Get Started With Vector Search in Azure Cosmos DB
Learn how to enable and use vector search in Azure Cosmos DB for NoSQL with a step-by-step guide in Python, TypeScript, .NET, and Java using a movie dataset.
Join the DZone community and get the full member experience.
Join For FreeThis is a guide for folks who are looking for a way to quickly and easily try out the Vector Search feature in Azure Cosmos DB for NoSQL. This app uses a simple dataset of movies to find similar movies based on a given criteria. It's implemented in four languages — Python, TypeScript, .NET and Java. There are instructions that walk you through the process of setting things up, loading data, and then executing similarity search queries.
A vector database is designed to store and manage vector embeddings, which are mathematical representations of data in a high-dimensional space. In this space, each dimension corresponds to a feature of the data, and tens of thousands of dimensions might be used to represent data. A vector's position in this space represents its characteristics. Words, phrases, or entire documents, and images, audio, and other types of data can all be vectorized. These vector embeddings are used in similarity search, multi-modal search, recommendations engines, large language models (LLMs), etc.
Prerequisites
You will need:
- An Azure subscription. If you don't have one, you can create a free Azure account. If, for some reason, you cannot create an Azure subscription, try Azure Cosmos DB for NoSQL free.
- Once that's done, go ahead and create an Azure Cosmos DB for NoSQL account.
- Create an Azure OpenAI Service resource. Azure OpenAI Service provides access to OpenAI's models including the GPT-4o, GPT-4o mini (and more), as well as embedding models. In this example, we will use the
text-embedding-ada-002embedding model. Deploy this model using the Azure AI Foundry portal.
I am assuming you have the required programming language already setup. To run the Java example, you need to have Maven installed (most likely you do, but I wanted to call it out).
Configure Integrated Vector Database in Azure Cosmos DB for NoSQL
Before you start loading data, make sure to configure the vector database in Azure Cosmos DB.
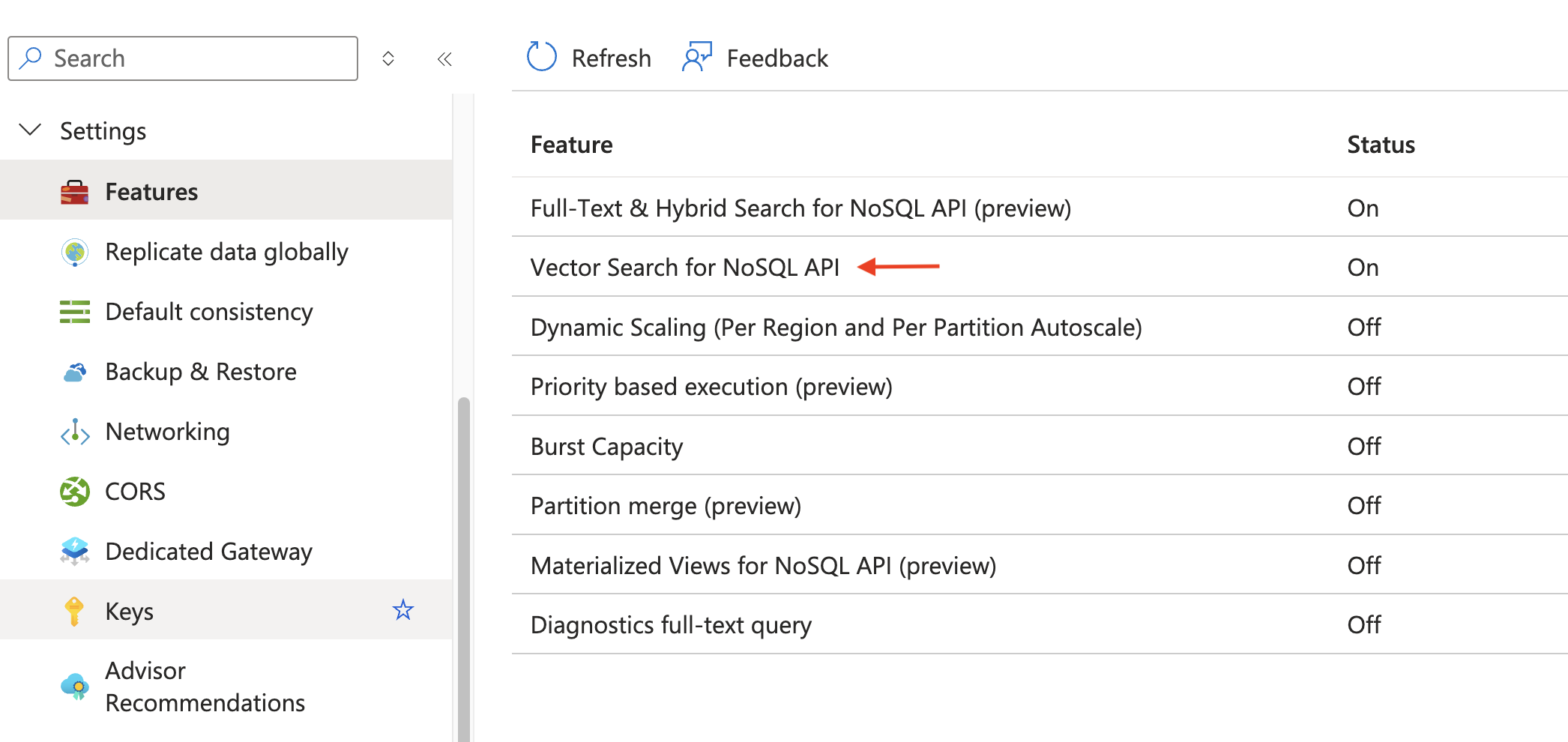
Enable the Feature
This is a one-time operation — you will need to explicitly enable the vector indexing and search feature.
Create a Database and Container
Once you have done that, go ahead and create a database and collection. I created a database named movies_db and a container named movies with the partition key set to /id.
Create Policies
You will need to configure a vector embedding policy as well as an indexing policy for the container. For now, you can do it manually via the Azure portal (it's possible to do it programmatically as well) as part of the collection creation process. Use the same policy information as per the above, at least for this sample app:
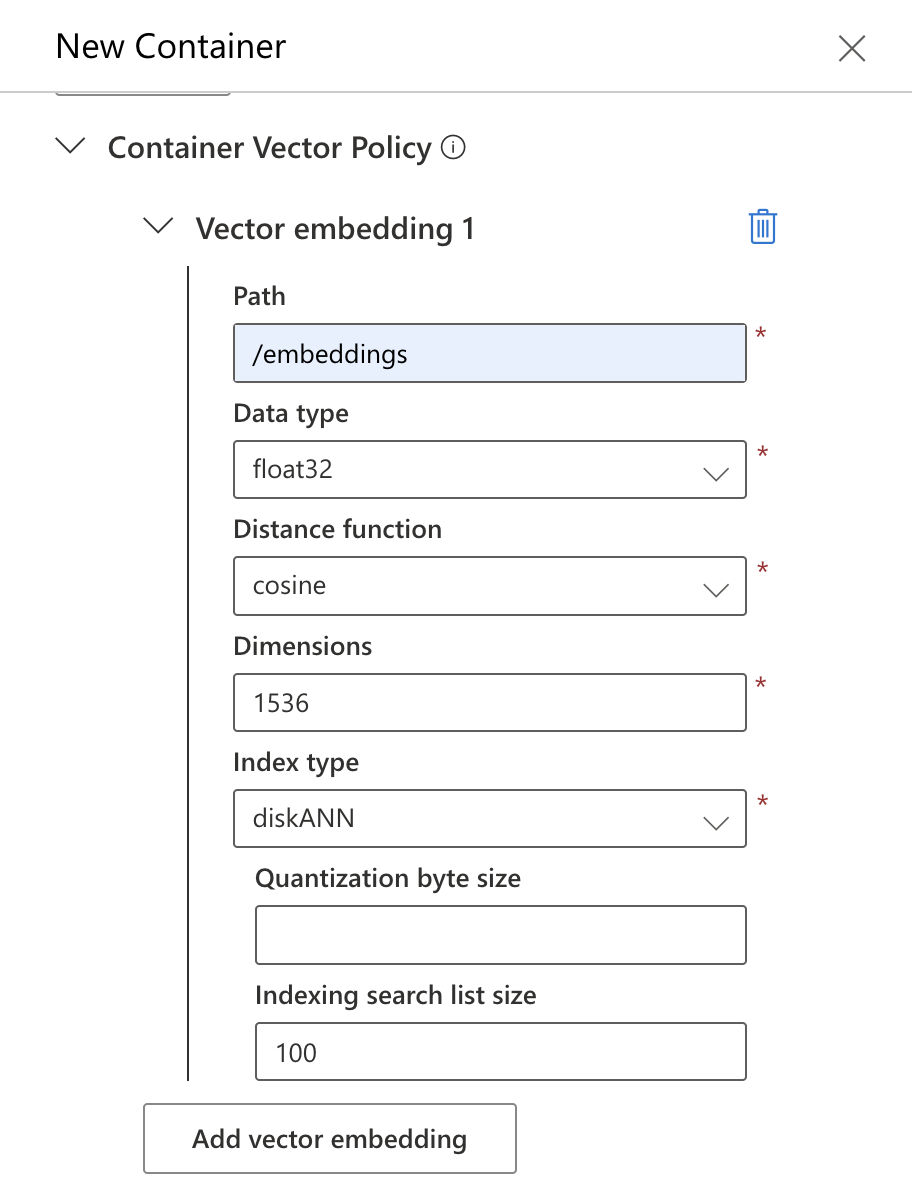
Choice of index type: Note that I have chosen the
diskANNindex type which and a dimension of1536for the vector embeddings. The embedding model I chose was text-embedding-ada-002 model and it supports dimension size of 1536. I would recommend that you stick to these values for running this sample app. But know that you can change the index type but will need to change the embedding model to match the new dimension of the specified index type.
Alright, let's move on.
Load Data in Azure Cosmos DB
To keep things simple, I have a small dataset of movies in JSON format (in movies.json file). The process is straightforward:
- Read movie info data from
jsonfile, - Generate vector embeddings (of the movie description), and
- Insert the complete data (title, description, and embeddings) into Azure Cosmos DB container.
As promised, here are the language-specific instructions — refer to the one that's relevant to you. Irrespective of the language, you need to set the following environment variables:
export COSMOS_DB_CONNECTION_STRING=""
export DATABASE_NAME=""
export CONTAINER_NAME=""
export AZURE_OPENAI_ENDPOINT=""
export AZURE_OPENAI_KEY=""
export AZURE_OPENAI_VERSION="2024-10-21"
export EMBEDDINGS_MODEL="text-embedding-ada-002"Before moving on, don't forget to clone this repository:
git clone https://github.com/abhirockzz/cosmosdb-vector-search-python-typescript-java-dotnet
cd cosmosdb-vector-search-python-typescript-java-dotnetLoad Vector Data Using Python SDK for Azure Cosmos DB
Setup the Python environment and install the required dependencies:
cd python
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtTo load the data, run the following command:
python load.pyLoad Vector Data Using Typescript SDK for Azure Cosmos DB
Install the required dependencies:
cd typescript
npm installBuild the program and then load the data:
npm run build
npm run loadLoad Vector Data Using Java SDK for Azure Cosmos DB
Install dependencies, and build the application:
cd java
mvn clean installLoad the data:
java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar loadLoad Vector Data Using .NET SDK for Azure Cosmos DB
Install dependencies and load the data:
cd dotnet
dotnet restore
dotnet run loadIrrespective of the language, you should see the output similar to this (with slight differences):
database and container ready....
Generated description embedding for movie: The Matrix
Added data to Cosmos DB for movie: The Matrix
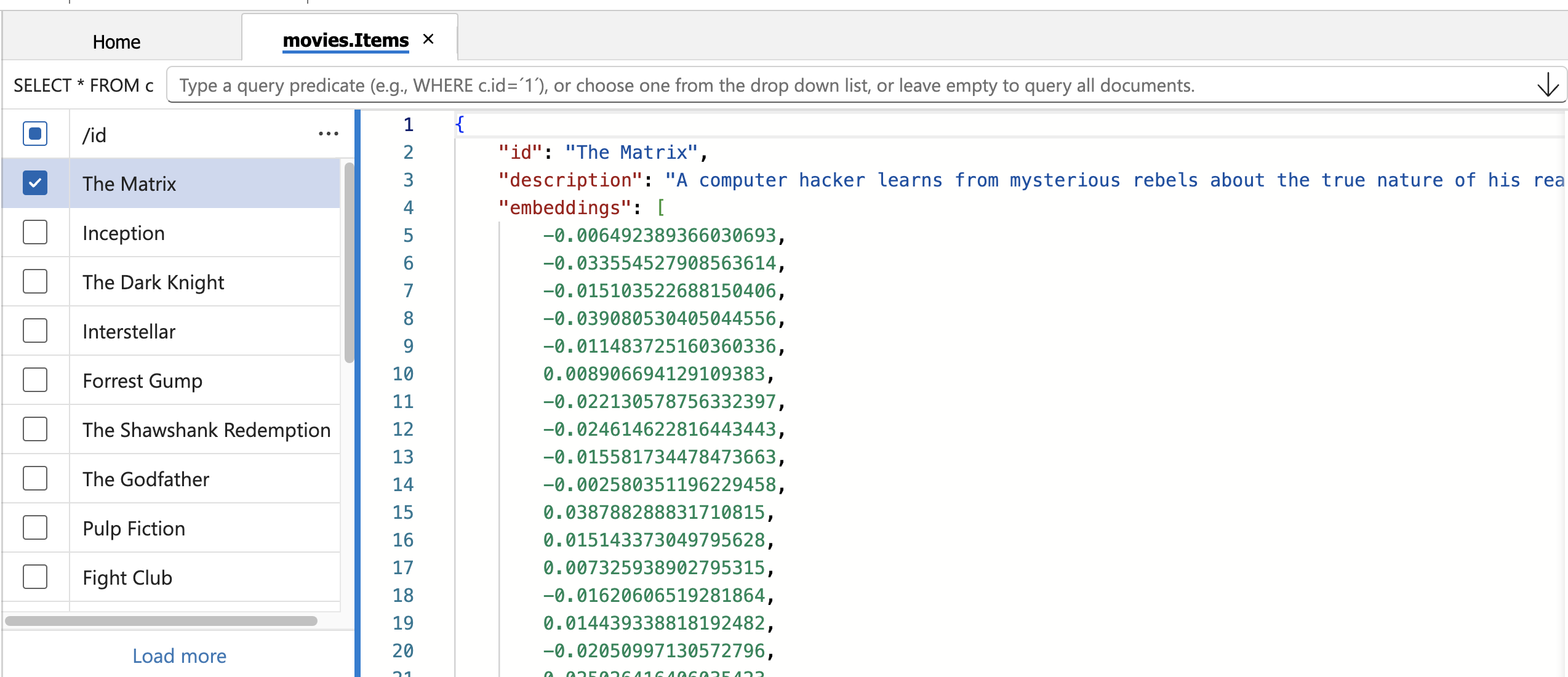
....Verify Data in Azure Cosmos DB
Check the data in the Azure portal. You can also use the Visual Studio Code extension, which is pretty handy!
Let's move on to the search part!
Vector/Similarity Search
The search component queries Azure Cosmos DB collection to find similar movies based on a given search criteria - for example, you can search for comedy movies. This is done using the VectorDistance function to get the similarity score between two vectors.
Again, the process is quite simple:
- Generate a vector embedding for the search criteria, and
- Use the
VectorDistancefunction to compare it.
This is what the query looks like:
SELECT TOP @num_results c.id, c.description, VectorDistance(c.embeddings, @embedding) AS similarityScore FROM c ORDER BY VectorDistance(c.embeddings, @embedding)Just like data loading, the search is also language-specific. Here are the instructions for each language.
I am assuming you have already set the environment variables and loaded the data.
Invoke the respective program with your search criteria (e.g. inspiring, comedy, etc.) and the number of results (top N) you want to see.
Python
python search.py "inspiring" 3Typescript
npm run search "inspiring" 3Java
java -jar target/cosmosdb-java-vector-search-1.0-SNAPSHOT.jar search "inspiring" 3.NET
dotnet run search "inspiring" 3Irrespective of the language, you should get the results similar to this. For example, my search query was "inspiring," and I got the following results:
Search results for query: inspiring
Similarity score: 0.7809536662138555
Title: Forrest Gump
Description: The story of a man with a low IQ who achieves incredible feats in his life, meeting historical figures and finding love along the way.
=====================================
Similarity score: 0.771059411474658
Title: The Shawshank Redemption
Description: Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency.
=====================================
Similarity score: 0.768073216615931
Title: Avatar
Description: A paraplegic Marine dispatched to the moon Pandora on a unique mission becomes torn between following his orders and protecting the world he feels is his home.
=====================================Closing Notes
I hope you found this useful! Before wrapping up, here are a few things to keep in mind:
- There are different vector index types you should experiment with (
flat,quantizedFlat). - Consider the metric your are using to compute distance/similarity (I used
cosine, but you can also useeuclidean, ordot product). - Which embedding model you use is also an important consideration - I used
text-embedding-ada-002but there are other options, such astext-embedding-3-large,text-embedding-3-small. - You can also use Azure Cosmos DB for MongoDB vCore for vector search.
Published at DZone with permission of Abhishek Gupta, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments