Hiding Data in Cassandra
In this article, take a walk through 3 basic approaches to learn how to roll your own data masking for Cassandra-compatible databases using off-the-shelf tools.
Join the DZone community and get the full member experience.
Join For FreeSometimes you need to control access to the data in your databases in a very granular way - much more granular than most databases allow.
For instance, you might want some database users to be able to read only the last few digits of some credit card number, or you may need certain columns of certain rows to be readable by certain users only. Or maybe you need to hide some rows from some users under specific circumstances.
The data still needs to be stored in the database, we just need to restrict who can see certain parts of that data.
This is called data masking, and I've already talked about the two main approaches: static vs. dynamic data masking in a previous article.
In this article, I'll show you how to roll your own dynamic data masking solution for Cassandra and Cassandra-compatible databases such as AWS Keyspaces, Azure Cosmos DB, and DataStax DSE, using a couple of off-the-shelf tools.
What Cassandra Can Do on Its Own
When it comes to hiding data, Cassandra provides table-level GRANT permissions, but nothing more fine-grained than that. Other Cassandra-compatible products, such as DataStax DSE, do provide some row- and column-level security, but even that has significant limitations.
To narrow down how people access some tables, most relational databases offer the concept of views.
Cassandra has materialized views, which are tables that are derived from other tables. Unfortunately, for materialized views, among many other restrictions, Cassandra requires that the columns must be the naked columns from the base table. This, and the other restrictions, means that materialized views are only tangentially useful for data masking, and cannot cover the vast majority of use cases.
You might think you're stuck at this point. The fine folks in the Cassandra team are in fact working on a data masking solution, but that's still some ways away, and in any case, it will be limited.
There is another option: using a programmable database proxy to shape the queries and the corresponding result sets.
How Would a Proxy Help?
The idea is simple: we introduce a programmable proxy between the database clients and the database server(s).
We can then define some simple logic in the proxy, which will enforce our data masking policies as the network traffic goes back and forth (through the proxy) between clients and servers:
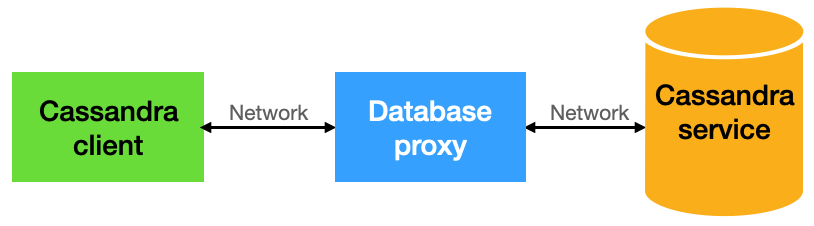
Standing up a database proxy is easy: it's just a Docker container, and we can set up the database connection in just a few clicks.
The database clients then connect to the proxy instead of directly to the database. Other than that, the clients and the server will have no idea that they are talking to each other through a proxy. Because the proxy works at the network level, no changes are required to either side, and this works with any Cassandra-compatible implementations such as AWS Keyspaces and Azure CosmosDB.
Once the proxy is in place, we can define filters in the proxy to shape the traffic. For data masking, we have three possibilities:
- Reject invalid queries
- Rewrite invalid queries
- Modify result sets
Let's take a look at each approach.
Rejecting Queries
Just because a database client sends you a request doesn't mean that you have to execute it. The proxy can look at a query and decide to reject it if it does not obey our access requirements.
There are two main ways to do this:
- Limiting queries to a list of pre-approved queries, possibly depending on the user, the user's IP address, or any other factor
- Examining the query before it gets executed, and rejecting it if it does not satisfy certain criteria
Query Control
Enforcing a list of pre-approved queries is called query control, and I have covered that topic in a previous article. It's a simple idea: you record all the queries during a period of time (like during testing), then you only allow those queries after that. Any query that is not on the list gets rejected (or given an empty result set if we want to be more sneaky).
This is a solid approach, but it only works for some use cases. For instance, this is not a viable solution if your queries are not 100% predictable. Still, it's a good tool to have in your toolbox.
Vetting Queries
A more subtle approach consists of examining the queries and determining whether they are acceptable or not.
This is of course trickier - people can be very clever - but Cassandra's query language CQL is not as complex as typical SQL languages, making this a practical solution.
For instance, we could decide that we don't want certain users to have access to the phones column in our customers table. In that case, we could simply reject any queries on that table that either specify the phones column, or that try to use the * operator to get all columns.
This is easily done thanks to Gallium Data's CQL parser service, which can parse any CQL command and tell us exactly what that command does, and which tables/columns are involved.
In the proxy, our filter will:
- Get the CQL from the query or prepared statement
- Send it to the parser service to analyze it
- If the CQL refers to the
phonescolumn, reject the request - Otherwise let the query proceed to Cassandra
See the hands-on tutorial for this article for all the details.
Rewriting Queries
A more flexible approach is to modify incoming queries so that they satisfy our criteria.
For instance, let's say we still want to restrict access to the column phones in the table customers.
Again, we can use the CQL parser service to determine whether an incoming query uses this column, or uses * to request all columns.
If the query does use * to request all columns, the safest thing to do is to reject the query. It would be tempting to think that we can replace the asterisk with the names of the columns, but that is actually quite difficult to do correctly, as illustrated by this perfectly valid query:
SELECT /* all */ * FROM credit_card_txsIf the query uses the phones column, we can replace it with something that will hide the data as we wish.
Let's say we want to hide the phones column completely. You might think that you can rewrite the query from:
SELECT id,
country,
first_name,
last_name,
phones
FROM customersto:
SELECT id,
country,
first_name,
last_name,
'****' as phones
FROM customersThat seems reasonable, but sadly, Cassandra does not support this:
InvalidRequest: Error from server: code=2200 [Invalid query]
message="Cannot infer type for term '****' in selection clause
(try using a cast to force a type)"Thankfully, there is a slightly ugly workaround:
SELECT id,
country,
first_name,
last_name,
blobAsText(textAsBlob('****')) as phones
FROM customersWe could do somewhat better using user-defined functions, if your Cassandra implementation supports them.
We can thus easily create a filter in the proxy that will rewrite the query to mask the value of the phones column (see the hands-on tutorial linked previously for all the details).
Let's test that:
cqlsh:demo> SELECT id, country, first_name, last_name, phones FROM customers;
id | country | first_name | last_name | phones
----+---------+------------+---------------+---------
23 | WF | Wanda | Williams | ****
5 | ES | Eric | Edmunds | ****
10 | JP | Juliet | Jefferson | ****
16 | PE | Patricia | Pérez | ****
etc...If you need to hide only portions of a column, and your Cassandra implementation does not allow for user-defined functions, your only option is to modify result sets - let's look at that now.
Modifying Result Sets
For the ultimate in power and flexibility, we can modify result sets on their way back to the database clients:
- We can modify individual columns in specific rows.
- We can remove entire rows from result sets.
- We can also insert new rows in result sets, change the shape of result sets, etc., but that's beyond the scope of this article.
Changing a column in a row is usually trivial with a few lines of code in a filter, e.g.:
let phones = context.row.phones;
if (phones && phones.home) {
phones.home.phone_number = "####";
}Let's try it out:
cqlsh:gallium_demo> SELECT id, country, last_name, phones FROM customers;
id | country | last_name | phones
----+---------+---------------+-----------------------------------------------------
23 | WF | Williams | {'home': {country_code: 123, phone_number: '####'}}
5 | ES | Edmunds | {'home': {country_code: 55, phone_number: '####'}}
16 | PE | Pérez | {'home': {country_code: 116, phone_number: '####'}}
etc...Notice how much more precise this is: we're not blotting out the entire column, we're only hiding parts of it.
Removing a row from a result set is also easy. It can be done either by setting parameters in the filter, or for more complex cases, in filter code, e.g.:
// Hide customers whose home phone number is in Japan
let phones = context.row.phones;
if (phones && phones.home && phones.home.country_code === 81) {
context.row.remove();
}Again, you can see this in action in the hands-on tutorial for this article.
Nothing has changed in the database: we're only affecting the data as it travels back to the Cassandra client.
In Summary
We've looked at three general techniques for hiding data in Cassandra with a proxy:
- Rejecting queries that try to access secret data
- Modifying queries so they do not show secret data
- Modifying result sets to hide secret data
Rejecting queries is a blunt but effective tool. It might be sufficient for many use cases.
Modifying queries has the advantage of performance: only one packet (the query) has to be modified, and the rest can work as usual. However, this technique can only work for some types of data masking requirements.
Modifying result sets, on the other hand, is slightly more expensive, but it gives you complete control: you can change literally anything in the result set, no matter how fine-grained the required changes are.
These techniques are not mutually exclusive: many solutions will involve a combination, perhaps in conjunction with other approaches such as fine-grained security (if available) or the data masking solution that will someday be available in Cassandra.
But for complete power and flexibility, you can't beat a programmable database proxy.
Published at DZone with permission of Max Tardiveau. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments