Guide to Partitions Calculation for Processing Data Files in Apache Spark
Spark chooses the number of partitions implicitly while reading a set of data files into an RDD or a Dataset. This implicit process of selecting the number of portions is described comprehensively in this story.
Join the DZone community and get the full member experience.
Join For FreeThe majority of Spark applications source input data for their execution pipeline from a set of data files (in various formats). To facilitate the reading of data from files, Spark has provided dedicated APIs in the context of both, raw RDDs and Datasets. These APIs abstract the reading process from data files to an input RDD or a Dataset with a definite number of partitions. Users can then perform various transformations/actions on these inputs RDDs/Datasets.
Each of the partitions in an input raw RDD or Dataset is mapped to one or more data files, the mapping is done either on a part of a file or the entire file. During the execution of a Spark Job with an input RDD/Dataset in its pipeline, each of the partition of the input RDD/Dataset is computed by reading the data as per the mapping of partition to the data file(s) The computed partition data is then fed to dependent RDDs/Dataset further into the execution pipeline.
The number of partitions in an input RDD/Dataset (mapped to the data file(s)) is decided based on multiple parameters to achieve optimum parallelism. These parameters carry a default value and can also be tweaked by the user. The number of partitions decided in the input RDD/Dataset could affect the efficiency of the entire execution pipeline of the Job. Therefore, it is important to know, how the number of partitions is decided based on certain parameters in case of an input RDD or a Dataset.
Number of partitions when Dataset APIs used for reading data files: Multiple APIs are provided for reading data files into a Dataset, each of these APIs is called on an instance of a SparkSession which forms a uniform entry point of a Spark application since version 2.0. Some of these APIs are shown below:
xxxxxxxxxx
*File Format specific APIs*
Dataset<Row> = SparkSession.read.csv(String path or List of paths)
Dataset<Row> = SparkSession.read.json(String path or List of paths)
Dataset<Row> = SparkSession.read.text(String path or List of paths)
Dataset<Row> = SparkSession.read.parquet(String path or List of paths)
Dataset<Row> = SparkSession.read.orc(String path or List of paths)
*Generic API*
Dataset<Row> = SparkSession.read.format(String fileformat).load(String path or List of paths)
'path' in above APIs is either actual file path or directory path. Also, it could contain wildcard, such as '*'.
There are more variants of these APIs which includes the facility of specifying various options related to a specific file reading. The full list can be referred to here.
After looking at the APIs for reading data files, here are the config parameters list which affects the number of partitions in the Dataset representing the data in the data files:
xxxxxxxxxx
(a)spark.default.parallelism (default: Total No. of CPU cores)
(b)spark.sql.files.maxPartitionBytes (default: 128 MB)
(c)spark.sql.files.openCostInBytes (default: 4 MB)
Using these config parameters values, a maximum split guideline called as maxSplitBytes is calculated as follows:
xxxxxxxxxx
maxSplitBytes = Minimum(maxPartitionBytes, bytesPerCore)
where bytesPerCore is calculated as:
xxxxxxxxxx
bytesPerCore =
(Sum of sizes of all data files + No. of files * openCostInBytes) / default.parallelism
Now using ‘maxSplitBytes’, each of the data files (to be read) is split if the same is splittable. Therefore, if a file is splittable, with a size more than ‘maxSplitBytes’, then the file is split in multiple chunks of ‘maxSplitBytes’, the last chunk being less than or equal to ‘maxSplitBytes’. If the file is not splittable or the size is less than ‘maxSplitBytes’, there is only one file chunk of size equal file size.
After file chunks are calculated for all the data files, one or more file chunks are packed in a partition. The packing process starts with initializing an empty partition followed by iteration over file chunks, for each iterated file chunk:
- If there is no current partition being packed, initialize a new partition to be packed and assign the iterated file chunk to it. The partition size becomes the sum of chunk size and the additional overhead of ‘openCostInBytes’.
- If the addition of chunk size does not exceed the size of current partition (being packed) by more than ‘maxSplitBytes’, then the file chunk becomes the part of the current partition. The partition size is incremented by the sum of the chunk size and the additional overhead of ‘openCostInBytes’.
- If the addition of chunk size exceeds the size of current partition being packed by more than ‘maxSplitBytes’, then the current partition is declared as complete and a new partition is initiated. The iterated file chunk becomes the part of the newer partition being initiated, and the newer partition size becomes the sum of chunk size and the additional overhead of ‘openCostInBytes’.
After the packing process is over, the number of partitions of the Dataset, for reading the corresponding data files, is obtained.
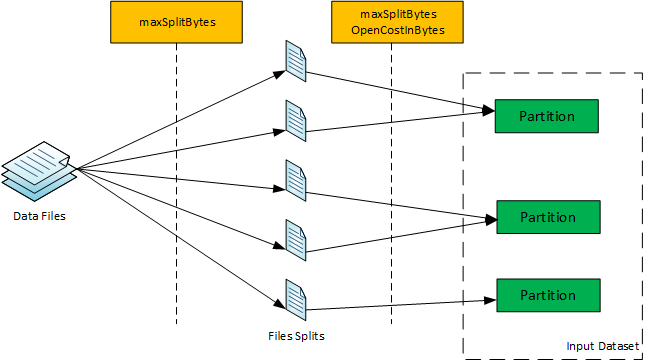
Although the process of arriving at the number of partitions seems to bit complicated, the basic idea is to first split the individual files at the boundary of maxSplitBytes if the file is splittable. After this, the split chunks of files or unsplittable files are packed into a partition such that during packing of chunks into a partition if the partition size exceeds maxSplitBytes, the partition is considered complete for packing and then a new partition is taken for packing. Thus, a certain number of partitions are finally derived out of the packing process.
For illustration, here are some examples of arriving at the number of partitions in the case of Dataset APIs:
(a) 54 parquet files, 65 MB each, all 3 config parameters at default, No. of core equal to 10: The number of partitions for this comes out to be 54. Each file has only one chunk here. It is obvious here that two files cannot be packed in one partition (as the size would exceed ‘maxSplitBytes’, 128 MB after adding the second file) in this example.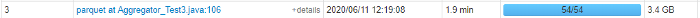


It should be noted that while evaluating the packing eligibility for the file chunk, overhead of openCost is not considered, overhead is considered only while incrementing the partition size after the file chunk is considered for packing in the partition.
(d) 54 parquet files, 40 MB each, maxPartitionBytes set to 88 MB, other two configs at default values., No. of core equal to 10: The number of partitions comes out to be 27 for this case instead of 18 as in (c). This is due to the change in the value of ‘maxPartitionBytes’. The 54 partitions can be easily reasoned based on file split and packing process as explained above.
(e) 54 parquet files, 40 MB each, spark.default.parallelism set to 400, the other two configs at default values, No. of core equal to 10: The number of partitions comes out to be 378 for this case. Again 378 partitions can be easily reasoned based on file split and packing process as explained above.

Following APIs are provided for reading data files into an RDD, each of these APIs is called on the SparkContex of a SparkSession instance:
xxxxxxxxxx
*SparkContext.newAPIHadoopFile(String path, Class<F> fClass, Class<K> kClass, Class<V> vClass, org.apache.hadoop.conf.Configuration conf)
*SparkContext.textFile(String path, int minPartitions)
*SparkContext.sequenceFile(String path, Class<K> keyClass, Class<V> valueClass)
*SparkContext.sequenceFile(String path, Class<K> keyClass, Class<V> valueClass, int minPartitions)
*SparkContext.objectFile(String path, int minPartitions, scala.reflect.ClassTag<T> evidence$4)
In some of these API, a parameter ‘minPartitions’ is asked while in others it is not. If it is not asked, the default value is taken as 2 or 1, 1 in the case when default.parallelism is 1. This ‘minPartitions’ is one of the factors in deciding the number of partitions in the RDD returned by these APIs. Other factors are the value of the following Hadoop config parameters:
xxxxxxxxxx
minSize (mapred.min.split.size - default value 1 MB)
blockSize (dfs.blocksize - default 128 MB)
Based on the values of the three parameters, a split guideline, called split size, is calculated as:
xxxxxxxxxx
splitSize = Math.max(minSize, Math.min(goalSize, blockSize));
where:
goalSize = Sum of all files lengths to be read / minPartitions
Now using ‘splitSize’, each of the data files (to be read) is split if the same is splittable. Therefore, if a file is splittable with a size more than ‘splitSize’ then the file is split in multiple chunks of ‘splitSize’, the last chunk being less than or equal to ‘splitSize’. If the file is not splittable or having size less then ‘splitSize’, then there is only one file chunk of size equal to file length.
Each of the file chunks (having size greater than zero) is mapped to a single partition. Therefore, the number of partitions in the RDD, returned by RDD APIs on data files, is equal to the number of non-zero file chunks derived from slicing the data files using ‘splitSize’.
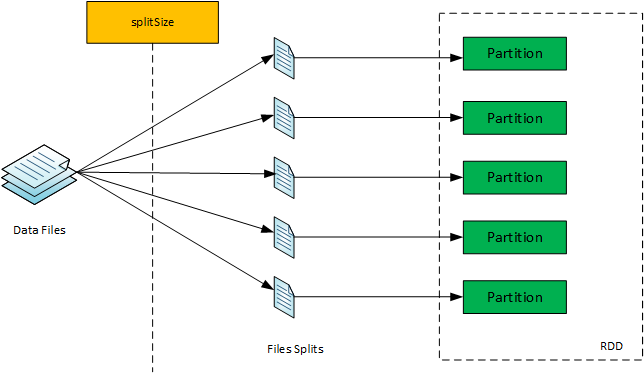
(a) 31 parquet files, 330 MB each, blocksize at default 128 MB, minPartitions not specified, ‘mapred.min.split.size’ at default, No. of core equal to 10: The number of partitions for this comes out to be 93. The splitSize comes out of 128 MB only, so basically the number of partitions becomes equal to the number of blocks occupied by 31 files. Each file occupies 3 blocks, so total blocks and total partitions come out to be 93.







As evident from the ‘splitSize’ calculation, if there is a desire to have Paritions sizes greater than blocksize, then ‘mapred.min.split.size’ needs to be set to a higher number greater than the blocksize. Also, if the desire is to have Partitions sizes less than blocksize, then ‘minPartitions’ should be set at a relatively higher value such that the goalsize (Sum of Files sizes/’minParitions’) computation comes to be lesser than the blocksize.
Summary
Until recently, the process of picking up a certain number of partitions against a set of data files, always looked mysterious to me. However, recently, during an optimization routine, I wanted to change the default number of partitions picked by Spark for processing a set of data files, and that is when I started to decode this process comprehensively along with proofs. Hopefully, the description of this decoded process would also help the readers to understand Spark a bit deeper and would enable them to design an efficient and optimized Spark routine.
Please remember, the optimum number of partitions is the key to an efficient and reliable Spark application. In case of feedback or queries on this post, do write in the comments section. I hope you find it useful.
Published at DZone with permission of Ajay Gupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments