From Architecture to an AWS Serverless POC: Architect's Journey
Solution architecture for a financial services client onboarding user journey and patterns to design and develop a Python microservice deployed as an AWS serverless application.
Join the DZone community and get the full member experience.
Join For FreeProject Context
This year a number of financial services firms have had to comply with a new "401(k)-to-IRA Rollover Advice" fiduciary rule. This rule mandates that wealth managers and broker-dealers must demonstrate "investor's best interest" intent when presenting investment opportunities to their clients.
Many financial services firms with legacy and 3rd party SaaS application landscape face a common challenge of data lineage and data consistency throughout the client onboarding user journey. Throughout this journey, the client’s investment profile is used to put together a proposed investment portfolio and open an investment account. 
It is typical for the entire proposal to account opening funnel to be supported by a heterogeneous application landscape. Depending on the platform, vendor or home-grown software manages the same client and investments data structure in proprietary formats creating a likelihood for data discrepancies and quality gaps. Information is usually shared via point-to-point integrations throughout the user journey creating a data transformation funnel that resembles a broken telephone game. Such data discrepancies can cause minor data accuracy or critical non-compliance issues.
In this article, I will present a solution architecture to address the data quality and latency concerns. I will also describe a cloud-native software engineering pattern to develop an AWS Serverless application.
Solution Architecture
I’ll start by defining the data boundary and the data lifecycle within a business process. I will then outline the software architecture to address the business concerns. The client on-boarding logical data structure includes data elements such as the client’s PII, investment objectives, risk score, target asset allocation, existing and target investment portfolios. Let’s name this data construct Client Investment Profile (CIP). The CIP data lifecycle includes events such as "create CIP", which occurs during investment proposal generation, and "search/read CIP" which take place during the electronic application, account opening, and compliance review.
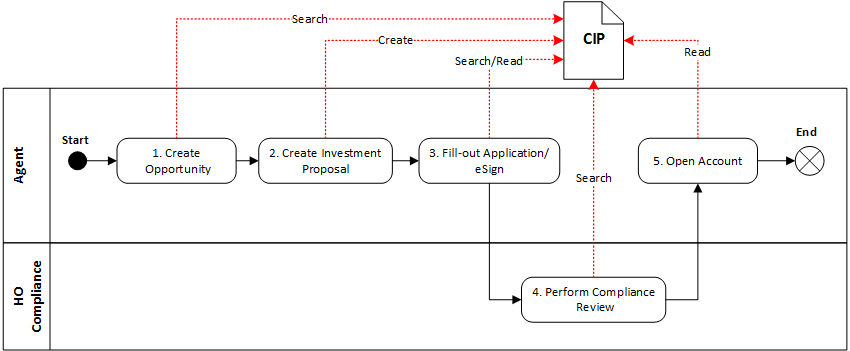
The Client Investment Profile microservice will support the CIP data lifecycle events via a CRUD REST API. Each data event above is supported by a corresponding API route.
The application architecture diagram below illustrates the Client Investment Profile microservice in the context of the application landscape and integration to support the client onboarding user journey.

At this point, the solution architecture is nearly complete, and we can start exploring the solution engineering options.
My Journey From Software Engineer to Architect and Back
At this point, I’d like to share a little background about myself. For the past eight years, I have worn various architect’s hats. Before becoming an architect, I was a software engineering manager. Software engineering was an important part of the job and my favorite aspect of it. Once an architect, I traded Eclipse IDE for Visio and PowerPoint. I have continuously maintained my technology skillset thru hands-on training. Every so often, I have come across technology executives, especially while I was at Goldman Sachs, who still coded like I used to. Such encounters sometimes triggered a severe case of impostor’s syndrome.
Client Investement Profile Microservice
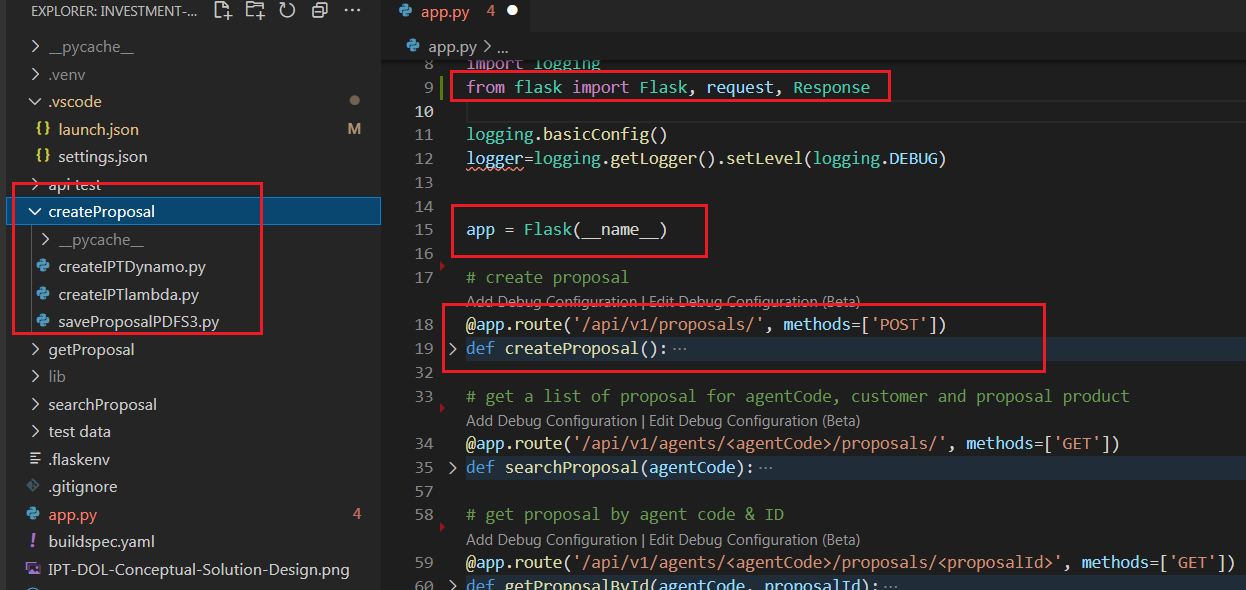
Developing the client investment profile microservice seemed like a perfect opportunity to scratch the nostalgic itch and become a software engineer again. Although my software engineering background was in Core Java and Java Springboot, I’ve decided to develop the new microservice using the Python Flask framework. The Flask framework is easy to learn, and it also allowed me to implement the POC quickly in my desktop Visual Studio Code.
I’ve considered deploying the flask microservice on Amazon ECS with Auto Scaling but ultimately decided on the AWS Lambda. With AWS Lambda, I can optimize the compute cost by fine-tuning memory utilization and concurrency for each CIP event lambda function. A Python AWS Lambda function has a shorter cold start than a Java AWS Lambda, which was another win for Python.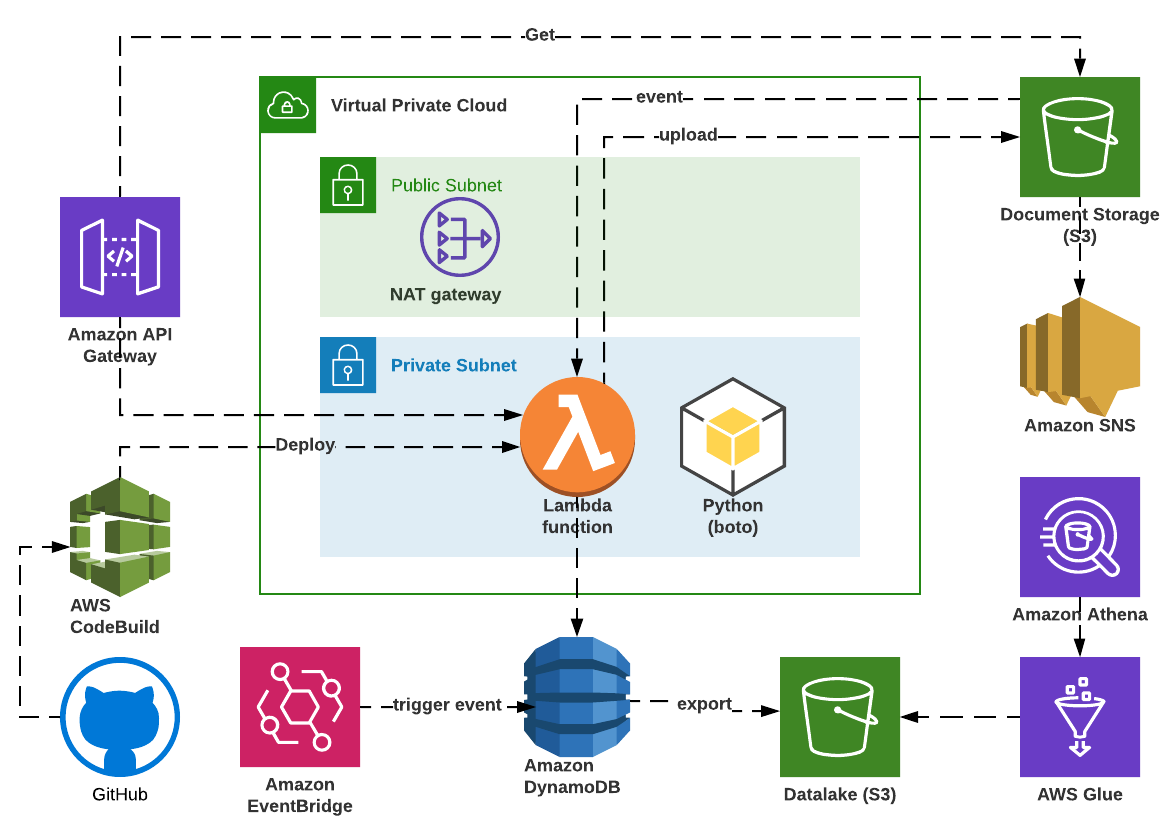
The CIP flask API has three routes that represent the three CIP data lifecycle events. Each event is implemented as a fully encapsulated and independent application module, which consists of a lambda function and supporting classes. This design will allow me to unit test the Flask microservice in VS Code and deploy it to AWS Lambda when I am ready.
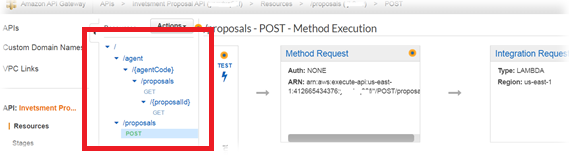
I can now manually package each module as a zip file and create an AWS Lambda triggered by the AWS API Gateway. The CIP API resources mimic the flask microservice API routes.

The following code snippet shows the function that can process the event created either by AWS Lambda or the Flask microservice, so I can run the same code regardless of how and where it’s deployed.
def lambda_handler(event, context):
try:
logger.debug("event type {}".format(type(event)))
if isinstance(event, bytes):
request_data = json.loads(event, parse_float=Decimal)
elif isinstance(event, dict):
request_data = json.loads(json.dumps(event), parse_float=Decimal)
else:
raise Exception("Unhandled event type {}".format(type(event)))Client Investment Profile Data Management
The Client Investment Profile data is created by the Proposal application, which invokes the CPI API passing a complex and nested JSON payload in the POST request body. I have considered a few data storage and access management options.
- AWS RDS supports native SQL, thus providing strong data analytics capabilities. However, RDS will require decomposing the JSON document into a set of data elements and creating a physical data model with parent/child tables interconnected by primary and foreign keys.
- MongoDB allows the JSON document to be stored in its native format and supports complex search queries. However, MongoDB may seem like overkill for a single collection of JSON documents.
- AWS DynamoDB is a versatile key/value datastore that also supports attribute JSON data types.
AWS DynamoDB seems like the best choice of the three options provided that I design the data model and indexes to support the data access patterns. I’ve decided to use the user ID and the CIP ID attributes for the partition and sort keys to ensure record uniqueness and avoid a full table scan when searching for CIP. You may notice that the same attributes are used in the API route parameters.

Mission accomplished, I can now run and test the CIP microservice in my VS Code installed on my laptop by executing the "flask run" command and connect to the DynamoDB and S3 on AWS. Alternatively, I can package the code without any modifications and deploy it as a serverless application running on AWS API Gateway, Lambda, DynamoDB, and S3 data storage.
Continuous Build/Deploy
I’ve been writing code daily, sometimes working on two laptops. It is now time to manage the POC codebase more efficiently. I created a source code repository in GitHub, cloned the remote repository in my VS Code workspace, kept pushing the code there frequently.

Next, I created the AWS CodeBuild project. I configured the project to pull the source code from GitHub using the GitHub webhook and to only build and deploy the application if the following criteria are met: Event Type equals "PUSH" or "PULL_REQUEST_MERGED" and the code branch name equals "test".
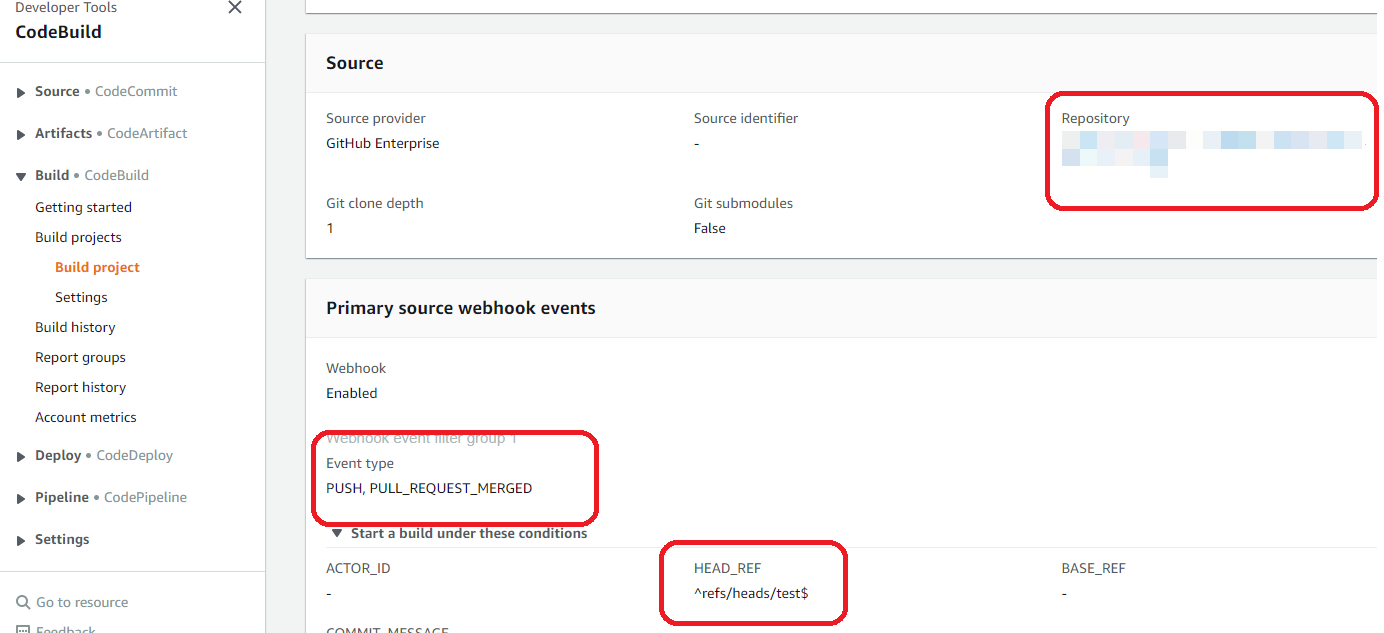
This configuration will ensure that the AWS Lambda functions are only built and deployed when I promote the latest changes from the dev to the test branch rather than deploying the lambda functions with every "git push" event to the dev branch.
I can configure another AWS CodeBuild project in the same or another AWS account to execute "build and deploy" for upper environments whenever the code is pushed or merged into a corresponding branch in the GitHub workspace.
Another cool trick is that the buildspec.yaml file which contains the lambda functions build/deploy instructions is part of the code workspace ensuring "update once run everywhere" consistent build/deploy execution in all environments.
build:
commands:
- zip createProposal.zip createProposal/*
- zip searchProposal.zip searchProposal/*
- zip getProposal.zip getProposal/*
post_build:
commands:
- aws lambda update-function-code --function-name createProposal --zip-file fileb://createProposal.zip
- aws lambda update-function-code --function-name searchProposal --zip-file fileb://searchProposal.zip
- aws lambda update-function-code --function-name getProposal --zip-file fileb://getProposal.zipConclusion
This POC has been a truly gratifying experience for me. For the past few years, I’ve been self-conscious about spending most of my time managing solution architecture and delivery and not enough time engineering solutions. This POC has allowed me to become a software engineer again and maintain my technology skill edge. I am excited about the rest of the project. There is so much work to be done with document managing and data analytics. This article doesn’t specifically discuss software security concerns for the reasons of maintaining confidentiality.
Acknowledgments
I want to thank my work buddies Chris Field and Stephen Banner for being generous with their time, providing the necessary guidance, and becoming vested in my success.
I also want to thank Google for providing me with answers to most of my questions. A quote from Ecclesiastes 1:9 still rings true to this day:
"What has been will be again, what has been done will be done again; there is nothing new under the sun."
Google does a great job finding answers to questions previously asked and answered.
Disclaimer
This article describes a real-life architecture to engineering journey. I took the liberty of significantly changing the architecture and other contents used in this article to preserve the confidentiality of my past and current clients and employers.
Opinions expressed by DZone contributors are their own.
Comments