From Batch ML To Real-Time ML
Explore this article that defines batch ML and real-time ML, listing real-time ML use cases, components, and challenges.
Join the DZone community and get the full member experience.
Join For FreeReal-time machine learning refers to the application of machine learning algorithms that continuously learn from incoming data and make predictions or decisions in real-time. Unlike batch machine learning, where data is collected over a period and processed in batches offline, real-time ML operates instantaneously on streaming data, allowing for immediate responses to changes or events.
Common use cases include fraud detection in financial transactions, predictive maintenance in manufacturing, recommendation systems in e-commerce, and personalized content delivery in media. Challenges in building real-time ML capabilities include managing high volumes of streaming data efficiently, ensuring low latency for timely responses, maintaining model accuracy and performance over time, and addressing privacy and security concerns associated with real-time data processing. This article delves into these concepts and provides insights into how organizations can overcome these challenges to deploy effective real-time ML systems.
Use Cases
Now we have explained the difference between batch ML and real-time ML, it's worth mentioning that in real-life use cases, you can have batch ML, real-time ML, or in between batch and real-time. For example, you can have scenarios where you have real-time inference with batch features, real-time inference with real-time features, or real-time inference with batch features and real-time features. Continuous machine learning is beyond the scope of this article, but you can apply real-time feature solutions to continuous machine learning (CML) too.
Hybrid approaches that combine real-time and batch-learning aspects offer a flexible solution to address various requirements and constraints in different applications. Here are some expanded examples:
| Uses Cases | Batch | Real-Time |
|---|---|---|
Fraud detection in banking |
Initially, a fraud detection model can be trained offline using a large historical dataset of transactions. This batch training allows the model to learn complex patterns of fraudulent behavior over time, leveraging the entirety of available historical data. |
Once the model is deployed, it continues to learn in real-time as new transactions occur. Each transaction is processed in real-time, and the model is updated periodically (e.g., hourly or daily) using batches of recent transaction data. This real-time updating ensures that the model can quickly adapt to emerging fraud patterns without sacrificing computational efficiency. |
Recommendation systems in e-commerce |
A recommendation system may be initially trained offline using a batch of historical user interaction data, such as past purchases, clicks, and ratings. This batch training allows the model to learn user preferences and item similarities effectively. |
Once the model is deployed, it can be fine-tuned in real-time as users interact with the system. For example, when a user makes a purchase or provides feedback on a product, the model can be updated immediately to adjust future recommendations for that user. This real-time personalization enhances user experience and engagement without requiring retraining the entire model with each interaction. |
Natural Language Processing (NLP) applications |
NLP models, such as sentiment analysis or language translation models, can be trained offline using large corpora of text data. Batch training allows the model to learn semantic representations and language structures from diverse text sources. |
Once deployed, the model can be fine-tuned in real-time using user-generated text data, such as customer reviews or live chat interactions. Real-time fine-tuning enables the model to adapt to domain-specific or user-specific language nuances and evolving trends without requiring retraining from scratch. |
In each of these examples, the hybrid approach combines the depth of analysis provided by batch learning with the adaptability of real-time learning, resulting in more robust and responsive machine learning systems. The choice between real-time and batch-learning elements depends on the specific requirements of the application, such as data volume, latency constraints, and the need for continuous adaptation.
What Are the Main Components of a Real-Time ML Pipeline?
A real-time machine learning (ML) pipeline typically consists of several components working together to enable the continuous processing of data and the deployment of ML models with minimal latency. Here are the main components of such a pipeline:
1. Data Ingestion
This component is responsible for collecting data from various sources in real-time. It could involve streaming data from sensors, databases, APIs, or other sources.
2. Streaming Data Processing and Feature Engineering
Once the data is ingested, it needs to be processed in real-time. This component involves streaming data processing frameworks that handle the data streams efficiently. Features extracted from raw data are crucial for building ML models. This component involves transforming the raw data into meaningful features that can be used by the ML models. Feature engineering might include techniques like normalization, encoding categorical variables, and creating new features.
3. Model Training
Training typically occurs at regular intervals, with the frequency varying between near-real-time, which involves more frequent time frames than batch training, or online-real-time training.
4. Model Inference
This component involves deploying the ML models and making predictions in real time. The deployed models should be optimized for low latency inference, and they need to scale well to handle varying loads.
5. Scalability and Fault Tolerance
Real-time ML pipelines must be scalable to handle large volumes of data and fault-tolerant to withstand failures gracefully. This often involves deploying the pipeline across distributed systems and implementing mechanisms for fault recovery and data replication.
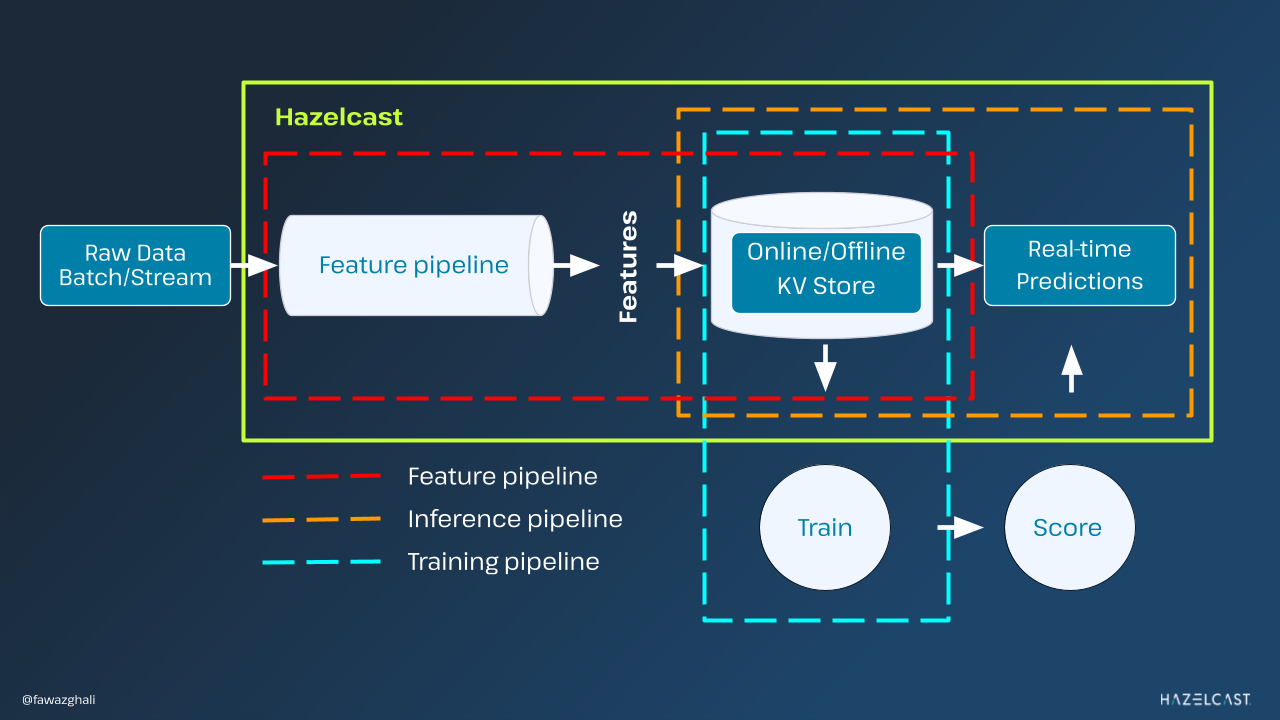
Challenges for Building Real-Time ML Pipelines
Low Latency Requirement
Real-time pipelines must process data and make predictions within strict time constraints, often in milliseconds. Achieving low latency requires optimizing every component of the pipeline, including data ingestion, pre-processing, model inference, and output delivery.
Scalability
Real-time pipelines must handle varying workloads and scale to accommodate increasing data volumes and computational demands. Designing scalable architectures involves choosing appropriate technologies and distributed computing strategies to ensure efficient resource utilization and horizontal scalability.
Feature Engineering
Generating features in real time from streaming data can be complex and resource-intensive. Designing efficient feature extraction and transformation pipelines that adapt to changing data distributions and maintain model accuracy over time is a key challenge.
Security
Robust authentication, authorization, and secure communication mechanisms are essential for real-time ML. Having effective incident response and monitoring capabilities enables organizations to detect and respond to security incidents promptly, bolstering the overall resilience of real-time ML pipelines against security threats. By addressing these security considerations comprehensively, organizations can build secure real-time ML pipelines that protect sensitive data and assets effectively.
Cost Optimization
Building and operating real-time ML pipelines can be costly, especially when using cloud-based infrastructure or third-party services. Optimizing resource utilization, selecting cost-effective technologies, and implementing auto-scaling and resource provisioning strategies are essential for controlling operational expenses.
Robustness and Fault Tolerance
Real-time pipelines must be resilient to failures and ensure continuous operation under adverse conditions. Implementing fault tolerance mechanisms, such as data replication, checkpointing, and automatic failover, is critical for maintaining system reliability and availability.
Integration with Existing Systems
Integrating real-time ML pipelines with existing IT infrastructure, data sources, and downstream applications requires careful planning and coordination. Ensuring compatibility, interoperability, and seamless data flow between different components of the system is essential for successful deployment and adoption.
Addressing these challenges requires a combination of domain expertise, software engineering skills, and knowledge of distributed systems, machine learning algorithms, and cloud computing technologies.
Opting for solutions that streamline operations by minimizing the number of tools involved can be a game-changer. This approach not only slashes integration efforts but also trims down maintenance costs and operational overheads while ushering in lower latency—a crucial factor in real-time ML applications. By consolidating feature processing and storage into a single, high-speed key-value store, with a real-time ML model serving, Hazelcast simplifies the AI landscape, reducing complexity and ensuring seamless data flow.
The Future of Real-Time ML
The future of real-time machine learning (ML) is closely intertwined with advancements in vector databases and the emergence of Relative Attribute Graphs (RAG). Vector databases provide efficient storage and querying capabilities for high-dimensional data, making them well-suited for managing the large feature spaces common in ML applications. Relative Attribute Graphs, on the other hand, offer a novel approach to representing and reasoning about complex relationships in data, enabling more sophisticated analysis and decision-making in real-time ML pipelines.
In the context of finance and fintech, the integration of vector databases and RAGs holds significant promise for enhancing various aspects of real-time ML applications. One example is in fraud detection and prevention. Financial institutions must constantly monitor transactions and identify suspicious activities to mitigate fraud risk. By leveraging vector databases to store and query high-dimensional transaction data efficiently, combined with RAGs to model intricate relationships between transactions, real-time ML algorithms can detect anomalies and fraudulent patterns in real time with greater accuracy and speed.
Another application area is in personalized financial recommendations and portfolio management. Traditional recommendation systems often struggle to capture the nuanced preferences and goals of individual users. However, by leveraging vector representations of user preferences and financial assets stored in vector databases, and utilizing RAGs to model the relative attributes and interdependencies between different investment options, real-time ML algorithms can generate personalized recommendations that better align with users' financial objectives and risk profiles. For example, a real-time ML system could analyze a user's financial history, risk tolerance, and market conditions to dynamically adjust their investment portfolio in response to changing market conditions and personal preferences.
Furthermore, in algorithmic trading, real-time ML models powered by vector databases and RAGs can enable more sophisticated trading strategies that adapt to evolving market dynamics and exploit complex interrelationships between different financial instruments. By analyzing historical market data stored in vector databases and incorporating real-time market signals represented as RAGs, algorithmic trading systems can make more informed and timely trading decisions, optimizing trading performance and risk management.
Overall, the future of real-time ML in finance and fintech is poised to benefit significantly from advancements in vector databases and RAGs. By leveraging these technologies, organizations can build more intelligent, adaptive, and efficient real-time ML pipelines that enable enhanced fraud detection, personalized financial services, and algorithmic trading strategies.
Opinions expressed by DZone contributors are their own.
Comments