Forget SQL vs NoSQL - Get the Best of Both Worlds With JSON in PostgreSQL
Learn how to use JSON with PostgreSQL to create a schema for any situation. Follow examples of storing JSON data, querying it, and avoiding anti-patterns.
Join the DZone community and get the full member experience.
Join For FreeHave you ever started a project and asked, "Should I use a SQL or NoSQL database?" It's a big decision. There are multiple horror stories of developers choosing a NoSQL database and later regretting it. But now you can get the best of both worlds with JSON in PostgreSQL.
In this article, I cover the benefits of using JSON, anti-patterns to avoid, and an example of how to use JSON in Postgres.
When To Use a SQL Database for Non-Relational Data
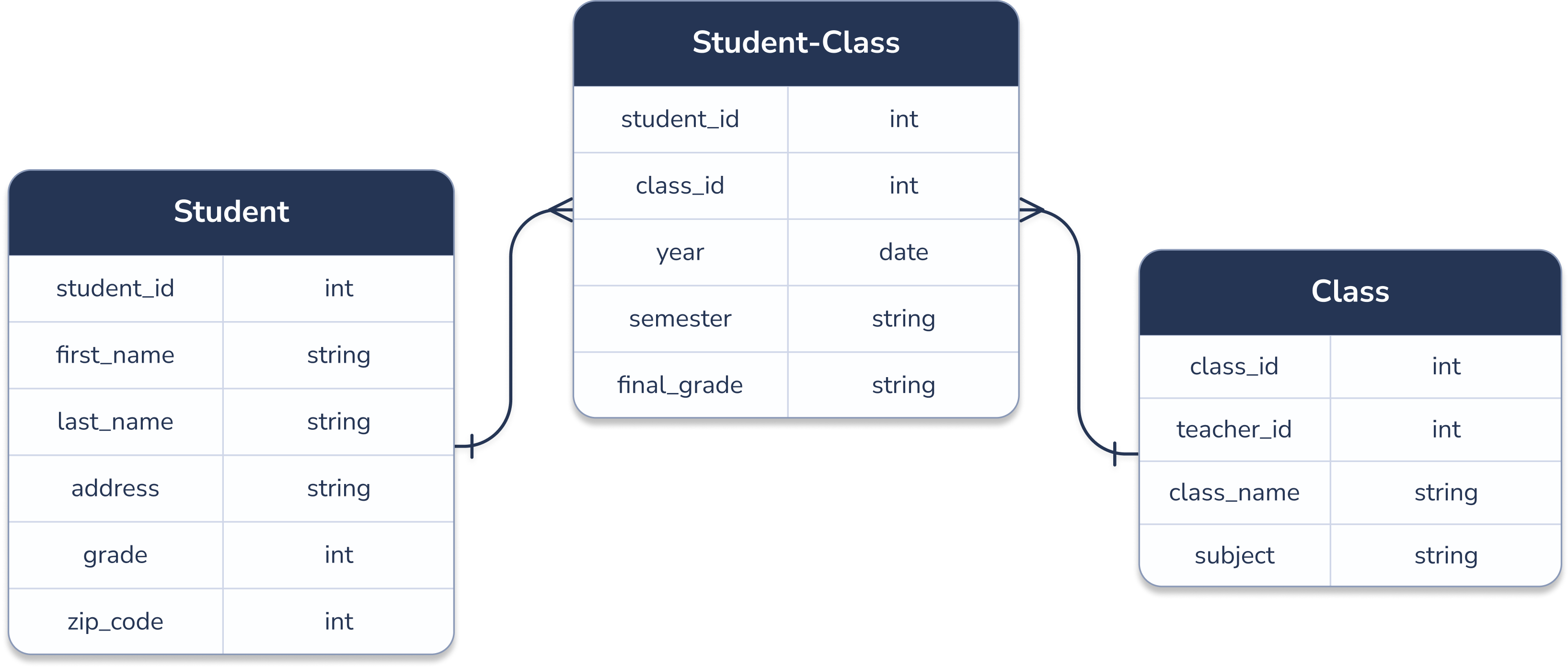
Example of normalized data in a school database
First, we have to briefly cover the advantages of using SQL vs NoSQL.
The difference between SQL and NoSQL is the data model. SQL databases use a relational data model, and NoSQL databases usually use a document model. A key difference is how each data model handles data normalization.
Data normalization is the process of splitting data into "normal forms" to reduce data redundancy. The concept was first introduced in the 1970s as a way to reduce spending on expensive disk storage.
In the example above, we have a normalized entity relationship-diagram for a school database. The StudentClass table stores every class a student has taken. By normalizing the data, we only keep one row for each class in the Class table, instead of duplicating class data for every student in the class.
But what if we also wanted to track every lunch order (entree, sides, drink, snacks, etc) to send each student a summary at the end of every week?
Students will always be shown their entire lunch order, so we want to avoid expensive joins by keeping the lunch order data together. In this case, it would make more sense to store the data in a single document instead of normalizing it.
xxxxxxxxxx
{ "student_id": 100,
"order_date": "2020-12-11",
"order_details": {
"cost": 5.87,
"entree": ["pizza"],
"sides": ["apple", "fries"],
"snacks": ["chips"]
}
}
Instead of maintaining a separate NoSQL database, we now store lunch orders as JSON objects inside an existing relational Postgres database.
Evolution of JSON in PostgreSQL
Plain JSON type
In 2012, PostgreSQL 9.2 introduced the first JSON data type in Postgres. It had syntax validation but it stored the incoming document directly as text with white spaces included. It wasn't very useful for real-world querying, index-based searching, and other functionalities you would normally do with a JSON document.
JSONB
In late 2014, PostgreSQL 9.4 introduced the JSONB datatype and most importantly improved the querying efficiency by adding indexing.
The JSONB datatype stores JSON as a binary type. This introduced overhead in processing since there was a conversion involved, but it offered the ability to index the data using GIN/Full text-based indexing and included additional operators for easy querying.
JSONPath
With JSON's increasing popularity, the 2016 SQL Standard brought in a new standard/path language for navigating JSON data. It's a powerful way of searching JSON data, very similar to XPath for XML data. PostgreSQL 12 introduced support for the JSON Path standard.
We will see examples of JSON, JSONB, and JSONPath in the sections below. An important thing to note is that all JSON functionality is natively present in the database. There is no need for a contrib module or an external package to be installed.
JSON Example in Postgres
Let's create a Postgres table to store lunch orders with a JSON data type.
xxxxxxxxxx
create table LunchOrders(student_id int, order json);
Now we can insert JSON formatted data into our table with an INSERT statement.
xxxxxxxxxx
insert into LunchOrders values(100, '{
"order_date": "2020-12-11",
"order_details": {
"cost": 4.25,
"entree": ["pizza"],
"sides": ["apple", "fries"],
"snacks": ["chips"]}
}'
);
insert into LunchOrders values(100, '{
"order_date": "2020-12-12",
"order_details": {
"cost": 4.89,
"entree": ["hamburger"],
"sides": ["apple", "salad"],
"snacks": ["cookie"]}
}'
);
If you do a Select * from the table, you would see something like this:
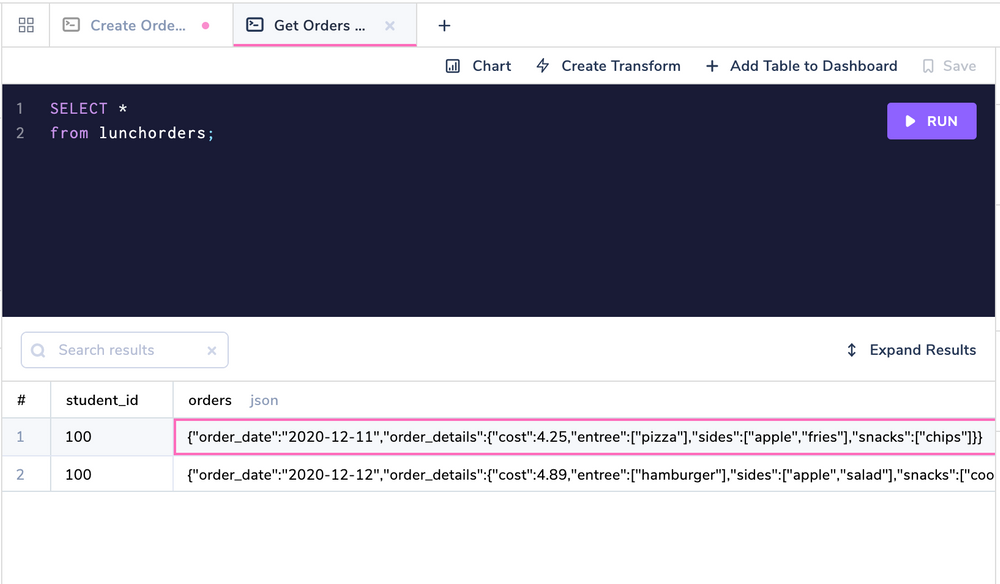
Get JSON objects. SQL Editor: Arctype
JSONB column is exactly the same, except we change the data type to jsonb.
xxxxxxxxxx
create table LunchOrders(student_id int, orders jsonb);
How To Query JSON Data in Postgres
Querying data from JSON objects uses slightly different operators than the ones that we use for regular data types ( =, < , >, etc).
Here are some of the most common JSON operators:

The -> and ->> operators work with both JSON and JSONB type data. The rest of the operators are full text search operators and only work with the JSONB datatype.
Let's see some examples of how to use each operator to query data in our LunchOrders table.
Getting Values from a JSON Object
We can use the -> operation to find every day that a specific student bought school lunch.
xxxxxxxxxx
select orders -> 'order_date'
from lunchorders
where student_id = 100;
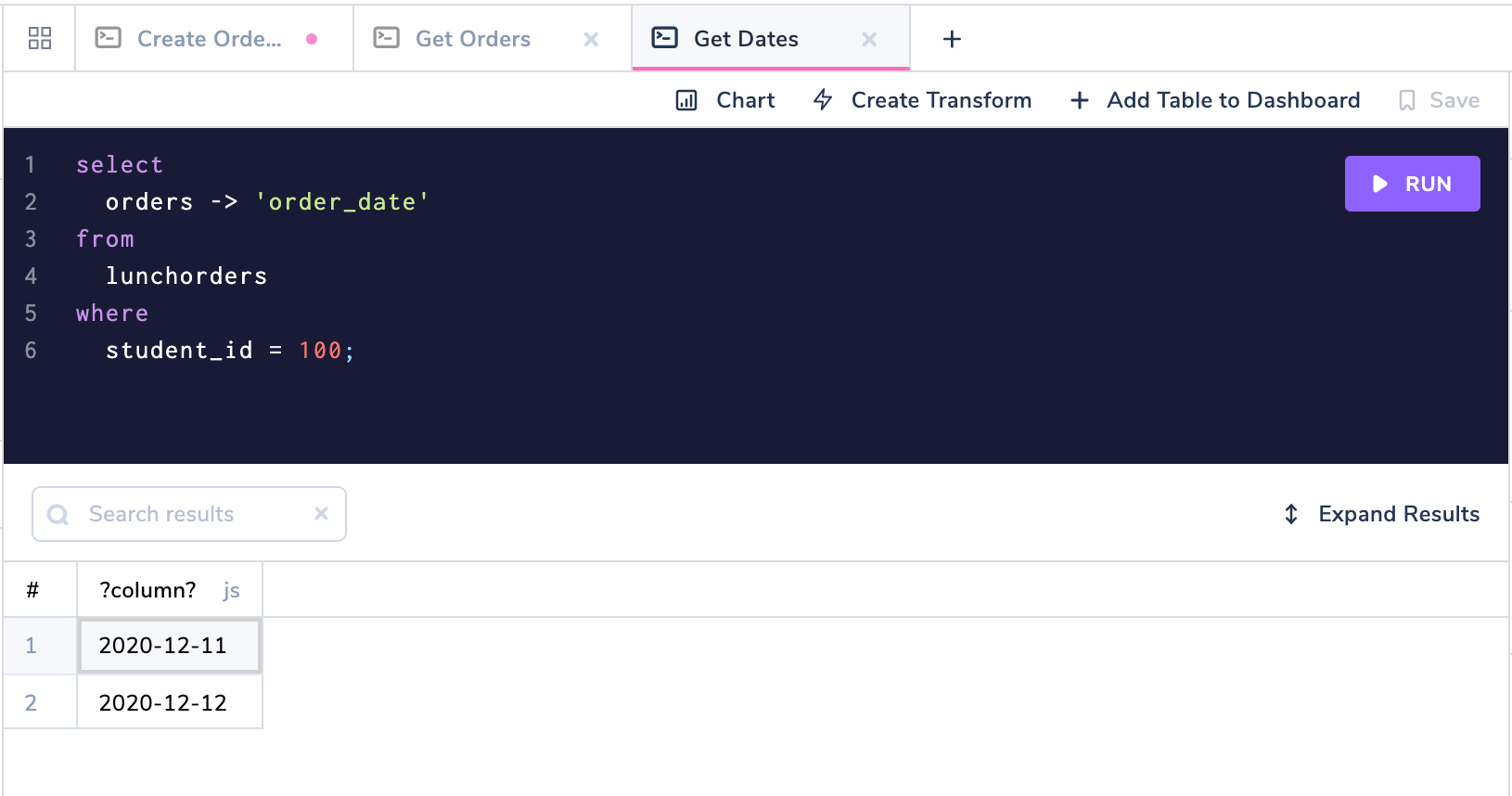
Filtering JSON Data Using a WHERE Clause
We can use the ->> operator to filter for only lunch orders on a specific date.
xxxxxxxxxx
select orders
from lunchorders
where orders ->> 'order_date' = '2020-12-11';
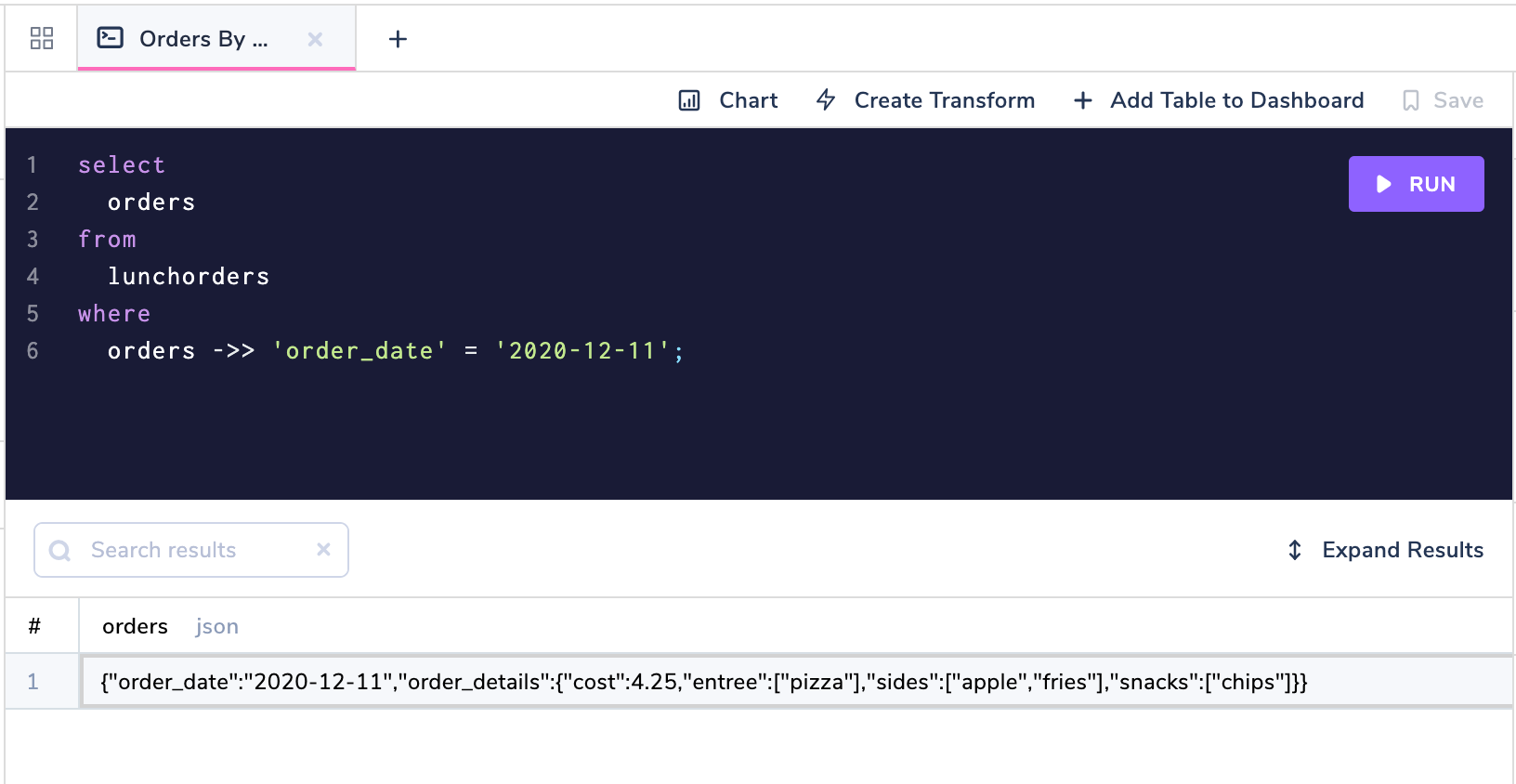
Filter JSON by date
This query is similar to the = operator that we would normally use, except we have to first add a ->> operator to tell Postgres that the order_date field is in the orders column.
Getting Data from an Array in a JSON Object
Let's say we wanted to find every side dish that a specific student has ordered.
The sides field is nested inside the order_details object, but we can access it by chaining two -> operators together.
xxxxxxxxxx
select orders -> 'order_date',
orders -> 'order_details' -> 'sides'
from lunchorders
where student_id = 100;
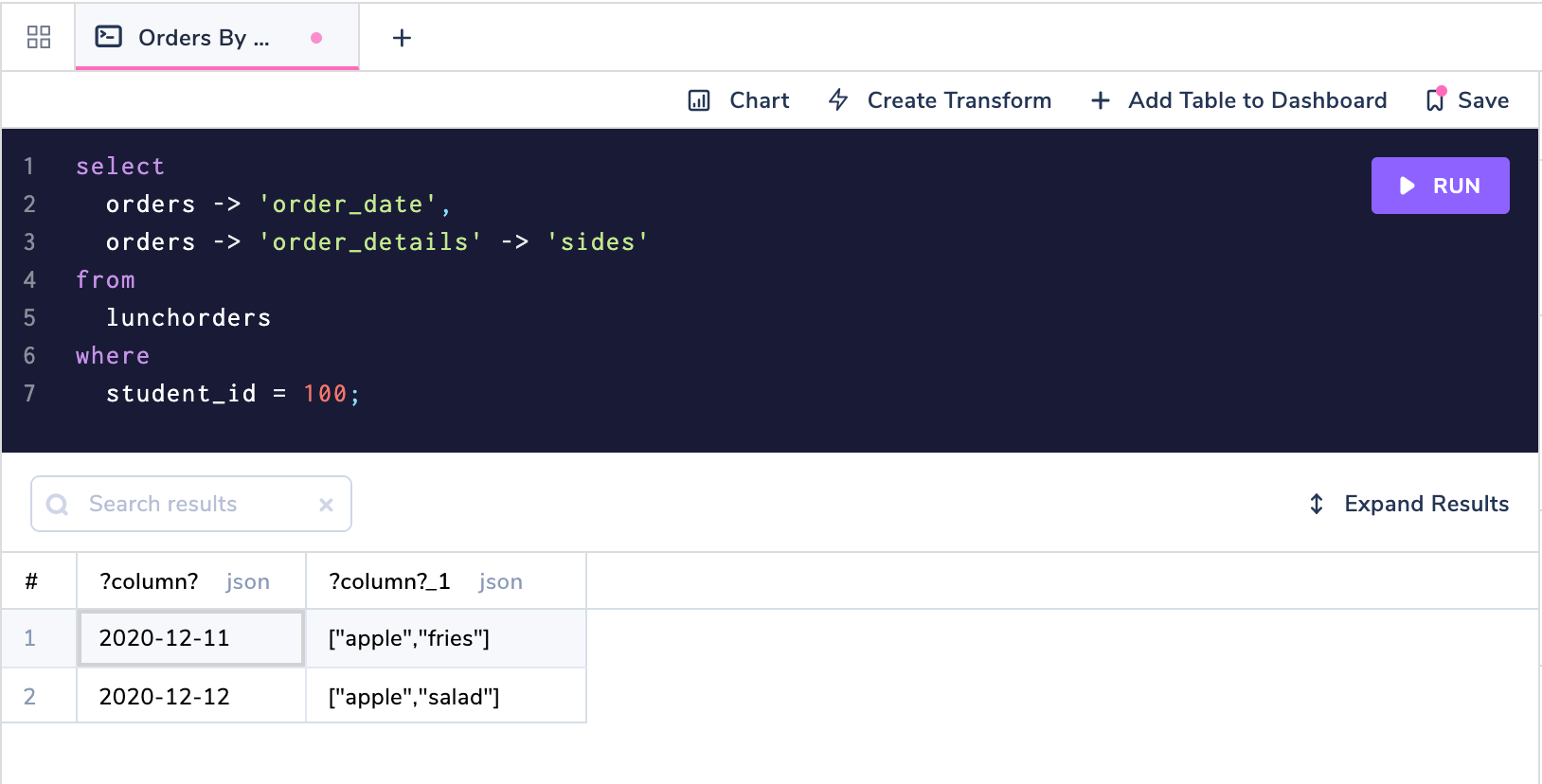
Getting nested values from a JSON object.
Great now we have arrays of the sides that student 100 ordered each day! What if we only wanted the first side in the array? We can chain together a third -> operator and give it the array index we're looking for.
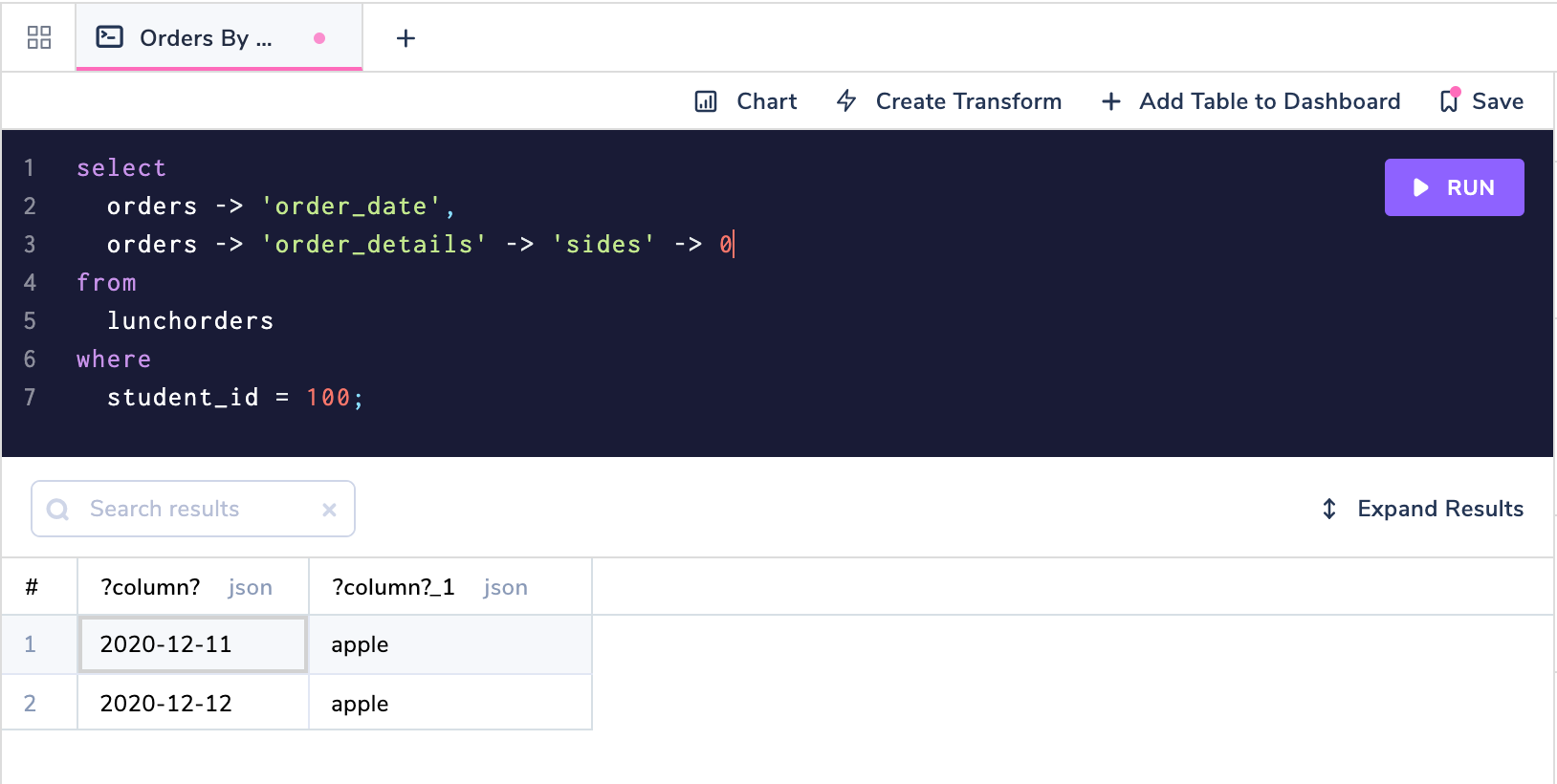
Retrieving Nested Values from a JSON Object
Instead of chaining together multiple -> operators, we can also use the #> operator to specify a path for retrieving a nested value.
xxxxxxxxxx
select orders #> '{order_details, sides}'
from lunchorders;
xxxxxxxxxx
?column?
--------------------
["apple", "fries"]
["apple", "salad"]
(2 rows)
Checking if a JSON Object Contains a Value
Let's say we wanted to see every order a student made that had a side salad. We can't use the previous ->> for filtering because sides is an array of values.
To check if an array or object contains a specific value, we can use the @> operator:
xxxxxxxxxx
select orders
from lunchorders
where orders -> 'order_details' -> 'sides' @> '["salad"]';
xxxxxxxxxx
orders
----------
{"order_date": "2020-12-12", "order_details": {"cost": 4.89, "sides": ["apple", "salad"], "entree": ["hamburger"], "snacks": ["cookie"]}}
(1 row)
JSONPath: The Final Boss
JSON Path is a powerful tool for searching and manipulating a JSON object in SQL using JavaScript-like syntax:
- Dot (.) is used for member access
- Square brackets ("[]") are used for array access
- SQL/JSON arrays are 0-indexed, unlike regular SQL arrays that start from 1
Built-In Functions
JSONPath also includes powerful built-in functions like size() to find the length of arrays.
Let's use the JSONPath size() function to get every order that had >= 1 snack.
xxxxxxxxxx
select *
from lunchorders
where orders @@ '$.order_details.snacks.size() > 0';
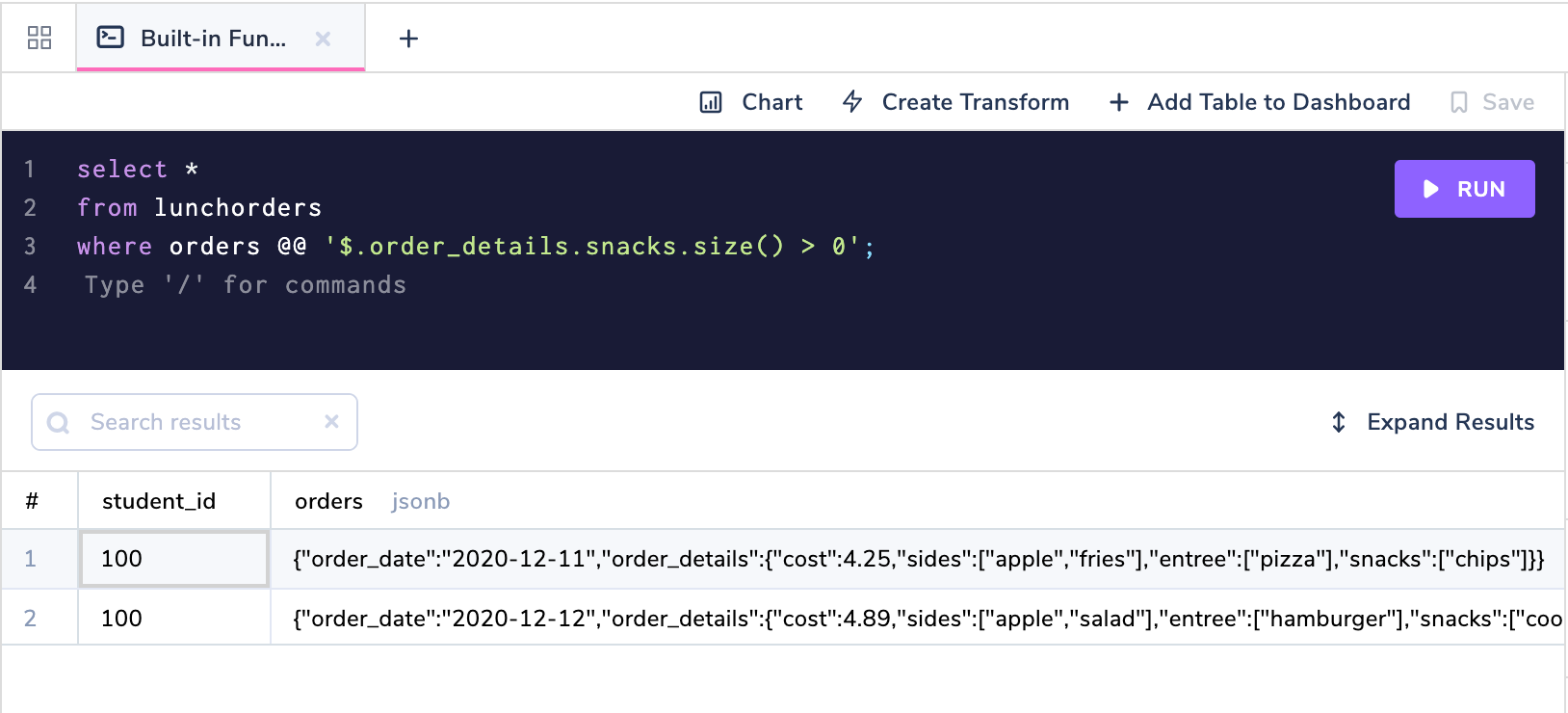
Comparison Without Type Casting
JSONPath also enables comparisons without explicit type casting:
xxxxxxxxxx
select *
from lunchorders
where orders @@ '$.order_details.cost > 4.50';
This is what the same query would look like with our regular JSON comparisons:
xxxxxxxxxx
select *
from lunchorders
where (orders -> 'order_details' ->> 'cost')::numeric > 4.50;
JSON Operators Summary
In this section, we covered the basics of working with JSON data in Postgres including:
- Selecting data using
-> - Filtering queries using
->> - Selecting nested values using
#> - Checking if an array contains a value using
@> - Using JSONPath to work with JSON objects
Working with JSON data can be complicated. Arctype is a free, modern SQL editor that makes working with databases easier.

JSON Indexing in Postgres
So how efficient are these JSON operations? In the absence of an index, the database engine has to scan through the entire table to find out the record which is called a sequential scan.
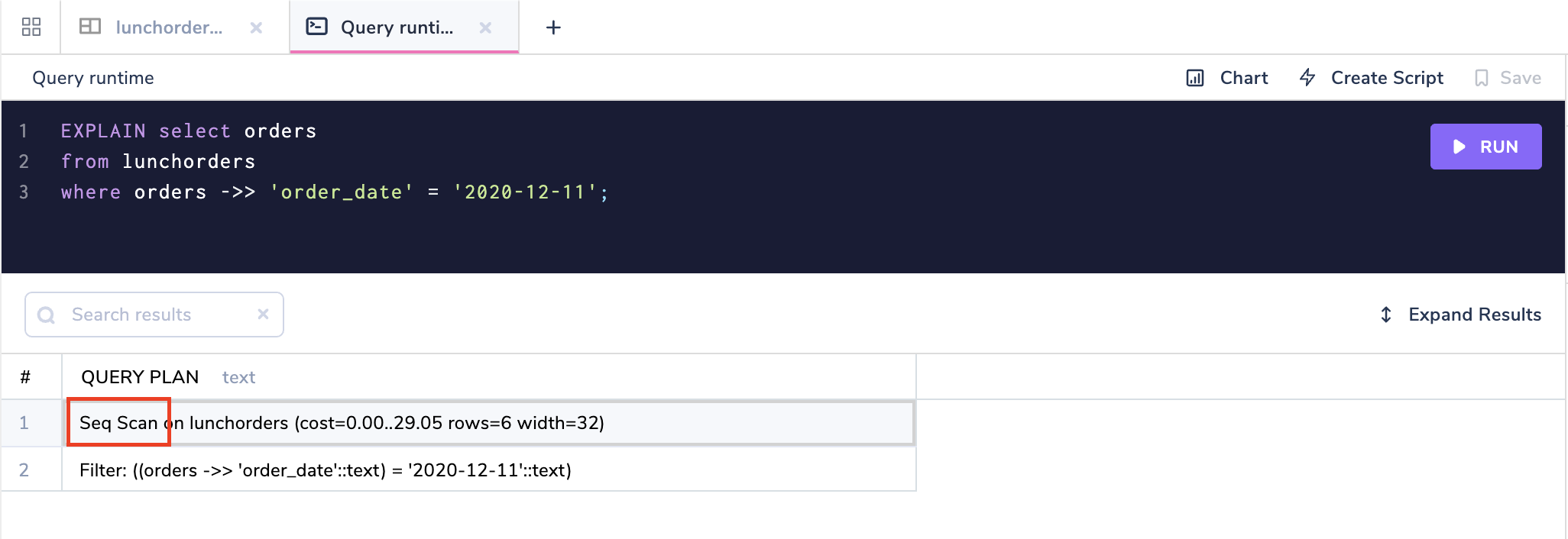
This quickly becomes inefficient as the size of the table grows.
To improve query performance, Postgres 9.4 included support for database indexes. An index is an additional data structure for structuring data so that it is easier to query.
I've created a sample table with 700K rows to demonstrate how a database index can improve query performance by 350X for JSON data.
PostgreSQL offers two types of indexes to work with JSON data.
- B-Tree index
- GIN index/Full-text search index.
B-Tree Index
books_data has 770k rows and contains a data column that stores book information in a JSONB object:
xxxxxxxxxx
select count(*)
from books_data;
xxxxxxxxxx
count
--------
772768
(1 row)
x
id -> integer
ingested_at -> timestamp
data -> jsonb
#JSONB structure example
{
"id":"6fafd0f7-c16a-4ebf-9c73-31ce8d0a2d13",
"author":"Ronald Berry",
"source":"Harrington LLC",
"content":"Agency become language price particularly act meet mission the.",
"published_at":"2020-05-07T09:29:58"
}
On the unindexed table, it takes 128ms to find every book written by Jessica Evans:
xxxxxxxxxx
explain analyze
select *
from books_data
where data ->> 'author' = 'Jessica Evans';
x
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..36481.22 rows=3864 width=279) (actual time=11.626..127.638 rows=22 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on books_data (cost=0.00..35094.82 rows=1610 width=279) (actual time=25.993..121.968 rows=7 loops=3)
Filter: ((data ->> 'author'::text) = 'Jessica Evans'::text)
Rows Removed by Filter: 257582
Planning Time: 0.087 ms
Execution Time: 127.673 ms
(8 rows)
Now let's create a B-Tree index on the author key in the JSON object using ->>:
xxxxxxxxxx
create index author_index on books_data ((data ->> 'author'));
Now we can test the query performance improvement by adding an index:
xxxxxxxxxx
explain analyze
select *
from books_data
where data ->> 'author' = 'Jessica Evans';
x
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Index Scan using author_index on books_data (cost=0.42..36.56 rows=8 width=279) (actual time=0.043..0.069 rows=22 loops=1)
Index Cond: ((data ->> 'author'::text) = 'Jessica Evans'::text)
Planning Time: 0.298 ms
Execution Time: 0.091 ms
(4 rows)
The execution time decreased from 128ms -> .091ms. That's almost 350x faster.
A B-Tree index is very performant, but it does not support full-text search and requires a new index for each key in the JSON object. Let's see how we can use a GIN Index to solve this.
GIN Index For Full-Text Search
If we try to filter for authors using the containment operator, @>, Postgres ignores our B-Tree index and reverts back to an inefficient sequential scan:
xxxxxxxxxx
explain analyze
select data
from books_data
where data @> '{"author" : "Mark Figueroa"}';
x
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..35367.14 rows=773 width=267) (actual time=128.013..141.698 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on books_data (cost=0.00..34289.84 rows=322 width=267) (actual time=107.243..135.873 rows=1 loops=3)
Filter: (data @> '{"author": "Mark Figueroa"}'::jsonb)
Rows Removed by Filter: 257588
Planning Time: 0.071 ms
Execution Time: 141.721 ms
The @ operator does not use the BTree index because it does a full-text search. We can create a GIN index to solve this:
xxxxxxxxxx
create index gin_data on books_data using gin(data);
Firing the same query again results in significant speedup:
xxxxxxxxxx
explain analyze
select data
from books_data
where data @> '{"author" : "Mark Figueroa"}';
x
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books_data (cost=49.99..2751.49 rows=773 width=267) (actual time=0.609..0.615 rows=3 loops=1)
Recheck Cond: (data @> '{"author": "Mark Figueroa"}'::jsonb)
Heap Blocks: exact=3
-> Bitmap Index Scan on gin_data (cost=0.00..49.80 rows=773 width=0) (actual time=0.596..0.596 rows=3 loops=1)
Index Cond: (data @> '{"author": "Mark Figueroa"}'::jsonb)
Planning Time: 0.087 ms
Execution Time: 0.647 ms
On top of a full-text search, a GIN index can also be used for other keys within the same JSON object:
xxxxxxxxxx
explain analyze
select data
from books_data
where data @> '{"source": "Leonard-Ross"}';
x
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on books_data (cost=49.99..2751.49 rows=773 width=267) (actual time=0.366..0.367 rows=1 loops=1)
Recheck Cond: (data @> '{"source": "Leonard-Ross"}'::jsonb)
Heap Blocks: exact=1
-> Bitmap Index Scan on gin_data (cost=0.00..49.80 rows=773 width=0) (actual time=0.348..0.348 rows=1 loops=1)
Index Cond: (data @> '{"source": "Leonard-Ross"}'::jsonb)
Planning Time: 0.088 ms
Execution Time: 0.398 ms
GIN indexes also support some JSONPath queries, but depending upon the pattern, you may need to create specific indexes similar to the B-Tree index.
Indexing is a key part of any database workflow, and there are some additional considerations for creating an efficient index.
Things to Avoid: JSON Anti-Patterns
As with everything in computer science, JSON is not a silver bullet. It adds more flexibility to the relational data model, but there are still some JSON anti-patterns to be wary of:
- Modeling relational data—JSON is not a replacement for row stores. JSON is still significantly slower than regular row-based data because of a lack of statistics. This is a known limitation if you are planning to use JSON for analytical queries, as it is simply impossible to build statistics for a schemaless architecture.
- Replacing NoSQL—JSONB is still not a replacement for NoSQL systems (Explained in detail in the following section)
- Size—JSONB content and GIN indexes take a lot more space (example below) and it is hard to table partitioning when compared to row-based data. So one should be very mindful of the data scale since PostgreSQL cannot horizontally scale like other NoSQL database systems.
- Joins—It is difficult to do normalization with one-to-many, many-to-many relationships with JSON type. JSON not meant for normalized data and doing joins is an anti-pattern and will lead to performance problems.
The books_data table occupies 236 MB,
xxxxxxxxxx
select pg_size_pretty(pg_relation_size('books_data'));
xxxxxxxxxx
pg_size_pretty
----------------
236 MB
The GIN Index created for full-text search is larger than the size of the table itself.
xxxxxxxxxx
select pg_size_pretty(pg_relation_size('gin_data'));
xxxxxxxxxx
pg_size_pretty
----------------
283 MB
Since it has to store the JSON in the inverted index format, the size is much bigger.
Now we've covered the advantages and anti-patterns with JSON in Postgres. How does it compare to traditional NoSQL databases?
JSON in Postgres vs NoSQL Databases
First, to clear any confusion, NoSQL stands for "Not Only SQL" and it does not mean that SQL is not used. In fact, many NoSQL systems, such as Apache Spark and Flink, have some sort of an interface for SQL. SQL is just a query language standard to fetch/manipulate data.
To compare database systems, we first have to cover some database theory with the CAP theorem.
CAP theorem
CAP is an acronym for:
- Consistency
- Availability
- Partition tolerance
The theorem states that it is impossible for any distributed data store to have all three properties.
- PostgreSQL is a CA system.
- Cassandra is an AP system
- Mongo DB is a CA system by default
Different databases have different goals. No matter what data type PostgreSQL offers, it will ultimately be a relational database and will sit within the CA part of the CAP theorem.
Transactions
ACID transactions by nature are typically hard to scale across multiple machines. This is the reason why replication in PostgreSQL or any relational database is done via a Write Ahead Log or WAL log.
This means a transaction is only sent across the wire after it is written to the WAL log, ensuring that there is consistency across different database instances. This is very different from Cassandra's consistency level (BASE) which scales across multiple nodes and uses something called eventual consistency.
Data Models
- Mongo DB is a document store
- Cassandra is a column family store
- PostgreSQL is a relational DB row store
At the end of the day, PostgreSQL is still a relational data model and does not have all the features of a NoSQL database such as an aggregation pipeline.
When you try to model data in PostgreSQL, the best practice is to default to a relational model and only use JSON when it makes sense.
Conclusion
In this article we've covered:
- When to use SQL vs NoSQL
- A history of JSON in Postgres
- Examples of how to work with JSON data
- JSON query performance with indexing
- JSON anti-patterns
Postgres can't replace a NoSQL database, but it can be a great solution for independent data and save you from creating a separate NoSQL database. PostgreSQL has evolved so much from its initial days, and the gaps between different database systems are getting narrower. JSON data can be difficult to manage from the command line. Download Arctype today to work with JSON in a free, modern SQL editor.

Published at DZone with permission of Derek Xiao. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments