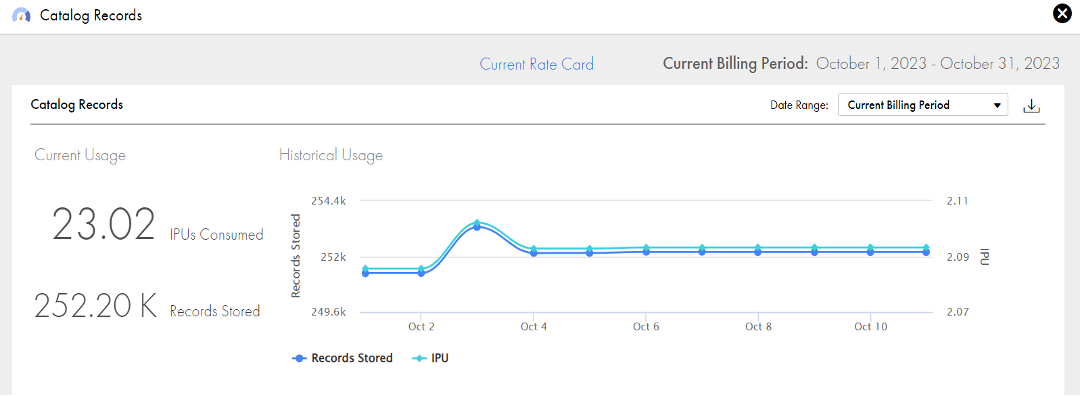
Depiction of increased metadata cloud platform usage.
Workload management and automation demand both a practical approach and metric-driven repeatable results.
It is focused on running data tasks only when required and creating mechanisms that automatically adjust what computing resources are running at any given time. A key goal is to provide FinOps teams the ability to adjust to seasonal demand – or ad-hoc fluctuation in demand most efficiently – but also optimize cloud usage through the dynamic measurement of workload demand and provisioning capacity. It makes sense to surface some core requirements to reach this desired state:
- How is resiliency supported during job execution – making workloads fault-tolerant on cloud architectures?
- Does that same solution support UI-driven and API-driven scheduling so the Operate phase is not purely people-powered?
- Is elastic processing supported for highly varied workloads on both self-service clusters and fully managed clusters (e.g., Azure Kubernetes Services [AKS])?
- Is massive processing supported on cloud serverless computing, allowing workload management, infrastructure management, and workload automation to be owned by one provider billing a single cost?
- Can that same platform surface right-time metadata to support data analysis and show back – and periodic analysis to reach cloud rate optimization and cloud usage optimization?
From the above, you can see the complex questions aggregate very quickly. Now, picture asking IT operations, business continuity officers, and enterprise architects, “How do we plan for and design one solution for this?” The schematic below depicts some core capabilities to address workload automation and management challenges.

Key capabilities addressing workload automation and management for FinOps.
Benefits of Effective FinOps Implementation
The below list combines our 2022-23 consulting experiences on FinOps benefits, plus a valuable Harvard Business Review Article on the same:
- Decisions are driven by funded measurable business value, not subjective IT outcomes.
- Cloud unit economics are realized through FinOps for all participants.
- Requires teams to build, measure, and refactor cloud cost optimization as needed to reach cloud unit economics.
- Executive sponsorship with stated goals was granted to FinOps; it exists to meet those measurable business goals.
Business owners are required to “opt-in” to gain FinOps outcomes following defined practices. All parties' organizations gain confidence to drive business cloud investment with timely metrics of where a firm realizes the greatest value from their cloud investments.
- Cloud consumption patterns become more efficient, resulting in tied to revenue generation, digital transformation, or other business objectives.
- Non-technical teams gain greater competency in known cost, governance, and expertise constraints before submitting projects to operate.
Recall we are not tackling the entire landscape of FinOps in this article. The goal is to build an automated and AI-driven data management toolkit to enable FinOps. The next logical step is to outline FinOps challenges through the lens of data management.
Challenges in FinOps
Discussion of Common Obstacles and Issues in FinOps
Read this brief list of stubborn challenges known to hinder FinOps success – drawn from experiences at over twenty (20) Fortune 1000 firms – when cloud data management practices are not in place to support FinOps:
- Cannot enforce measurable “opt-in” enterprise-wide cloud cost controls and governance.
- Lack of right-time reporting mechanism for stakeholders who surface critical data management concerns.
- Cannot manage anomalies in data, cloud costs, cloud usage, and reporting.
- Inconsistent cloud policy and governance with voting rights to provide cost savings and measurable business outcomes.
- The lack of hardened data residency rules means one region can move, transform, and access data, but another cannot.
- Poor cloud data access management (DAM) blocks stakeholders from having access to the right data at the right time.
- Per the list above - the lack of cloud platform adopted processes and project deliverables causes executive sponsors to disengage from FinOps efforts.
So, if your goal is “north stars” that guide the conduct and principles of a FinOps practice, less lofty disciplines, such as practices and capabilities-driven from those principles, must be established at your firm. We will now distill the above concerns and FinOps tenets into a decision matrix:
Need, obstacle, or issue faced |
FinOps tenet(s) |
FinOps area |
Deliverable solution options within FinOps |
Adopting measurable “opt-in” enterprise-wide cloud cost controls and governance. |
Domains |
Yes – Measuring Unit Costs, Managing Shared Costs, Managing Anomalies, Forecasting. |
|
Right-time reporting mechanism for stakeholders surfacing key concerns to address. |
Capabilities |
Yes - Data Ingestion and Normalization capability. Also, Chargeback and IT Finance Integration. |
|
Managing anomalies in data, cloud costs, cloud usage, and reporting. |
Capabilities |
Yes - Data Analysis and Show back, Cost Allocation, Forecasting, Workload Management and automation, Cloud Policy and Governance, Resource Utilization and efficiency. |
|
Establish cloud policy and governance with voting rights to provide cost savings and measurable business outcomes. |
Workload Management and Automation, Cloud Policy and Governance |
Capabilities |
Yes – codify a clear statement of intent describing the execution of cloud-centric activities in accordance with a business-aligned repeatable model. |
Note: If the need, obstacle, or issue faced cannot be addressed in FinOps with data management principles itself — it is not pursued in this article. FinOps and AI-driven data management will not address “teams needing to collaborate” by themselves.
As mentioned above, here are some items to consider for the Optimize phase: How can workloads be planned to pivot toward cost-reduced computing rather than on-demand? Where can Spark serverless compute reduce onerous performance tuning but still meet runtime goals? Finally, which solution leaders provide all-inclusive AI-driven cloud workload and infrastructure optimization using metadata-driven workload analysis to quantify the optimizations?
How To Overcome FinOps Challenges
To start attacking the above FinOps needs, your team will need to look for a comprehensive platform that can repeatedly address the challenges within the disciplines that FinOps provides.
The schematic below is not a “final state” answer to the FinOps challenges matrix given above, but it starts to calibrate your thinking about answering FinOps challenges within a single platform approach.

Schematic depicting logical platform needs in cloud data management for FinOps.
Your firm will need to propose a go-forward FinOps platform (with automation and AI-driven data management) to bring an understanding of cloud usage and costs, data analysis and show back, managing anomalies, and workload automation into line. Predictability, forecasting, managing shared costs, and measuring unit cost outcomes can only come from a platform built to support them. Now, we can turn to solving the cloud data management concerns for FinOps.
Role of Automation and AI-Driven Data Management to Enable FinOps
AI in Data Management
Realize your firm cannot proceed to the Optimize and Operate FinOps phases when data management (starting from data quality) is not in an acceptable state.
For FinOps-driven organizations seeking to optimize cloud costs and improve operational efficiency, AI-driven solutions (such as Large Language Models [LLMs]) play a pivotal role in sustainable data management. By leveraging advanced algorithms and machine learning (ML) techniques, AI systems can sift through vast volumes of data to identify patterns, anomalies, and discrepancies, ensuring data accuracy, completeness, and integrity. But this data must be of high quality to form the foundation for precise data show back and analysis or for deeper cloud usage cost analysis and anomaly management.
Consider this scenario: A FinOps firm has two teams: one incurs $1MM in infrastructure cost with deliverable hygienic data, and the other incurs $1MM in infrastructure cost with anomalous undeliverable data (but their ETL completes). You will be making flawed decisions from your data analysis for FinOps in at least two areas of concern:
- The cloud computing executing against this spurious data "will have to be run again" to meet business objectives.
- FinOps analysts will incur invalid unit costs if half the jobs execute on non-hygienic, undeliverable data.
It is that simple.
AI will generate biases if it is built upon flawed or incomplete data, causing negative consequences on your decisions in FinOps, data show back and analysis, and basically any data-driven decisions.
We agree with Forbes’ assertion that GenAI relies upon the datasets it is trained upon. Flaws in training input datasets — whether using an insufficient volume or scope of data or having severe limits in the timeframe — will eventually surface through inaccurate training models and operational outcomes for AI in daily use. So, the FinOps task at hand is defining, positioning, and integrating a cloud-native data quality solution to ensure these problems are addressed and reduced where possible. Otherwise, flawed data driving erroneous decisions will block the organization’s key FinOps outcomes discussed in the introduction.
Using LLMs to drive AI results raises the risk of hallucinations in the data being generated. Rely on this logical process to block and uncover hallucinations in GenAI:
- Clinically inspect and analyze (we used data profiling) that data sources for GenAI meet core expectations.
- Next, check and measure those profiled sources in data quality dimensions on a scorecard.
- Repeatedly require (and absorb) input from stakeholders on this training data from the scorecard.
- Challenge FinOps to participate in their own data quality process – both GenAI training inputs and overall business data.
- If GenAI input data is not fit for FinOps use, take necessary action to correct this.
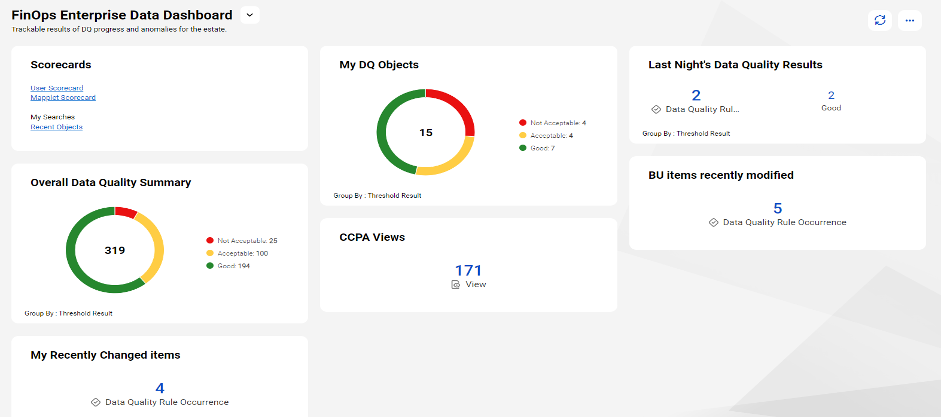
Holistic dashboard using AI for team inspection, analysis, and action on poor data quality and hygiene.
By design, added benefits exist by putting an acceptance barrier ahead of your GenAI data use and outcomes for FinOps teams. Reuse the exact same process to block anomalous business-generated data from entering the FinOps pipeline.
Use Automation First to Bolster Your Data Quality
Regarding the removal of bias, hallucinations, and faulty data content — this item clearly tops the list. Firms need automated prescriptive rules (and data quality suggestions) driven from a robust library of dozens of algorithms updated without data product owner or data steward intervention.
Poor data quality and AI bias significantly escalate operational and decision-making burdens for FinOps, specifically in cost allocation, forecasting, and managing anomalies capabilities. Biased data can skew resource attribution, leading to uneven financial assessments and inaccurate budgeting. This problem is exacerbated during forecasting, where biased algorithms, driven by flawed data, generate inaccurate predictions and hamper the ability to plan budgets effectively. Additionally, biased models surface real risk as they may misinterpret genuine anomalies, creating false alerts or overlooking actual irregularities, impeding your firm’s accurate identification of data, process, and financial discrepancies. Simply put, the operational and decision-making challenges within FinOps become magnified due to poor data quality and AI bias, hindering the efficiency and accuracy of FinOps capabilities reliant on accurate enterprise data.
The examples below briefly examine a practical battle-tested approach to utilize automation with rule suggestion algorithms to shore up enterprise-wide data quality, providing some protection against AI-driven bias.

Depiction of recommended data quality rules guiding stewards and data SMEs to assist data standardization and correction.
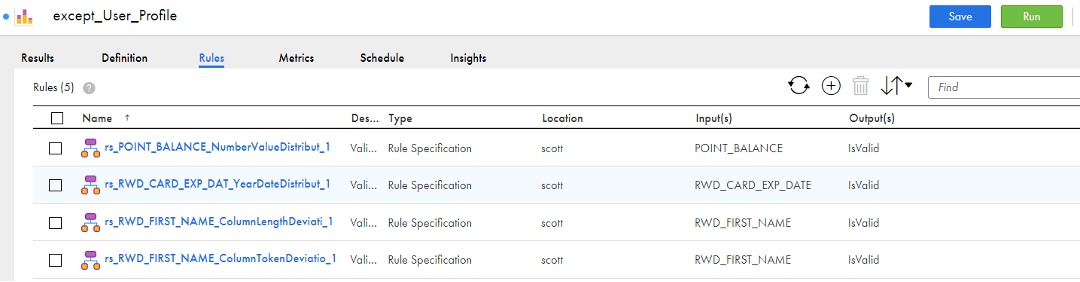
Depiction of accepted data quality rules auto-generated to execute data standardization and correction.
The above points to one example of a toolset exploiting automation and AI efficiently in data quality to benefit FinOps with surety that your teams can be repeatable, stable, and successful in your Operate phase.
It helps to think in this acceptance-based format, scrutinizing assisted, automated, and AI-driven data quality. If the measurable dimensions of data quality do not gain improvement from the toolset, FinOps will not benefit, so move on to another toolset. The firmwide FinOps managing anomalies capability will not mature unless data stewards select and operationalize the right cleansing rules. AI has impactful value in removing the time and expertise burden in resolving known hygiene anomalies (case, whitespace, spelling) through guided rule automation. Also, firmwide workload management and automation cannot be realized with anomalous data that data consumers reject as a data product. Using FinOps terms — these two disciplines will stay at “crawl” until the data quality house is in order.
AI in Automating Data Classification
In 2023, at scale, ML-augmented data catalogs will allow firms to streamline and automate common data curation processes. These include data tagging, classification, and the process of associating business glossary terms to technical data assets. It is essential to avoid costly or error-prone human intervention where structural complexity (Parquet, AVRO, XML) and lack of inferred or direct lineage can block business sponsors or data analysts from answering these important concerns:
- Is enough trusted, accurate data collected (and enriched) on key business entities such as customers, accounts, and households?
- Are there complex entities (e.g., a residential customer vs. a corporate customer) that a weaker AI solution cannot recognize?
Experience is a valued teacher. As Fortune 1000 BUs learn more about their data and what it contains, more daunting demands will surface on “what we must scan and classify,” including;
- Ten thousand Teradata instances;
- Fifty-billion financial risk positions, and
- Six hundred banking systems.
Natural language processing (NLP) and Jaccard distance can be used to:
- Accurately align varying input models to standard metadata models for scanning.
- Quickly surface, classify, and offer data similarity on complex entities your FinOps will often utilize
- Provide trustworthy similarity scores on very dissimilar data types and data structures.
- Support simple text searching after those scans so the FinOps user base can find desired relevant data without coding.
Data similarity refers to assigning matching scores to comparable data sets, prompting your FinOps users (and stewards, business SMEs) to curate and select the most relevant data for their purpose. Having stronger, timely metadata and data classification instills confidence in BU consumers, executive stakeholders and cloud data engineering teams that you are prepared for the Optimize and Operate phases.
AI and Active Metadata Tags
Before stakeholders can inspect and assess their FinOps data assets, collaborate on those assets, and make decisions on them – you require an AI-driven cloud data management stack with active metadata yielding these standard capabilities or answers:
- Automated association of rules and policy terms to your data attributes for more consistent FinOps policy outcomes.
- Standard roles for stakeholders in repeatable metadata processes.
- Who has ownership rights, voting rights, and policy change rights on data assets and processes?
- Where have stakeholders accepted their assigned role (on an updated pie chart/bar graph)?
- What downstream users and roles consume the data?
- What processes (ETL, data integration, data ingestion wizards) transform the data?
- Notification that new or changed data assets have arrived per their request.
The above cannot be manually maintained by data stewards, metadata owners, and technical SMEs on an ongoing basis. FinOps operation demands robust AI capabilities (with periodic microservices updates) for stable results. The asset volume, data volume, data anomalies, and rate of change feeding the FinOps lifecycle prohibits a manual or single-vendor lock-in approach.
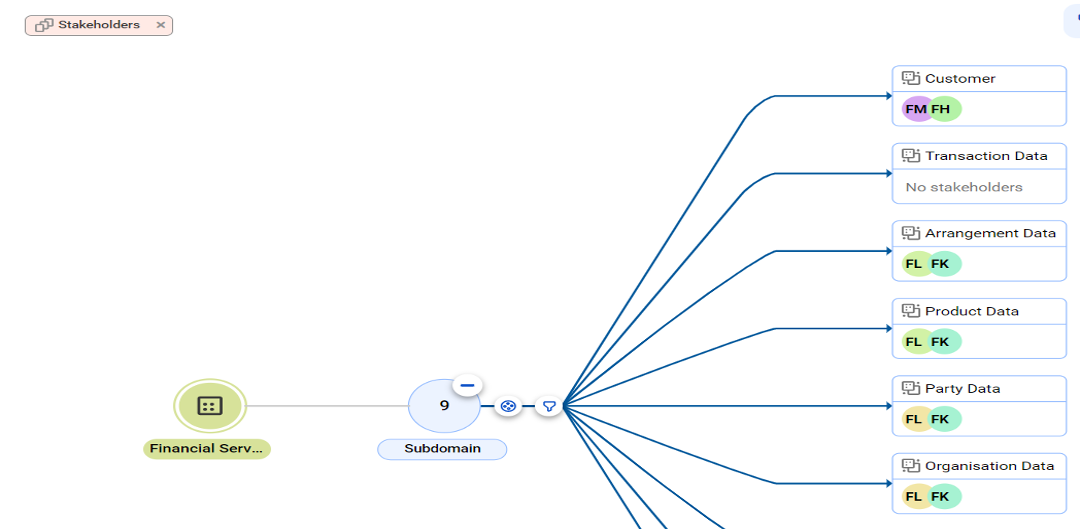
Depiction of domain-driven data hierarchy depicting downstream ownership by stakeholders.
Remember, FinOps stakeholders will only pay chargebacks if they are certain their valued, trusted, and timely data completed a value-added process whereby they can share, consume, and understand their data, driving accurate decisions relevant to their business delivery needs. Automation and AI in your cloud data management are critical building blocks to achieving this.
Focusing on the Optimize and Operate phases, your FinOps team should now be ready to:
- Assign initial chargebacks for computing, storage, and metadata.
- Be able to identify dormant or irrelevant data assets to exclude from FinOps.
- Be able to filter anomalous or incomplete data not ready for FinOps downstream usage.
- Consider data analysis and show back for FinOps from the above AI-driven practices.
Opinions expressed by DZone contributors are their own.
Comments